一種說話人確認方法及裝置與流程
本發明涉及語音識別領域,更具體地,涉及一種說話人確認方法及裝置。
背景技術:
說話人確認是通過聲音特征對說話人進行身份驗證的方法。在進行說話人確認時,用戶先預留一段聲音,然后輸入驗證語音。將驗證語音與系統預留語音進行對比,即可判斷該用戶是否存在。
目前,說話人確認方法以統計模型為主,性能較好的說話人確認方法一般基于i-vector模型和plda模型。i-vector模型對語音信號建立如下線性模型:
x=tw+v
其中,x為語音信號的mfcc特征,t為一個低秩矩陣,w為句子向量,即i-vector,v為高斯噪聲。該模型事實上是一個概率pca模型。實際應用中,一般將語音空間分成若干區域,對每個區域進行上述線性建模。所有區域共享句子向量w。w是一個低維向量,包含說話人、說話內容、信道等信息。為提高對說話人的區分性,引入plda模型:
w=hu+kc+n
其中u為說話人向量,c為表達向量,包括發音方式,信道等,n為高斯噪聲。plda將說話人特征和表達特征區分開。
上述模型基于通用的mfcc特征,通過模型將說話人信息分離出來。該方法基于信號的分布狀態建模,因此需要較多的數據才能得到較好的結果,而且計算量較大,且容易受到信道、噪聲和時變的影響。
技術實現要素:
為克服上述需要數據多、計算量大且魯棒性差的問題或者至少部分地解決上述問題,本發明提供一種說話人確認方法及裝置。
根據本發明的一個方面,提供一種說話人確認方法,包括:
獲取第二語音;
將預先獲取的第一語音和所述第二語音轉換成對應的第一聲譜圖和第二聲譜圖;
使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取,獲取對應的第一特征和第二特征;
使用時延神經網絡對所述第一特征和所述第二特征進行特征提取,獲取對應的第三特征和第四特征;
根據所述第三特征和所述第四特征對說話人進行確認。
具體地,在使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取之前,還包括:
對所述卷積神經網絡和所述時延神經網絡進行訓練。
具體地,在使用時延神經網絡對所述第一特征和所述第二特征進行特征提取之前,還包括:
對所述第一特征和所述第二特征進行降維。
具體地,所述使用時延神經網絡對所述第一特征和所述第二特征進行特征提取,獲取對應的第三特征和第四特征,包括:
分別對所述第一語音和所述第二語音中的幀進行拼接;
對所述第一語音中拼接后的幀對應的所述第一特征和所述第二語音中拼接后的幀對應的所述第二特征進行降維;
對降維后的所述第一特征和第二特征進行線性變換,獲取對應的第三特征和第四特征。
具體地,對所述卷積神經網絡和所述時延神經網絡進行訓練,包括:
使用交叉熵函數作為目標函數對所述卷積神經網絡和所述時延神經網絡進行訓練。
根據本發明的另一個方面,提供一種說話人確認裝置,包括:
獲取單元,用于獲取第二語音;
轉換單元,用于將預先獲取的第一語音和所述第二語音轉換成對應的第一聲譜圖和第二聲譜圖;
第一提取單元,用于使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取,獲取對應的第一特征和第二特征;
第二提取單元,用于使用時延神經網絡對所述第一特征和所述第二特征進行特征提取,獲取對應的第三特征和第四特征;
確認單元,用于根據所述第三特征和所述第四特征對說話人進行確認。
具體地,還包括:
訓練單元,用于對所述卷積神經網絡和所述時延神經網絡進行訓練。
具體地,還包括:
第一降維單元,用于對所述第一特征和所述第二特征進行降維。
具體地,所述第二提取單元包括:
拼接子單元,用于分別對所述第一語音和所述第二語音中的幀進行拼接;
第二降維子單元,用于對所述第一語音中拼接后的幀對應的所述第一特征和所述第二語音中拼接后的幀對應的所述第二特征進行降維;
變換子單元,用于對降維后的所述第一特征和第二特征進行線性變換,獲取對應的第三特征和第四特征。
具體地,所述訓練單元具體用于:
使用交叉熵函數作為目標函數對所述卷積神經網絡和所述時延神經網絡進行訓練。
