用于預測對食物的反應的方法和裝置與流程
在一些實施方案中,本發明涉及營養學,并更具體地但不只是涉及用于預測個體對一種或多種食物的反應的方法和裝置。
在過去30年間,肥胖癥在成人、兒童和青少年中的患病率急劇增加并持續上升。肥胖癥的傳統定義是基于體脂百分比,或最近以來是基于體重指數(BMI),其定義為體重(Kg)除以身高(米)的平方所得的比率。
超重和肥胖癥與增大發生許多慢性老年疾病的風險相關。此類合并癥包括:2型糖尿病、高血壓、冠心病和血脂異常、膽結石和膽囊切除、骨關節炎、癌癥(乳腺癌、結腸癌、子宮內膜癌、前列腺癌和膽囊)和睡眠呼吸暫停。已經認識到,降低這些疾病的嚴重程度的關鍵在于有效地減肥。盡管約30%至40%的人聲稱試圖減肥或保持體重,現有療法似乎不起作用。除了控制飲食以外,藥物治療以及(在極端情況下)外科手術,是批準用于治療超重和肥胖患者的輔助療法。藥物有副作用,而手術雖然有效,卻是極端措施,因而專用于病態肥胖。
Morris 等人[“Identification of Differential Responses to an Oral Glucose Tolerance Test in Healthy Adults,” 2013, PLoS ONE 8(8): e72890]識別出了針對口服葡萄糖耐受測試(OGTT)的差異反應者。發現了針對OGTT的四種不同的代謝反應,并通過不同水平的BMI、體脂和最大耗氧量表征。
國際公布No.WO2002100266公開了采用參考人類因素的數據庫的飲食技術。計算機接收用戶的人類因素數據并根據用戶數據和測得的血液特征預測所選定的該用戶的血液特征,以生成預測模型。然后根據輸入的人類因素數據查詢所述預測模型以生成并顯示預測的血液特征。還公開了包含針對選定的血液特征的預測模型的數據庫的用途,所述選定的血液特征是人類因素的函數。
國際公布No.WO2006079124公開了對食品和/或鍛煉以能量單位的表征,其中與攝入食品相關的以線性單位表示的能量數量與所得的吸收到1型糖尿病患者血液中的血糖直接成正比。還公開了對鍛煉以線性單位的表征,使得人在鍛煉時消耗的以線性單位表示的能量數量與所得的其血糖水平的降低直接成正比。
發明概述
根據本發明的一些實施方案的一個方面,提供了預測個體對食物的反應的方法。該方法包括:選擇食物,其中所述個體對其的反應是未知的;訪問第一數據庫,其含有描述所述個體但不描述其對所選食物的反應的數據;訪問第二數據庫,其含有關于其它個體對食物的反應的數據;以及基于所選食物分析這些數據庫以估計所述個體對所選食物的反應。
根據本發明的一些實施方案,所述第一數據庫包含關于所述個體對食物的反應的數據,這些食物均不同于所選食物。
根據本發明的一些實施方案的一個方面,提供了預測個體對食物的反應的方法。該方法包括:選擇食物和食物攝入背景,其中所述個體對其的反應是未知的;訪問第一數據庫,其含有描述所述個體但不描述其對所選食物在所選食物攝入背景下的反應的數據;訪問第二數據庫,其含有關于其它個體對食物的反應(其包括至少一名其它個體對所選食物的反應)的數據;以及基于所選食物分析這些數據庫以估計所述個體對所選食物在所選食物攝入背景下的反應。
根據本發明的一些實施方案,所述第一數據庫包含關于所述個體對食物在相應食物攝入背景下的反應的數據,這些食物在所選食物攝入背景下均不同于所選食物。
根據本發明的一些實施方案,所述食物攝入背景選自:食物量、日時間、睡前或睡后的時間、鍛煉前或鍛煉后的時間、精神或生理狀態以及環境狀況。
根據本發明的一些實施方案,所述其它個體的反應包括至少一名其它個體對所選食物的反應。
根據本發明的一些實施方案,所述第二數據庫缺乏任何其它個體對所選食物的任何反應。
根據本發明的一些實施方案,所述分析包括執行機器學習程序。
