一種面向并行批處理機動態調度的快速評估方法與流程
本發明屬于半導體生產調度與控制
技術領域:
,涉及一種用于半導體生產線過程中并行批處理機動態調度的快速評估方法。
背景技術:
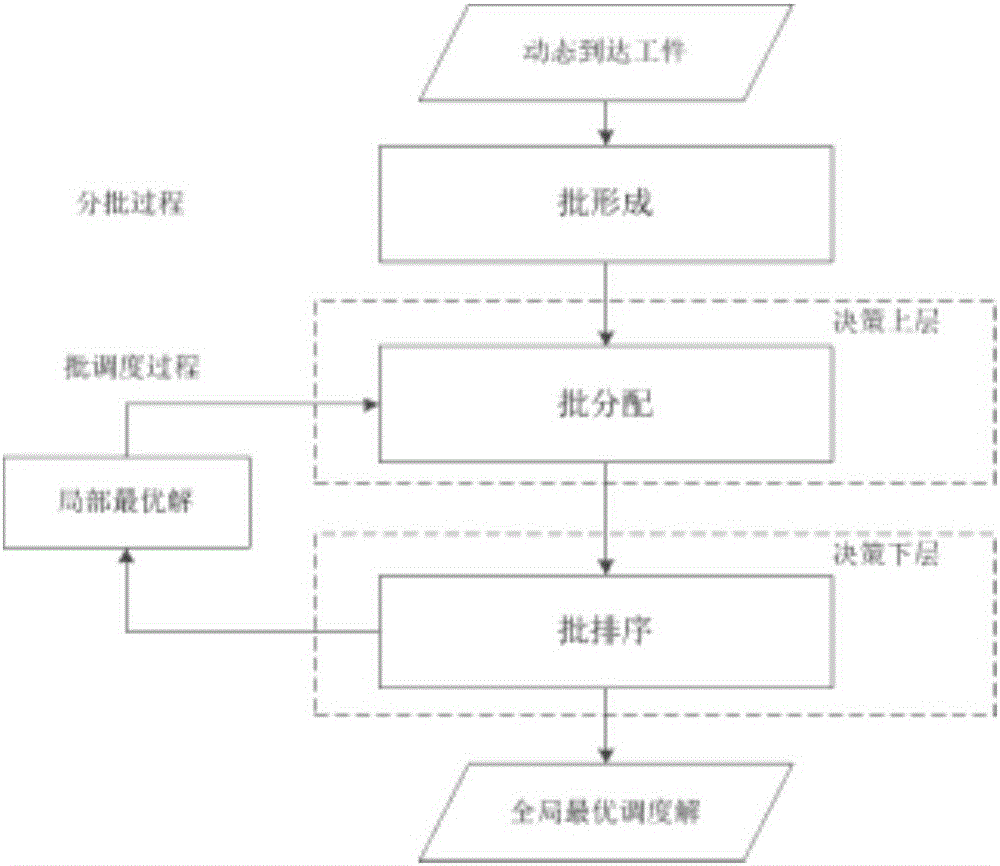
:近年來由于復雜半導體制造系統市場產品定制化需求,呈現多品種、小批量生產的特點。批處理機普遍存在于晶圓制造環節中的擴散區和氧化區,同時由于批量加工消耗時間長,常常成為制約整個系統性能的瓶頸工序。因此,實際生產中有效而快速地給出調度決策方案,將會提升系統性能并擴大產能。根據分解思想將復雜大規模問題劃分為若干容易解決的子問題,但這些處在不同層次的子問題之間存在著強耦合關系,通常上層決策作為下層決策的基礎,反過來下層最優決策指導上層決策不斷調整。利用進化算法搜索最優調度解的過程中,由于消耗時間長且容易收斂“早熟”而不能簡單地嵌套使用。為了加快搜索進程,采用代理模型技術估計評價大部分解的性能指標,代替費時的真實評價過程,這樣采用粗評價與精準評價相結合的方式,促進了進化算法快速決策調度方案在實際生產中的應用。基于模型簡化思想,Tsung-CheChiang在2013年發表的一篇綜述性文章“Enhancingrule-basedschedulinginwaferfabricationfacilitiesbyevolutionaryalgorithms:Reviewandopportunity”中提出了幾種調度模型簡化求解方式。一種為通過識別機器或階段的瓶頸指標,減少其在仿真模型的數量,從而達到縮短仿真時間的目的;另一種為通過構建計算代價小的代理模型,取代真實耗時的仿真模型,簡化調度性能評價過程。本發明便是沿著后者的思路,從改進調度方案求解方法的角度,在保證較高的解質量前提下,大大降低了進化算法評價環節的計算代價。運用進化算法獲取復雜半導體制造系統最優調度方案中存在如下問題:(1)進化算法搜索過程中需要大量的適應值評價,計算代價大的問題往往成為制約進化算法充分搜索的瓶頸,考慮降低評價復雜度或減少評價次數。(2)由于分層遞階調度子問題存在相互影響的耦合關系,直接嵌套使用進化算法會造成時間上的不可行性。本發明重點在于處有效地處理評價模型復雜度與時間合理性之間的平衡關系。技術實現要素:本發明公開一種半導體制造系統中并行批處理機動態調度的快速評估方法。首先基于復雜問題分解思想將批處理機調度問題分成為批形成和批調度兩階段子問題分別進行求解;其次動態到達工件根據設計的優先級規則確定其加工緊急程度并完成組批之后,采用基于一種新編碼機制的共生演化算法迭代搜索上層批工件分配到并行機的方案,同時確定下層每臺加工機器上的最優排序。再次,根據提取的關鍵調度特征值,離線訓練具有預估能力的代理模型,利用預測估計值快速評價下層子問題的調度性能,指導上層子問題不斷優化調整。最后,采用估計評價與真實重評價相結合的策略,在線更新代理模型,保持預測精度,實現合理時間范圍內機器分配與批工件排序同步優化的目的。利用本發明能夠快速有效地獲取解質量良好的批處理機調度方案,不僅降低了拖期時間指標,而且提高了半導體生產線的整體性能。為了達到上述目的,本發明采用了以下技術方案。一種用于半導體生產線中動態批調度方案的快速評估方法,其特征在于,該方法包含以下步驟:步驟1確定組批方案;步驟2設計批調度編解碼方案;步驟3共生演化計算操作;步驟4適應值快速評價;上述方法中各個步驟的詳細操作過程如下:步驟1,確定組批方案。對于屬于不同類型fj,到達加工設備緩沖區時間rj的加工工件,采用基于ATC規則的滾動窗策略(t,t+T)動態地計算時間窗口內未被安排組批工件的加工優先級。