本發明提出一種說話人確認方法及裝置,通過將卷積神經網絡和時延神經網絡相結合,對所述第一語音和所述第二語音進行兩次特征提取,將最終提取的第三特征和所述第四特征進行比較,從而實現對說話人的確認,本發明計算簡單,魯棒性強,能達到很好的識別效果。
附圖說明
圖1為本發明實施例提供的說話人確認方法流程圖;
圖2為所述卷積神經網絡和所述時延神經網絡模型結構圖;
圖3為本發明實施例提供的說話人確認裝置結構圖;
圖4為本發明又一實施例提供的說話人確認裝置結構圖;
圖5為本發明又一實施例提供的說話人確認裝置結構圖;
圖6為本發明又一實施例提供的說話人確認裝置結構圖。
具體實施方式
下面結合附圖和實施例,對本發明的具體實施方式作進一步詳細描述。以下實施例用于說明本發明,但不用來限制本發明的范圍。
圖1為本發明實施例提供的說話人確認方法流程圖,包括:s1,獲取第二語音;s2,將預先獲取的第一語音和所述第二語音轉換成對應的第一聲譜圖和第二聲譜圖;s3,使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取,獲取對應的第一特征和第二特征;s4,使用時延神經網絡對所述第一特征和所述第二特征進行特征提取,獲取對應的第三特征和第四特征;s5,根據所述第三特征和所述第四特征對說話人進行確認。
具體地,s1中,獲取所述第二語音,所述第二語音為說話人新錄入的語音,是需要驗證的語音。s2中,所述第一語音為說話人預先錄入的語音,每一條第一語音對應有一個說話人標簽,根據所述說話人標簽能唯一確認說話人。所述第一語音可以包括多個說話人的語音,每個說話人可以對應有一條或多條第一語音。將所有的所述第一語音轉換成第一聲譜圖,將所述第二語音轉換成第二聲譜圖。所述第一聲譜圖和所述第二聲譜圖的橫軸表示時間,縱軸表示頻率,顏色或亮度表示幅度。
s3中,使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取。所述卷積網絡可以包括多個卷積層。每個卷積層的卷積核的個數和大小可以根據需要進行調整。在使用每個卷積核對所述第一聲譜圖和所述第二聲譜圖進行卷積時,都會生成一個特征平面。每個卷積層后可以接一個池化層。所述池化層可以為最大池化層或平均池化層。所述池化層的窗口可以重疊,也可以不重疊。所述池化層的窗口大小可以根據需要進行調整。可以使用低階矩陣對第二個所述池化層得到的特征平面進行降維,但不限于此種降維方式。
s4中,所述時延網絡可以包括多個時延層,每個時延層分別對所述第一語音和所述第二語音中的幀進行拼接,并對所述第一語音中拼接后的幀對應的所述第一特征和所述第二語音中拼接后的幀對應的所述第二特征進行降維。本發明不限于降維的方法。然后對降維后的所述第一特征和第二特征進行線性變換,獲取對應的第三特征和第四特征。由于所述第一特征和所述第二特征也為聲譜圖,聲譜圖的橫坐標表示時間,所述第一語音和所述第二語音中的每一幀也有對應的時間。因此,所述第一語音中拼接后的幀對應的所述第一特征為所述第一語音中從拼接后的幀中的第一幀到最后一幀時間段內的第一特征,所述第二語音中拼接后的幀對應的所述第二特征為所述第二語音中從拼接后的幀中的第一幀到最后一幀時間段內的第二特征。
s5中,將所述驗證語音通過所述神經網絡進行前向計算,提取所述第一語音和所述第二語音中每一幀的特征。可以根據每一幀的特征使用任何統計模型對說話人進行確認。如分別計算所述第一語音和所述第二語音中每一幀的特征的平均值,計算所述第二語音中每一幀的特征的平均值和每條所述第一語音中每一幀的平均值之間的距離。所述距離可以為余弦相似度。但不限于此種距離。當計算出的余弦相似度大于預設閾值時,則根據所述第一語音對應的說話人標簽確認當前說話人。
本實施例通過將卷積神經網絡和時延神經網絡相結合,對所述第一語音和所述第二語音進行兩次特征提取,將最終提取的第三特征和所述第四特征進行比較,從而實現對說話人的確認,本發明計算簡單,魯棒性強,能達到很好的識別效果。
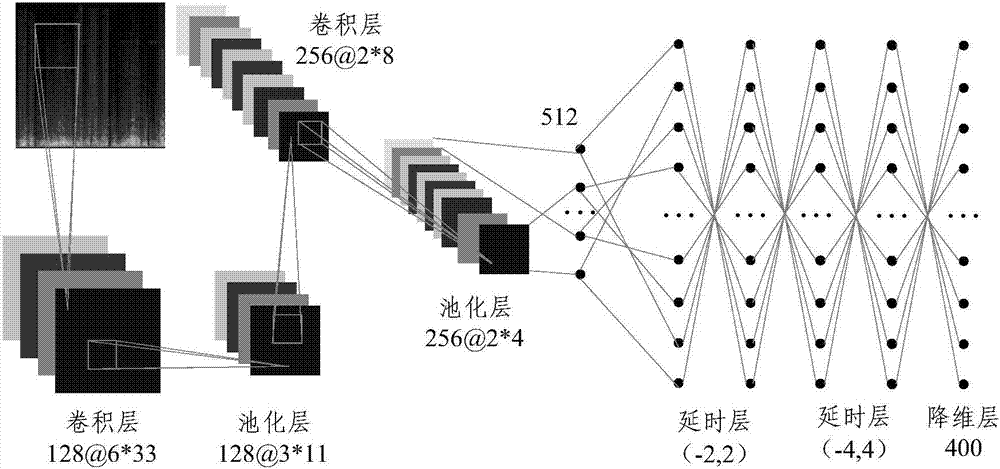