根據本發明的一些實施方案,所述第二數據庫包含根據預定的分類組群分類的數據,其中所述分析包括根據所述分類組群將所述個體分類以提供特異于所述個體的分類組,并且其中基于對應于所述分類組的所述第二數據庫中的反應估計所述個體對所選食物的反應。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目具有至少三個維度。根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目具有至少四個維度。根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目具有至少五個維度。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體并包含該個體所食用的食物并至少包含該個體對所述食物的升糖反應。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體,該個體在相應數據庫中通過至少所述個體的部分微生物組概況表征。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體并包含該個體所食用的食物并至少包含與所述食物相關的獨特攝入頻率。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體并包含該個體所食用的食物并至少包含所述食物的部分化學組成。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體,該個體在相應數據庫中通過至少所述個體的部分血液化學表征。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體,該個體在相應數據庫中通過至少所述個體的遺傳學概況表征。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體,該個體在相應數據庫中通過至少與所述個體相關的代謝組學數據表征。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體,該個體在相應數據庫中通過至少所述個體的身體狀況表征。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體,該個體在相應數據庫中通過至少所述個體的食物攝入習慣表征。
根據本發明的一些實施方案,所述第一和所述第二數據庫中的至少一個包含一個或多個多維條目,其中每個條目分別對應于一名個體并包含該個體在一定時間內所進行的活動的列表。
根據本發明的一些實施方案的一個方面,提供了計算機軟件產品,該產品包括計算機可讀介質,其中存儲了程序指令,當通過數據處理器讀取所述指令時,所述指令造成所述數據處理器接收食物(其中個體對所述食物的反應是未知的)并執行如上所述并任選地如下詳述的方法。
根據本發明的一些實施方案的一個方面,提供了用于預測個體對食物的反應的裝置。該裝置包括:用戶界面,其被配置成接收食物,其中所述個體對所述食物的反應是未知的;和數據處理器,其具有存儲所述計算機軟件產品的計算機可讀介質。
根據本發明的一些實施方案的一個方面,提供了構建數據庫的方法。該方法包括,針對一組個體中的每名個體:監測該個體在至少數天的時間內的血糖水平;監測該個體在所述時間內所食用的食物;分析所監測的血糖水平和所監測的食物以將升糖反應與所食用的食物的至少一部分中的每種食物關聯起來;以及在至少一個數據庫中制作關于所述關聯的數據庫記錄。
根據本發明的一些實施方案,所述方法中的所述至少一個數據庫包含對應于所述個體組中所有個體的組數據庫。
根據本發明的一些實施方案,針對至少一名個體,所述至少一個數據庫還包含對應于所述個體的個體特異性數據庫。
根據本發明的一些實施方案,所述方法包括獲得關于所述個體和/或所述食物的額外數據,并在所述至少一個數據庫中制作所述額外數據的記錄。
根據本發明的一些實施方案,所述方法包括使用多維分析程序處理所述至少一個數據庫,并響應于所述分析更新所述至少一個數據庫。
根據本發明的一些實施方案,所述多維分析程序包括執行機器學習程序。
