移動環境下基于異構雙MIC的語音識別自適應系統的方法與流程
本發明公開了一種移動環境下基于異構雙MIC的語音識別自適應系統的方法,屬于語音信號處理技術領域。
背景技術:
隨著科技的進步,人機交互已經經歷了命令行、圖形界面到觸摸板的三代變革。現在,為了解放雙手操作,我們已經來到語音控制時代的入口,人機交互模式正在發生著巨大的變化。最近的消息顯示,各大科技巨頭都已經開始布局語音交互領域,業內普遍認為語音作為人類信息最自然、最便捷的交互方式,必將成為新人機交互模式的重要組成部分。
由于移動和便攜設備的使用場所十分多變,用戶有可能時常處于聲音極其嘈雜的環境下,而語音交互的完美實現則有賴于清晰的語音信息接收以及準確的語音識別能力。因此,在大數據和深度學習之外,如何在有噪聲的情況下保持良好的語音接收是工程師們面臨的一大挑戰。而語音降噪技術的發展和強化,也正在推進語音交互時代的到來。
未來的語音識別市場,預計將會有越來越多的公司參與,以后語音識別的性能可能更多的體現在前端技術和語義理解上。機器要與人自然交流,必然就要考慮到用戶說話的環境、周圍環境的噪音、用戶發音不準或者方言等等諸多因素,這就要求前端技術更加精準的模擬人體結構,仿真出機器人聽覺系統,以實現解放雙手自由對話的目的。
技術實現要素:
本發明提出了一種移動環境下基于異構雙MIC的語音識別自適應系統的方法,從語音模擬信號最前端對信號進行優化,實現語音識別自適應。與現有方法相比,即使在信噪比變化劇烈的情況下仍能得到較清晰的語音信號,對語音識別的后續工作起了很好的鋪墊作用,減輕了其應用于復雜場景的壓力,并且實現簡單,具有系統性自適應能力。
本發明為解決其技術問題采用如下技術方案:
步驟(1)結合優選通道與動態調整PA的方式,實現系統結構層的自適應調整前端狀態以提高語音識別率;
步驟(1-1)對系統進行初始化,主MIC1主要用于遠場拾音及遠近距離預測,副MIC2主要用于近場拾音及抗強干擾場景,因而動態綁定主MIC1的PA,副MIC2綁定固定PA值。
步驟(1-2)根據PA的調整需求,由主MIC1當前獲取的wav判斷下次錄音時PA的調整值。
步驟(1-3)由步驟(1-2)得出主MIC1的PA調整值,采用判決反饋的方式重置步驟(1-1)中主MIC1的PA,當前說話人的位置較遠時,增大PA,當前說話人的位置較近時,降低PA,實時更新PA值,實現系統性自適應改善錄音和識別效果。
步驟(2)終端進入錄音模式后,同時啟動主、副MIC的錄音通道,探測到有語音信號,分析緩存buffer,根據優選規則,選擇最優的錄音通道;
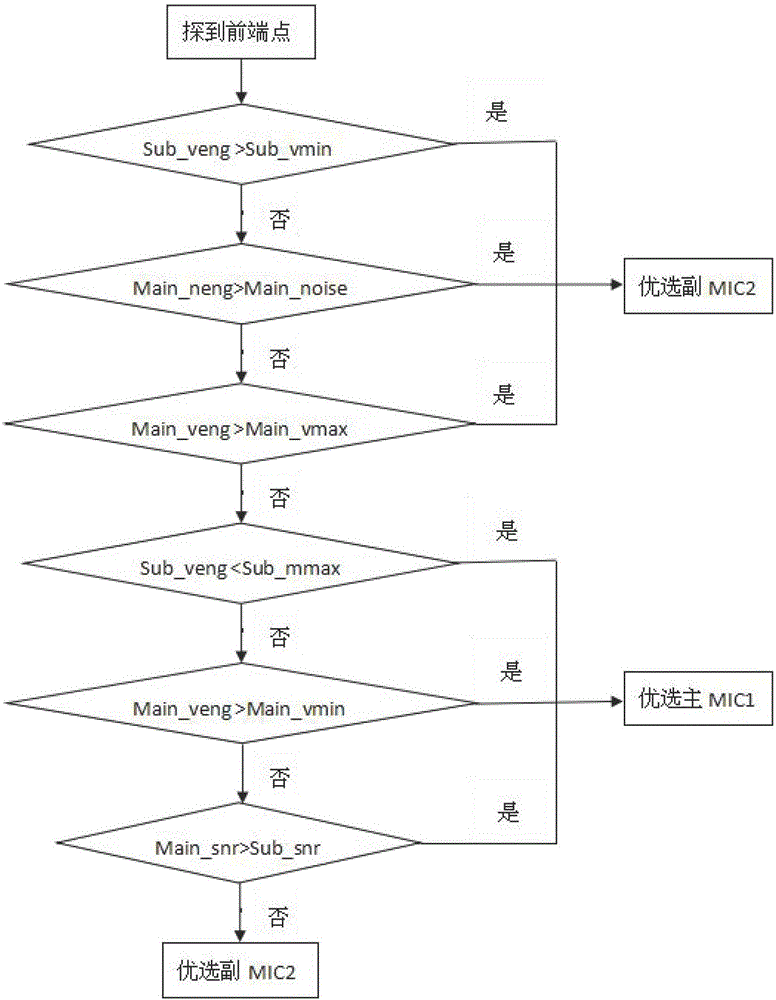
步驟(2-1)判斷主MIC1的噪聲能量是否大于預設的能量閥值Main_noise;若是,優選副MIC2錄音通道的數據。在噪聲能量閾值判斷條件下,優選副MIC2錄音通道的數據,副MIC2具有拾音距離短且拾音方向窄的特點,其音頻信息具有較大抗噪性和抗干擾性。