T為滾動時間窗口固定時間間隔。在設備空閑的決策t時刻,確定工件是否立即進行組批的緊急程度,即優先級Ij(t)。式中,wj為訂單客戶權重系數,pj為工件j的加工時間,dj為工件j的拖期時間,rj為工件的釋放時間,μ為前瞻系數,為平均加工時間。Ij(t)為每個工件j在決策t時刻,通過上述公式計算得到的優先級,優先級高的工件率先進入組批流程,依據以下原則形成滿批或部分批工件。步驟2,設計批調度編解碼方案。解的編碼構造表示為批工件分配到各臺設備上的情況。為維持負載平衡,需控制每臺設備上所分配的批工件數量基本保持相同。對于生產線上具有n個工件,m臺加工設備,使用式(3)確定分隔區間,劃分哪些工件屬于其對應設備,屬于編碼區間內的批工件將派送到對應機器設備Mj上,結果僅為分配情況,并不代表最終加工順序。式(3)中P0為劃分起始點,后一個劃分點Pi+1在前一個Pi基礎上計算得到。共生演化算法的初始種群根據式子pop=rand(1,batchnum)(ub-lb)+lb隨機產生,其中,batchnum為批工件數量;ub和lb為實數范圍上限和下限。實數編碼不能直接應用于離散優化問題,需進行映射變換為離散值。對于一個調度解X=[x1,x2,…,xn],其中xi為隨機值。首先按照降序排列標定位置順序其中為xi按降序排列后序列標號。而最終的批工件加工順序將由式(4)得出:式(4)中為工件對應的機器編號,θ取值為[1,batchnum]不重復的整數值。步驟3,共生演化計算操作。共生演化算法模仿自然界生物之間的交互關系,包含了三個階段:互惠、共棲和寄生。該算法具有控制參數少,收斂速度快的優點。下面分別闡述不同階段的具體操作過程:步驟3.1,互惠階段。此階段為個體雙方互為所用,互得其利。隨機從種群中選擇兩個體xi和xj,根據式(5)、(6)操作得到新個體。xinew=xi+rand(0,1)×(xbest-Mv×Bf1)(5)xjnew=xj+rand(0,1)×(xbest-Mv×Bf1)(6)式中,Mv=(xi+xj)/2為兩個體之間的交互向量,xbest為當前最優個體。Bf1和Bf2為收益系數,一般設置為1或者2。步驟3.2,共棲階段。此階段為個體一方獲利,個體的另一方從交互關系中既不獲利也不受害。xinew=xi+rand(0,1)×(xbest-xj)(7)步驟3.3,寄生階段。此階段為個體一方以犧牲另一方代價獲得生存空間。采用貪婪策略,隨機選擇個體xi,如果適應度值優于個體xj,則將其替代。保持生物種群的優越性。步驟4,適應值快速評價。利用代理模型計算代價小的優點,降低每次評價的復雜度,加快其搜索進程,將預測估計值取代昂貴的真實評價值。運用代理模型到實際應用應該包含模型的建立,訓練數據的準備,模型的選取,適應值預估及重評價,以及模型在線更新等若干步驟。步驟4.1,代理模型構建。代理模型基于提取的關鍵調度特征而建立,為了確保模型估計的準確性,所選特征應能夠反映此時生產線調度的狀態信息,其中包括工件等待時間、加權加工時間、等待工件數量、拖期工件數目、候選工件拖期等。代理模型訓練過程基于歷史數據D={Xi,yi}進行有監督式學習,其中Xi為特征集合,yi為對應調度性能目標值。隨機采樣遵循拉丁方實驗設計方案,每個解xi由n個值組成,隨機從分布在區間(0,1/n),(1/n,2/n),…,(1-1/n,1)之中采樣本點。依據問題規模大小生成不同數量的訓練數據集。步驟4.2,代理模型選擇。代理模型按方法可分類成基于距離,機器學習和統計學習方法,可以采取神經網絡、支持向量機,多元線性回歸等預測技術。