根據本發明的一些實施方案,所述機器學習程序包含監督學習程序。
根據本發明的一些實施方案,所述機器學習程序包含選自以下的至少一種程序:分類、回歸、聚類、支持向量機、線性建模、k-最近鄰分析、決策樹學習、集成學習程序、神經網絡、概率模型、圖形模型、貝葉斯網絡和關聯規則學習。
根據本發明的一些實施方案,所述額外數據包含所述個體的至少部分微生物組概況。
根據本發明的一些實施方案,所述額外數據包含與所述食物相關的獨特攝入頻率。
根據本發明的一些實施方案,所述額外數據包含所述食物的至少部分化學組成。
根據本發明的一些實施方案,所述額外數據包含所述個體的至少部分血液化學。
根據本發明的一些實施方案,所述額外數據包含所述個體的至少遺傳學概況。
根據本發明的一些實施方案,所述額外數據包含與所述個體相關的代謝組學數據。
根據本發明的一些實施方案,所述額外數據包含所述個體的身體狀況。
根據本發明的一些實施方案,所述額外數據包含所述個體的食物攝入習慣。
根據本發明的一些實施方案,所述額外數據包含所述個體在一定時間內所進行的活動的列表。
根據本發明的一些實施方案,所述食物是食物產品。
根據本發明的一些實施方案,所述食物是食物類型。
根據本發明的一些實施方案,所述食物是食物類型家族。
根據本發明的一些實施方案,所述食物是多種食物的組合,所述多種食物中的每種食物分別選自食物產品、食物類型和食物類型家族。
根據本發明的一些實施方案,所述方法、產品或裝置是用于預防、控制和/或治療身體狀況,如與肥胖癥、代謝綜合征、糖尿病以及肝臟疾病或失調直接相關的狀況。
除非另行定義,否則本文中所用的全部技術和/或科學術語具有與本發明所屬領域普通技術人員通常所理解的相同的含義。盡管與本文所述那些類似或等同的方法和材料可用于實踐或測試本發明的實施方案,但仍然在下文中描述了示例性方法和/或材料。在沖突的情況下,以本專利說明書(包括定義在內)為準。另外,所述材料、方法和實施例僅為說明性的而非旨在必要限制。
本發明的實施方案的方法和/或裝置的實施可涉及以手動、自動或其組合的方式執行或完成所選任務。此外,根據本發明的方法和/或裝置的實施方案的實際儀器和設備,若干選定的任務可以通過硬件、通過軟件或通過固件或通過其組合使用操作系統實施。
例如,用于執行根據本發明的實施方案的所選任務的硬件可以芯片或電路的形式實施。至于軟件,根據本發明的實施方案的所選任務可以多個軟件指令的形式實施,所述多個軟件指令通過計算機使用任何合適的操作系統執行。在本發明的示例性實施方案中,根據如本文所述的方法和/或裝置的示例性實施方案的一項或多項任務通過數據處理器(如用于執行多個指令的計算平臺)執行。任選地,所述數據處理器包括易失性存儲器,用于存儲指令和/或數據,和/或非易失性存儲(例如,硬磁盤和/或可移動介質),用于存儲指令和/或數據。任選地,也提供了網絡連接。任選地也提供了顯示器和/或用戶輸入設備(如鍵盤或鼠標)。
附圖的若干視圖的簡要說明
本文僅以舉例的方式,結合附圖描述了本發明的一些實施方案。現在具體結合附圖的細節,強調所示具體內容是以舉例的方式并出于說明討論本發明的實施方案的目的。就此而言,附圖說明使得如何實踐本發明的實施方案對于本領域技術人員變得顯而易見。
在附圖中:
圖1是根據本發明的一些實施方案的適用于預測個體對食物的反應的方法的流程圖;
圖2A和2B是根據本發明的一些實施方案的個體特異性數據庫(圖2A)和組數據庫(圖2B)的代表性圖解;
圖3是根據本發明的一些實施方案的適用于構建數據庫的方法的流程圖;
圖4示出了根據本發明的一些實施方案進行的研究的參與者的原始血糖測量結果的實例;
圖5A-F示出了根據本發明的一些實施方案進行的研究的參與者的血糖反應的柱狀圖;
圖5G示出了如根據本發明的一些實施方案進行的實驗中所測量的不同個體對葡萄糖、面包和面包加黃油的反應的聚類;
圖6A-C示出了如根據本發明的一些實施方案進行的研究過程中獲得的葡萄糖(圖6A)、面包(圖6B)和面包加黃油(圖6C)的兩組重復測量結果的血糖反應的比較;