步驟(2-2)判斷主MIC1的語音能量Main_veng是大于預設的削波能量閥值Main_vmax或是大于預設的語音最低能量閥值Main_vmin。若大于預設的削波能量閥值Main_vmax,優選副MIC2錄音通道的數據,當主MIC1削波時,應選數據信息完好的副MIC2;若大于預設的語音最低能量閥值Main_vmin,優選主MIC1錄音通道的數據。
步驟(2-3)判斷副MIC2的語音能量Sub_veng是大于預設的語音最低能量閥值Sub_vmin或是大于預設的靜音最高能量閥值Sub_mmax。若小于預設的靜音最高能量閥值Sub_mmax,優選主MIC1錄音通道的數據,當副MIC2錄音音量較小時,可能用戶離得較遠,音量過小影響識別率,應選適應距離較大的主MIC1;若大于預設的語音最低能量閥值Sub_vmin,優選副MIC2錄音通道的數據。
步驟(2-4)計算主MIC1的信噪比和副MIC2的信噪比,優選信噪比較高的錄音通道的數據。
步驟(2-5)在相關判斷條件下,優選副MIC2錄音通道的數據。當優選主MIC1和優選副MIC2的條件同時成立時,優選副MIC2,其音頻數據具有抗噪性和抗干擾性,有益于提高識別率。
步驟(3)由步驟(2)判斷出最優錄音通道后,識別最優通道的語音數據,并保存錄音文件,無論最優通道是否為主MIC1,對其wav進行分析,判斷下次錄音時主MIC1的PA調整值;
步驟(3-1)識別最優通道的語音數據時,當判斷當前說話結束,給出識別結果,并保存wav錄音文件,對MIC1的wav分析,判斷當前說話人的位置遠近程度,主MIC1的PA調整值。
步驟(3-2)判斷主MIC1的wav中最大能量值eng_max是否大于預設的削波能量閥值eng_thresh1;若是,根據eng_max與eng_thresh1的比值,調整PA,降低主MIC1的模擬增益。
步驟(3-3)判斷主MIC1的wav中最大能量值eng_max是否小于預設的最低語音能量閥值eng_thresh2;若是,根據eng_max與eng_thresh2的比值,調整PA,增大主MIC1的模擬增益。
本發明的有益效果在于:
(1)本發明中公開的移動環境下基于異構雙MIC的語音識別自適應系統的方法,可以隨著說話人遠近距離和環境噪聲的變化,自動選擇最合適的模型進行識別,顯著提升準確率。
(2)本發明公開的從語音模擬信號最前端對信號進行優化,實現語音識別自適應的方法,對前端異構的雙MIC的架構要求較大,從原始模擬信號本身對語音和噪聲信號做了提升和抑制處理,避免了相關算法的缺陷,適用于各種應用場景。
附圖說明
圖1是本發明所述的利用異構雙MIC優選識別自適應系統的方法示意圖;
圖2為異構雙MIC的優選判斷方法流程圖;
圖3為調整PA的方法示意圖;
圖4是本發明所述移動終端的結構示意框圖。
具體實施方式
下面結合附圖對本發明作進一步闡述:
