一種語音搜索列表的實現方法與流程
本發明涉及搜索技術領域,尤其是一種語音搜索列表的實現方法。
背景技術:
現有技術中,語音識別系統在進行搜索列表時,無法將列表項的屬性關聯;或者即使關聯,但需要手工排列組合可能的發音。例如,對于第一種情況,在通訊錄里有總務科張三和人事科章山,兩個人名發音相似,如果用戶說“打電話給人事科章山”,語音識別可能會返回“打電話給人事科張三”。這里人名和部門這兩個屬性沒有關聯,導致識別出錯誤的聯系人。再例如,對于第二種情況,用戶需要在附近的飯店列表中選出“麥當勞(珠江路5000號)”和“肯德基(長江路6000號)”,需要進行排列所有可能的發音序列。比如對于第一個麥當勞,就生成如下發音序列:“麥當勞”,“珠江路麥當勞”,“珠江路5000號麥當勞”,“珠江路5000號”和“珠江路”;對于第二個肯德基,就生成如下發音序列:“肯德基”,“長江路肯德基”,“長江路6000號肯德基”,“長江路6000號”和“長江路”。這種屬性關聯方法的缺陷為不靈活,程序必須列出所有序列;運算量大,隨著列表屬性增加,可能的發音序列變得很大。綜合以上兩種情況,現有技術沒有解決好靈活性和復雜性的矛盾。
技術實現要素:
本發明所要解決的技術問題在于,提供一種語音搜索列表的實現方法,可以降低計算復雜性,同時增加了靈活性。
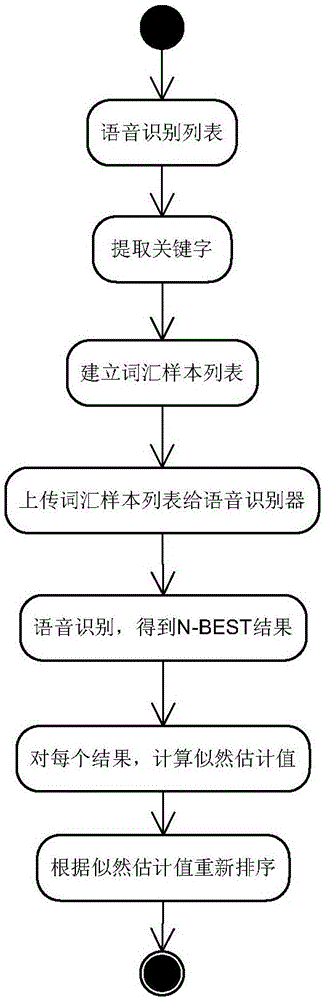
為解決上述技術問題,本發明提供一種語音搜索列表的實現方法,包括如下步驟:
(1)列表預處理:
一個列表,提取每個列表項C的所有屬性的關鍵字,切詞且去除重復,得到詞匯樣本V(v1,v2,…vn),有n個獨立的詞;
(2)語音識別
將詞匯樣本V傳送給語音識別器,并加載UNIGRAM語言模型,進行語音識別,得到N-BEST結果R,其中每個結果t為識別出的詞,w為該詞的權重;
(3)計算似然估計值
對每個列表項C,計算其歸一化的似然估計值lik(C);
lik(c)=∏reR f(c|r)
f(c|r)=∏ter g(t|c)
其中,a、b為預設的常數,c為一個列表項,r為一個語音識別結果,t為一個識別的詞,w為一個識別的詞t的權重;
(4)列表搜索;根據列表項的似然估計值重新排序,選出似然估計值最大的列表項。
優選的,步驟(1)中,詞匯樣本V必須去除重復詞匯。
優選的,步驟(2)中,語音識別器裝載詞匯樣本V和UNIGRAM語言模型,識別輸入語音數據并輸出N-BEST結果。
優選的,步驟(2)中,語音識別器加載的UNIGRAM語言模型是動態生成的,而UNIGRAM語法是固定的,不依賴于列表而變化,每種語言只需有一個UNIGRAM語法。
優選的,步驟(2)中,語音識別器為嵌入式語音識別器或任何支持N-BEST結果的語音識別器。
優選的,步驟(2)中,權重為概率或信任值。
優選的,步驟(2)中,詞匯樣本V中可以增加常用連接詞和介詞。
優選的,步驟(3)中,計算似然估計值基于樸素貝葉斯概率模型,并且使用了所有N-BEST結果。
優選的,步驟(3)中,a、b為預設的常數,根據試驗數據來設置。
優選的,步驟(3)中,計算似然估計值方法與語音識別器無關。
本發明的有益效果為:很好的解決了語音搜索列表的靈活性和復雜性的矛盾,降低了計算復雜性,同時增加了靈活性。
附圖說明
圖1是本發明的方法流程示意圖。
圖2是本發明的語音識別流程示意圖。
圖3是本發明的已獲取N-BEST結果后的實現方法流程示意圖。
具體實施方式
如圖1和圖2所示,一種語音搜索列表的實現方法,包括如下步驟:
(1)列表預處理:
一個列表,提取每個列表項C的所有屬性的關鍵字,切詞且去除重復,得到詞匯樣本V(v1,v2,…vn),有n個獨立的詞;
(2)語音識別
將詞匯樣本V傳送給語音識別器,進行語音識別,得到N-BEST結果R,其中每個結果t為識別出的詞,w為該詞的權重;權重為概率或信任值等;N-BEST為一種搜索算法,結果為N個最優路徑;
(3)計算似然估計值
對每個列表項C,計算其歸一化的似然估計值lik(C);
lik(c)=∏reR f(c|r)
f(c|r)=∏ter g(t|c)
其中,a、b為預設的常數,c為一個列表項,r為一個語音識別結果,t為一個識別的詞,w為一個識別的詞t的權重;
(4)列表搜索;根據列表項的似然估計值重新排序,選出似然估計值最大的列表項。
如圖3所示,為已獲取N-BEST結果后的實現方法流程示意圖。依次取下一個列表項c,初始化似然估計值lik(c)=1,取下一個N-BEST結果r,取下一個詞t;若r包含t,則lik(c)=lik(c)*wt*a;若r不包含t,則lik(c)=lik(c)*wt*b;獲得似然估計值lik(c);若還有未取詞,則繼續取詞重復上述步驟;若還有未取的N-BEST結果,則繼續取下一個N-BEST結果,重復上述步驟。
以用戶需要在列表中使用語音選擇一個快餐店為例。用戶需要在列表
[{“id”:0,“name”:”麥當勞”,“address”:”珠江路5000號”,“phone”:“555-12345678”},
{“id”:1,“name”:”肯德基”,“address”:”長江路6000號”,“phone”:“555-87654321”}]中使用語音選擇一個快餐店,具體步驟如下:
(1)提取關鍵字,得到列表[“麥當勞”,“珠江路5000號”,“555-12345678”,“肯德基”,“長江路6000號”,“555-87654321”];
(2)切詞,并且除去重復,得到詞匯樣本列表V=[“麥當勞”,“珠江路”,“5000號”,“555-12345678”,“12345678”“肯德基”,“長江路”,“6000號”,“555-87654321”,“87654321”];
(3)將此詞匯樣本V傳給語音識別器,每個語音識別器都有特定的方法;
(4)語音識別,假設用戶說“珠江路麥當勞”,得到N-BEST結果R=
{{“珠江路”:0.9,“麥當勞”:0.8},
{{“珠江路”:0.8,“麥當勞”:0.6,“6000號”:0.2},
{“珠江路”:0.7,“肯德基”:0.2,“6000號”:0.1}}
(5)計算似然估計值,假設(a=0.5,b=0.1)
麥當勞的似然估計值lik(0)=(0.5*0.9)*(0.5*0.8)*(0.5*0.8)*(0.5*0.6)*(0.1*0.2)*(0.5*0.7)*(0.1*.0.2)*(0.1*0.1)=3e-8
肯德基的似然估計值lik(1)=(0.1*0.9)*(0.1*0.8)*(0.1*0.8)*(0.1*0.6)*(0.5*0.2)*(0.1*0.7)*(0.5*0.2)*(0.5*0.1)=1e-9;
(6)重新排序,選出似然估計值最大的列表項“麥當勞”,因為麥當勞的似然估計值大于肯德基的似然估計值。
盡管本發明就優選實施方式進行了示意和描述,但本領域的技術人員應當理解,只要不超出本發明的權利要求所限定的范圍,可以對本發明進行各種變化和修改。
- 還沒有人留言評論。精彩留言會獲得點贊!