圖7A-E示出了如根據本發明的一些實施方案進行的研究過程中,所有研究參與者的餐食中的碳水化合物量與升糖反應間的相關性柱狀圖(圖7A)、在碳水化合物量與升糖反應間具有低相關性的兩名參與者的實例(圖7B和7C)和具有高的此類相關性的兩名參與者的實例(圖7D和7E);
圖8A-D 示出了如根據本發明的一些實施方案進行的研究過程中獲得的 升糖反應的預測結果;
圖9A-G示出了根據本發明的一些實施方案通過分析所獲得的結果,所述分析包括使用決策樹的隨機梯度boosting;
圖10A-B示出了根據本發明的一些實施方案使用組數據庫(包含其它個體對食物的反應)和個體特異性數據庫(包含描述該個體的數據但不包含對任何食物的任何反應)獲得的血糖水平預測;
圖11是條形圖,其表明:相比不良周,在良好周的平均升糖反應更低。在良好周(綠色)和不良周(紅色),16名參與者的平均iAUCmed水平。iAUCmed是相對于進餐前15分鐘的中值血糖水平,在進餐后的頭兩個小時內,曲線下方面積(AUC)的增量。參與者的iAUCmed水平是其所有早餐、午餐和晚餐的平均iAUCmed。在x軸上,IG代表血糖受損的參與者,而H代表健康的參與者。符號IG/H后方括號內的第一個數字是6天實驗的平均起床血糖水平,而方括號內的第二個數字是實驗開始時的HbA1C;
圖12是坐標圖,其表明:對餐食的升糖反應遵循晝夜變化規律,其中早餐具有最低反應,然后是午餐,而晚餐具有最高反應。每個點均代表:相比良好周(y軸),不良周(x軸)的餐食的平均iAUCmed。大多數點位于x=y線的下方,意味著:平均而言,相比良好周,不良周的AUC更高。示出了早餐(紅色)、午餐(綠色)和晚餐(藍色)的iAUCmed水平。實心點對應血糖受損的參與者,而空心點對應健康的個體。相比午餐(綠線)然后是晚餐(綠線),血糖受損的參與者的所有早餐(紅線)的線性擬合的斜率是最高的。虛線對應健康的參與者,而實線對應血糖受損的參與者;
圖13A-B是曲線圖,其表明:在通過餐食卡路里和碳水化合物水平的歸一化之后,進餐后的AUC顯示出晝夜變化規律。圖13A示出了通過餐食卡路里含量歸一化的iAUCmed,而圖13B示出了通過餐食碳水化合物含量歸一化的iAUCmed。
發明的具體實施方式
在一些實施方案中,本發明涉及營養學,并更具體地但不只是涉及用于預測個體對一種或多種食物的反應的方法和裝置。
在詳細闡釋本發明的至少一個實施方案之前,應當理解,本發明不一定受限于其在以下說明中提及的和/或在附圖和/或實施例中示出的部件和/或方法的具體構造和布置方式中的應用。本發明可以有其他的實施例或以各種方式實施或使用。
本實施方案采用計算方法用于預測個體對食物的反應的目的,以及任選地但非必須地,用于解讀微生物群對此類反應的貢獻。那些其對食物的反應是根據本發明的一些實施方案而預測的個體,在下文中被稱為分析個體。本實施方案優選地探究先前收集的有關不同于分析個體的多名個體對食物的反應的理解。此多名個體在下文中被稱為“其它個體”。
在本發明的各種示例性實施方案中,預測的反應包括預測的在個體食用食物之后立刻或短時間后將發生的血糖水平變化。個體對食物的反應任選地和優選地是針對這樣的食物進行預測的:該個體對所述食物的反應是未知的。例如,本實施方案可以預測個體對以下的反應:其從未食用過的食物、過去食用過的但沒有確定對其的反應的食物、或過去已知該個體對其的反應但懷疑由于該個體的條件(例如,健康狀況、生長、微生物組含量)變化而發生了改變的食物。本實施方案可以預測這樣的個體對食物的反應:所述反應在特定的食物攝入背景下是已知的,但在另一個食物攝入背景下是未知的。食物攝入背景可以包括但不限于:進食量、在一天中的什么時間進食、在睡前或睡后的什么時間進食、在鍛煉前或鍛煉后的什么時間進食、在食物攝入期間個體的精神或生理狀態(例如,壓力水平、疲勞程度、心情、疼痛、姿勢)、食物攝入期間的環境狀況(例如,溫度、進食地點、共同進食的個體數量)等。因此,例如,對于個體在早晨對其的反應是已知的食物而言,本實施方案可以預測該個體在中午或之后對該食物的反應。