評價模型的好壞可依據下面兩個準則:(1)相對誤差(2)決定系數相對誤差e(x)反映了預測值與真實值之間的差異,值越小越好;決定系數R2表明模型是否具有良好的擬合能力,其值越接近1越好。如果e(x)≤5%并且R2≥0.8說明構建的代理模型可以與進化算法進行結合。最終選擇效果最好的預測模型作為代理模型。步驟4.3,適應值預估與重評價。在每次選擇階段中,所選代理模型根據解的特征進行適應值評估工作,并與舊解比較。為了防止代理模型預測誤差導致搜索方向的錯誤,每次迭代循環后對若干個最優估計解進行重新地真實評價,確定當前最優解并更新。重評價過程如下:步驟4.3.1,從當前種群中,選擇估計評價值前三位調度解個體{x1,x2,x3}.步驟4.3.2,比較所選估計解與歷史最優解大小。若所選估計解之中存在優于歷史最優解fglobal的情況,則重新真實評價后再比較;否則直接跳到下一代循環中。步驟4.3.3,如果局部最優解的性能優于全局最優解,將作為新的全局最優解,應用于之后迭代中。記錄最優解及其最優值。步驟4.4,代理模型在線更新。隨著迭代不斷進行,代理模型需要在線更新保持優秀的預估能力。每代選擇前10%優秀個體組成候選解集合,然后每隔10代更新一次種群,并且基于新種群在線更新模型。附圖說明圖1為并行批處理機調度工作流程圖;圖2為并行批處理機調度分解求解框架;圖3為組批策略流程圖;圖4為解的編碼結構示意圖;圖5為批處理機調度整體方案求解算法流程圖;圖6為真實值-預測值對比圖;圖7為幾種不同對比算法收斂圖;具體實施方式下面內容結合附圖對本發明進行詳細闡述。1.問題模型參數設定;1.1.生產線基本信息屬性:工件類型f;工件數量n;設備數量m,批最大容量B。1.2.工件動態特征屬性:工件到達緊密程度控制參數η;工件加工處理時間p,工件拖期時間d;工件權重w。具體仿真實驗中,參數設置見下表所示:2.代理模型建立與選擇;2.1我們根據問題規模采用拉丁方采樣方式隨機采樣了400組訓練數據,用于建立模型。當訓練數據獲得之后,采用交叉驗證的方法將數據均勻隨機分成5份,將其中1份作為測試數據,其余作為訓練數據來訓練模型。這樣依次將5份分別作為測試數據重復上述過程,最后將平均性能結果返回作為模型的最終評判標準。2.2本發明中選擇支持向量回歸機,徑向基神經網絡和多元線性回歸作為代理模型的候選集合。經過獨立運行20次訓練后得到幾種模型的平均性能如下表所示;訓練數據和測試數據的預測值與真實值的對比結果如圖6所示:2.3從表中模型判別準則可以看出幾種模型均符合作為代理模型的條件,而其中支持向量機性能更加優越,因此被選擇為本發明問題的代理模型,適用于評估適應值大小。模型判別準則支持向量回歸機徑向基神經網絡多元線性回歸訓練相對誤差2.2%2.87%2.83%測試相對誤差2.64%2.92%2.91%模型決定系數0.96000.95030.95083.算法對比結果;對比實驗方法選取以下幾種主流求解算法:啟發式算法ATC-BATC規則,遺傳算法GA和差分進化算法DE。實驗獨立運行10次取平均值,結果如下表所示:與現有技術相比,本發明具有下面的優良效果。將融合代理模型的共生演化算法與幾種常見批調度算法進行調度性能上的對比,可以明顯發現所提出的算法SOS-SM可以獲得性能更好的調度解,結合代理模型進行快速評價的策略加強了進化算法搜索能力,而且一次評價所需消耗的時間遠遠低于真實評價過程,估計評價僅僅不到真實評價所消耗時間的1%。這樣對于需要大量適應值評價過程的進化過程,無疑提高了搜索的效率,同時配合真實重新評價策略,保證了獲取高質量解的可行性和通用性。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1