圖2為所述卷積神經網絡和所述卷積神經網絡的結構圖,如圖2所示,所示卷積神經網絡的輸入為頻譜圖。所述卷積神經網絡有兩個卷積層,第一個卷積層的卷積核為128個,每個卷積核的大小為6x33;第一個池化層的池化窗口大小為3x11。第二個卷積層的卷積核為256個,每個卷積核的大小為2x8。第二個池化層的池化窗口大小為2x4。對第二個池化層得到的256個特征平面進行降維,降維成512個特征,對應512個神經元。所述時延網絡有兩個時延層,每個時延層通過時序拼接對上下文信息進行擴展。第一個時延層拼接前后各2幀信號,第二個時延層拼接前后各4幀信號。每個時延層后接一個降維層。每個降維層將延時層進行降維,輸出400個特征。對所述第二個時延層的降維層的輸出的400個特征進行線性變換。
在上述實施例的基礎上,本實施中在使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取之前,還包括對所述卷積神經網絡和所述時延神經網絡進行訓練。
具體地,在訓練前,獲取需要確認的說話人的語音,將需要確認的說話人的語音作為訓練集。在進行訓練時,將所述語音中的每一個幀作為學習樣本,經過所述卷積神經網絡和所述卷積神經網絡兩次特征提取后,計算所述兩次特征提取前后該幀的特征之間的距離,確認該幀的說話人是否為該幀對應的說話人標簽,使用說話人確認的誤差信息反向調整所述卷積神經網絡和所述卷積神經網絡中的參數。目標函數為交叉熵函數。訓練時使用的后向反饋算法可以為nsgd(naturalstochasticgradientdescent,自然隨機梯度下降)算法或任何深度神經網絡訓練方法。
本實施例中,使用語音中的每一個幀作為學習樣本對所述卷積神經網絡和所述卷積神經網絡進行訓練,調整所述卷積神經網絡和所述卷積神經網絡中的參數,該種訓練方法需要的數據少,使用優化的參數能提高說話人確認的準確性。
圖3為本發明實施例提供的說話人確認裝置結構圖,如圖3所示,包括獲取單元1、轉換單元2、第一提取單元3、第二提取單元4和確認單元5,其中:
所述獲取單元1用于獲取第二語音;所述轉換單元2用于將預先獲取的第一語音和所述第二語音轉換成對應的第一聲譜圖和第二聲譜圖;所述第一提取單元3用于使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取,獲取對應的第一特征和第二特征;所述第二提取單元4用于使用時延神經網絡對所述第一特征和所述第二特征進行特征提取,獲取對應的第三特征和第四特征;所述確認單元5用于根據所述第三特征和所述第四特征對說話人進行確認。
具體地,所述獲取單元1獲取所述第二語音。所述第二語音為說話人新錄入的語音,是需要驗證的語音。所述轉換單元2將所有的所述第一語音轉換成第一聲譜圖,將所述第二語音轉換成第二聲譜圖。所述第一語音為說話人預先錄入的語音,每一條第一語音對應有一個說話人標簽,根據所述說話人標簽能唯一確認說話人。所述第一語音可以包括多個說話人的語音,每個說話人可以對應有一條或多條第一語音。所述第一聲譜圖和所述第二聲譜圖的橫軸表示時間,縱軸表示頻率,顏色或亮度表示幅度。
所述第一提取單元3使用卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取。所述卷積網絡可以包括多個卷積層。每個卷積層的卷積核的個數和大小可以根據需要進行調整。在使用每個卷積核對所述第一聲譜圖和所述第二聲譜圖進行卷積時,都會生成一個特征平面。每個卷積層后可以接一個池化層。所述池化層可以為最大池化層或平均池化層。所述池化層的窗口可以重疊,也可以不重疊。所述池化層的窗口大小可以根據需要進行調整。
所述時延網絡可以包括多個時延層,所述時延網絡包括多個全連接的時延層,每個時延層中的所述第二提取單元4通過拼接前后各幀對上下文信息進行擴展。拼接前后各幀的數目可以根據需要進行設置。
所述確認單元5將所述驗證語音通過所述神經網絡進行前向計算,提取所述第一語音和所述第二語音中每一幀的特征。可以根據每一幀的特征使用任何統計模型對說話人進行確認。如分別計算所述第一語音和所述第二語音中每一幀的特征的平均值,計算所述第二語音中每一幀的特征的平均值和每條所述第一語音中每一幀的平均值之間的距離。所述距離可以為余弦相似度。但不限于此種距離。當計算出的余弦相似度大于預設閾值時,則根據所述第一語音對應的說話人標簽確認當前說話人。