如附圖1及附圖4所示,本發明所述的移動終端包括:PA綁定模塊、優選模塊和更新模塊。初始化設定全向主MIC1和定向副MIC2的PA值,主MIC1實現動態綁定PA,副MIC2綁定固定PA值;綁定PA模塊后,進入優選模塊,首先需要設定主副MIC的優選識別規則,并當終端進入錄音模式時,同時啟動主、副MIC的錄音通道,并一直保持錄音狀態;實時檢測主副MIC是否有語音端點特征,若是,則根據優選規則,選出最優音頻通道的數據進行語音識別,直到出現語音后端點,給出識別結果;最后,進入更新模塊,根據當前主MIC1產生wav信息軟控制主MIC1硬件PA,實現主MIC1錄音通道PA的動態調整。
其中,優選規則如附圖2所示。當探測到前端點后,根據主MIC1和副MIC2的語音能量、噪聲能量、信噪比等判斷出具有更高語音清晰度和辨識度的錄音通道。
IF Main_veng>Main_noise Flag_channel=2
ELSEIF Sub_veng>Sub_vmin Flag_channel=2
ELSEIF Main_veng>Main_vmax Flag_channel=2
ELSEIF Sub_veng<Sub_mmax Flag_channel=1
ELSEIF Main_veng>Main_vmin Flag_channel=1
ELSEIF Main_snr>Sub_snr Flag_channel=1
ELSE Flag_channel=2
其中:
Main_noise表示主MIC1的噪聲能量閥值;
Main_veng表示主MIC1的語音能量值;
Main_vmax表示主MIC1的削波能量閥值;
Main_vmin表示主MIC1的語音最低能量閥值;
Sub_veng表示副MIC2的語音能量值;
Sub_vmin表示副MIC2的語音最低能量閥值;
Sub_mmax表示副MIC2的靜音最高能量閥值;
Main_snr表示主MIC1的信噪比;
Sub_snr表示副MIC2的信噪比;
Flag_channel表示優選通道,
Flag_channel=1表示優選主MIC1,
Flag_channel=2表示優選副MIC2。
由主MIC1產生的wav信息軟控制主MIC1的硬件PA,實現主MIC1錄音通道PA動態調整的方法如附圖3所示。當主MIC1產生wav,對wav分析,判斷主MIC1的PA值是否合適。若wav中最大能量值eng_max大于預設的削波能量閥值eng_thresh1,降低主MIC1的模擬增益PA,實現PA快速降低;若wav中最大能量值eng_max小于預設的最低語音能量閥值eng_thresh2,增大主MIC1的模擬增益PA,實現PA緩慢提高,當eng_max非常小時,PA將快速提高。其實現如下:
其中:
eng_max表示主MIC1的wav中最大能量值;
eng_thresh1表示主MIC1的削波能量閥值;
eng_thresh2表示主MIC1的最低語音能量閥值;
PA表示主MIC1下次錄音時的PA變化量;
step_down表示PA降低時調整的步長;
step_up表示PA增大時調整的步長。
以上所述實施例,只是本發明的較佳實例,并非來限制本發明的實施范圍,故凡依本發明申請專利范圍所述的構造、特征及原理所做的等效變化或修飾,均應包括于本發明專利申請范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!