在本發明的一些實施方案中,所述食物是食物產品(例如,由特定生產商或由生產相同食物產品的兩個或更多個生產商銷售的特定食物產品)。在本發明的一些實施方案中,所述食物是食物類型(例如,具有不同改變形式的食物,例如,白米,其可具有不同種類,但都稱為“白米”,或全麥面包,其可能回溯自各種混合物,等等)。在本發明的一些實施方案中,所述食物是食物類型家族。所述家族可以根據食物類型的主要成分而分類,例如,甜食、乳制品、水果、香草(herb)、蔬菜、魚類、肉類等。在本發明的一些實施方案中,所述食物類型家族是食物組,如但不限于:碳水化合物,其是涵蓋了富含碳水化合物的食物類型的家族;蛋白質,其是涵蓋了富含蛋白質的食物類型的家族;和脂肪,其是涵蓋了富含脂肪的食物類型的家族;礦物質,其是涵蓋了富含礦物質的食物類型的家族;維生素,其是涵蓋了富含維生素的食物類型的家族,等等。在本發明的一些實施方案中,所述食物是食物組合,其包括了多種不同食物產品和/或不同食物類型和/或不同食物家族。此類組合被稱為“復合餐食”。所述復合餐食可以作為構成所述組合的食物產品、食物類型和/或食物類型家族的列表而提供。所述列表可能包括或不包括組合中各種食物產品、食物類型和/或食物類型家族的具體的量。
本文所述的任何方法均可以多種形式體現。例如,其可以體現在有形介質(如計算機)上用于進行所述方法操作。其可以體現在計算機可讀介質(包含計算機可讀指令)上用于進行所述方法操作。其也可以體現在具有數字計算機能力的電子裝置上,所述數字計算機能力被布置成在有形介質上運行計算機程序或在計算機可讀介質上執行指令。
實施本實施方案的方法的計算機程序通常可以在傳播介質(如但不限于CD-ROM或閃存介質)上被傳播給用戶。從傳播介質,所述計算機程序可以被復制到硬盤或類似的中間存儲介質上。在本發明的一些實施方案中,實施本實施方案的方法的計算機程序可以通過允許用戶經由通信網絡(例如,互聯網)遠程下載程序而被傳播給用戶。所述計算機程序可以通過如下運行:從其傳播介質或其中間存儲介質加載計算機指令至計算機執行內存,配置計算機以根據本發明的方法運作。所有這些操作均是計算機系統領域技術人員所熟知的。
現在參見附圖,圖1是根據本發明的一些實施方案的適用于預測個體對食物的反應的方法的流程圖。應當理解,除非另行定義,否則下文所述的操作可以多種執行組合或順序同時或依序執行。具體地講,該流程圖的順序不被視為限制性的。例如,在以下描述中或流程圖中以特定順序出現的兩個或更多個操作,可以不同順序(例如,反序)或基本上同時執行。另外,下述若干操作是任選的并且可以不執行。
所述方法從10開始并繼續到11,在該處選定食物,其中個體對所述食物的反應是未知的。食物產品可以選自食物列表,所述列表可通過例如用戶界面裝置或組件(如觸摸屏或顯示裝置和鍵盤)而被提供給個體或其它用戶。任選地,可以向用戶提供主要食物類型家族的列表以供選擇。根據食物類型家族的選擇,如果需要,可以任選地提供屬于該家族的食物類型列表以供選擇。根據食物類型的選擇,如果需要,可以任選地提供食物產品列表,用戶可以從中選擇食物。還設想了這樣的實施方案,其中個體或其它用戶使用鍵盤輸入食物。任選地,當用戶輸入時,采用補全算法(例如,文字補全),如本領域中已知的。食物的選擇可以任選地并優選地伴隨針對所選食物的選擇食物攝入背景。例如,可以向用戶提供食物攝入背景的列表以供選擇。
所述方法繼續至12,在此處, 訪問個體特異性數據庫 。所述個體特異性數據庫以計算機可讀形式存儲在計算機可讀介質上,并且任選地并優選地通過數據處理器(如通用計算機或專用電路)訪問。
所述個體特異性數據庫包含描述該個體的數據。在本發明的一些實施方案中,所述 個體特異性數據庫 包含關于該個體對食物的反應的數據。在圖2A中提供了根據本發明的一些實施方案的個體特異性數據庫22的代表性圖解。
所述個體特異性數據庫的數據可以被布置為構成該個體對相應食物組的一組反應。在所述個體特異性數據庫中的食物的數量優選地為至少10或至少20或至少30或更多。當以組的形式定義食物和反應時,食物的數量可以被定義為所述組的大小(各組中要素的數量)。