本實施例通過將卷積神經網絡和時延神經網絡相結合,對所述第一語音和所述第二語音進行兩次特征提取,將最終提取的第三特征和所述第四特征進行比較,從而實現對說話人的確認,本發明計算簡單,魯棒性強,能達到很好的識別效果。
圖4為本發明實施例提供的說話人確認裝置結構圖,如圖4所示,在上述實施例的基礎上,還包括:訓練單元6,用于對所述卷積神經網絡和所述時延神經網絡進行訓練。
具體地,在訓練前,獲取需要確認的說話人的語音,將需要確認的說話人的語音作為訓練集。在進行訓練時,所述訓練單元6,將所述語音中的每一個幀作為學習樣本,經過所述卷積神經網絡和所述卷積神經網絡兩次特征提取后,計算所述兩次特征提取前后該幀的特征之間的距離,確認該幀的說話人是否為該幀對應的說話人標簽,使用說話人確認的誤差信息反向調整所述卷積神經網絡和所述卷積神經網絡中的參數。目標函數為交叉熵函數。訓練時使用的后向反饋算法可以為nsgd(naturalstochasticgradientdescent,自然隨機梯度下降)算法或任何深度神經網絡訓練方法。
本實施例中,使用語音中的每一個幀作為學習樣本對所述卷積神經網絡和所述卷積神經網絡進行訓練,調整所述卷積神經網絡和所述卷積神經網絡中的參數,該種訓練方法需要的數據少,使用優化的參數能提高說話人確認的準確性。
圖5為本發明實施例提供的說話人確認裝置結構圖,如圖5所示,在上述各實施例的基礎上,還包括:第一降維子單元7,用于對所述第一特征和所述第二特征進行降維。
具體地,使用所述卷積神經網絡對所述第一聲譜圖和所述第二聲譜圖進行特征提取時,每個卷積核生成一張特征平面。當卷積核的數量很多時,會生成很多張特征平面,每張平面上有很多特征,雖然每個卷積層后接一個池化層,但特征數量依然很多,會大大降低計算速度。所以需要對所述卷積神經網絡提取的所述第一特征或所述第二特征進行降維。可以使用低階矩陣進行降維,本實施例不限于降維的方法。本實施例通過對所述第一特征和所述第二特征進行降維,大大提高了計算速度。
圖6為本發明實施例提供的說話人確認裝置結構圖,如圖6所示,在上述各實施例的基礎上,所述第二提取單元4包括拼接子單元41、第二降維子單元42和變換子單元43,其中:
所述拼接子單元41用于分別對所述第一語音和所述第二語音中的幀進行拼接;所述第二降子維單元42用于對所述第一語音中拼接后的幀對應的所述第一特征和所述第二語音中拼接后的幀對應的所述第二特征進行降維;所述變換子單元43用于對降維后的所述第一特征和第二特征進行線性變換,獲取對應的第三特征和第四特征。
具體地,每個延時層中所述拼接子單元41拼接的幀的數目相同,不同延時層中所述拼接子單元41拼接的幀的數目可以不同。拼接窗口可以重疊。所述第二降維子單元42對每個時延層中拼接的幀對應的特征平面進行降維。由于所述第一特征和所述第二特征也為聲譜圖,聲譜圖的橫坐標表示時間,所述第一語音和所述第二語音中的每一幀也有對應的時間。因此,所述第一語音中拼接后的幀對應的所述第一特征為所述第一語音中從拼接后的幀中的第一幀到最后一幀時間段內的第一特征,所述第二語音中拼接后的幀對應的所述第二特征為所述第二語音中從拼接后的幀中的第一幀到最后一幀時間段內的第二特征。可以對所述第一特征和所述第二特征上的平移窗口中的特征取平均值,用一個特征值為所述平均值的特征替代所述平移窗口中的特征,從而實現降維。本發明不限于對所述特征平面進行降維的方法。所述變換子單元43對降維后的特征進行線性變換。可以用邏輯斯蒂回歸模型進行線性變換。
本發明實施例使用時延神經網絡對所述第一特征和所述第二特征進行特征提取,獲取對應的第三特征和第四特征,所述時延神經網絡對特征具有較強的提取能力,為說話人的準確確認奠定基礎。
最后,本申請的方法僅為較佳的實施方案,并非用于限定本發明的保護范圍。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!