在本發明的各種示例性實施方案中,所述個體特異性數據庫包含關于該個體對食物的反應的數據,但不包含該個體對所選食物的反應。換句話講,在這些實施方案中,食物組中沒有食物是在11所選擇的食物。與所選食物具有一些相似性的食物可能存在于所述個體特異性數據庫中。例如,如果選擇了一種食物產品,那么所述個體特異性數據庫優選地不包含該特定食物產品,但可能任選地并優選地包含與所選食物產品屬于相同類型或相同類型家族的食物產品。例如,如果選擇了一種食物類型,那么所述個體特異性數據庫優選地不包含該食物類型,但可能任選地并優選地包含與所選食物類型屬于相同類型家族的食物類型。在其中還選擇了食物攝入背景的實施方案中,所述個體特異性數據庫可能任選地包含該個體對所選食物的反應,但優選地在不同于所選背景的背景下。
雖然對上述實施方案的描述中特別強調了個體特異性數據庫包含關于個體對食物的反應的數據,但應當理解,所述個體特異性數據庫可能缺乏該個體對食物的任何反應。所述個體特異性數據庫可以包含描述該個體的任何數據。不同于對食物的反應的數據類型的代表性實例包括但不限于:微生物組概況、部分微生物組概況、個體的血液化學、個體的部分血液化學、個體的遺傳學概況、與個體相關的代謝組學數據、個體的身體狀況、個體的食物攝入習慣等。這些和其它數據類型更詳細地描述于下。
所述方法繼續至13,在此處,訪問組數據庫。所述組數據庫以計算機可讀形式存儲在計算機可讀介質上,并且任選地并優選地通過數據處理器(如通用計算機或專用電路)訪問。兩種數據庫均可以存儲在相同介質上并任選地和優選地通過相同的數據處理器訪問。
在圖2B中提供了根據本發明的一些實施方案的組數據庫24的代表性圖解。所述組數據庫包含關于其它個體對食物的反應的數據。然而,不同于可能任選地僅包含分析個體對食物的反應的個體特異性數據庫,組數據庫的反應包括其它個體對食物的反應。所述組數據庫的數據可以被布置為構成對相應食物組的一組反應。
在圖2A示出的個體特異性數據庫中,每個條目均可以元組(F, R)的形式描述,其中F表示數據庫中的特定食物,而R表示該個體對F的反應。因此,該示例性圖解是二維數據庫,其中所有要素均可以通過食物和相應反應張成的二維空間中的向量描述。在圖2B示出的組數據庫中,每個條目均可以元組(S, F, R)的形式描述,其中S表示組數據庫中的特定個體,F表示特定食物,而R表示個體S對食物F的反應。因此,該示例性圖解是三維數據庫,其中所有要素均可以通過個體、食物和相應反應張成的三維空間中的向量描述。本發明的一些實施方案設想了使用具有更高維度的數據庫。此類數據庫在下文中有述。
所述組數據庫可能任選地并優選地還包含所述個體特異性數據庫的一個或多個、更優選全部的條目。在其中組數據庫包含所述個體特異性數據庫的全部條目的實施方案中,不必使用兩個單獨的數據庫,因為整個數據集都被包含在一個包容性數據庫中。此類包容性數據庫還任選地并優選地以這樣的方式注釋:其允許區分所述包容性數據庫中與分析個體相關的的部分和所述包容性數據庫中僅與其它個體相關的部分。在本公開的上下文中,所述包容性數據庫中與分析個體相關的部分被稱為個體特異性數據庫,即使當其并未以單獨的數據庫的形式提供時。類似地,所述包容性數據庫中僅與其它個體相關的部分被稱為組數據庫,即使當其并未以單獨的數據庫的形式提供時。
在本發明的一些實施方案中,所述組數據庫包含在11選擇的食物和一名或多名其它個體對所選食物的反應,但不包含分析個體對所選食物的反應。因此,在本發明的一些實施方案中,分析個體對在11選擇的食物的反應既不在所述個體特異性數據庫中,也不在所述組數據庫中。
組數據庫優選包含許多個體(例如,至少10名個體或至少100名個體,例如,500名個體或更多)對食物的反應。在組數據庫中的不同食物的數量任選地并優選地大于在個體特異性數據庫中的不同食物的數量。兩種數據庫均可包含相同數量的不同食物類型和/或不同食物類型家族。然而,這并不是必須的,因為這兩種數據庫之間不同食物類型的數量和/或不同食物類型家族的數量可能不同。
由于組數據庫包含關于多名個體的數據,所以該數據庫中的食物組可能包含重復要素。例如,簡單起見,考慮三名個體(標注為S1、S2和S3)以及四種食物(標注為F1、F2、F3和F4)。假設該組數據庫包含關于這三名個體和這些食物的數據,其中所述組數據庫包含個體S1和S2分別對全部四種食物的反應,以及個體S3對食物F1、F2和F3但沒有對F4的反應(注意,在不喪失一般性的同時,這符合其中S3是分析個體而F4是所選食物的情況)。在此實例中,食物F1、F2和F3可能在所述組數據庫中各出現三次,而食物F4可能在所述組數據庫中出現兩次。在數學上,用Rij指代第i名個體對第j種食物的反應,組數據庫的反應組可以是{R11、R12、R13、R14、R21、R22、R23、R24、R31、R32、R33},而組數據庫的食物組可以是{F1、F2、F3、F4、F1、F2、F3、F4、F1、F2、F3}。
應當理解,雖然本文所述的數據庫可以組的形式布置,但在本發明的一些實施方案中也設想了其它類型的數據結構。數據庫中的至少一些數據還可以如上所示被布置成組的形式。
一旦數據庫被訪問,則所述方法繼續至14,此處,基于所選食物分析所述數據庫以估計該個體對所選食物的反應。此分析可以不止一種方式執行。在下文中提供了適用于分析根據本發明的一些實施方案的數據庫的示例性技術。
所述方法任選地并優選地繼續至15,此處,將估計的反應至少暫時地存儲在計算機可讀介質中,從中可以根據需要提取或顯示所述反應。在一些實施方案中,所述方法繼續至16,此處,使用所估計的反應更新所述數據庫之一或兩者。
所述方法在17結束。
在提供用于預測個體對食物的反應的方法的進一步詳細說明之前,如上所述并根據本發明的一些實施方案,將要關注于優點及其提供的潛在應用。
本發明人證實了本實施方案的方法提供個體反應(例如葡萄糖、膽固醇、鈉、鉀、鈣)的個人預測的能力,這些個人預測切合該個體的各種收集的參數。本實施方案因此提供了基于個人的營養學,這是對傳統上基于經驗的營養學的顯著改善。本實施方案可以用作主要預防或減少正常和易感個體的例如高血糖風險的手段。本實施方案提供了生物和計算工具箱,其結合了個體的飲食習慣并任選地還有遺傳學和/或微生物群,以預測他/她對各種未測試食物的反應(例如,升糖反應)。
本實施方案可用于提供個體特異性飲食干預的個體化預測,例如,出于一級和/或二級預防和/或治療和/或控制身體狀況的目的,所述身體狀況如與肥胖癥、代謝綜合征、糖尿病和肝臟疾病或失調直接相關的狀況。
一般來講,術語“預防”、“控制”和“治療”涵蓋了:預防個體中疾病或癥狀的發展,該個體可能具有所述疾病或所述癥狀的易感體質但尚未診斷出患有所述疾病或所述癥狀;抑制疾病的癥狀,即,抑制或延遲其進展;以及緩解疾病的癥狀,即,所述疾病或所述癥狀消退,或所述癥狀的進展逆轉。
可根據本發明的一些實施方案控制或治療所有類型的肥胖癥,包括但不限于:內源性肥胖、外源性肥胖、胰島功能亢進性肥胖、增生性肥大性肥胖、肥大性肥胖、甲狀腺功能減退性肥胖和病態肥胖。例如,本實施方案可以用于減慢、停止或逆轉體重增長,特別是體脂增長,導致體重保持或下降。體重或體脂下降可通過降低血壓、總膽固醇、LDL膽固醇和甘油三酯而防止心血管疾病,并可緩解與慢性疾病(如高血壓、冠心病、2型糖尿病、高脂血癥、骨關節炎、睡眠呼吸暫停和退行性關節疾病)相關的癥狀。
代謝綜合征或綜合征X,是伴隨有各種異常(包括高血壓、高甘油三酯血癥、高血糖、低水平的HDL-C和腹型肥胖)的復雜的多因素疾病。具有這些特征的個體通常表現出血栓前和促炎癥反應狀態。現有數據表明代謝綜合征確實是一種綜合征(一種風險因素分組)。
根據世界衛生組織(WHO)指導原則,如果個體表現出:a)高血壓(>140 mm Hg 收縮壓 或 >90 mm Hg 舒張壓);b) 血脂異常,定義為升高的血漿甘油三酯(150 mg/dL)和/或低高密度脂蛋白(HDL)膽固醇(<35 mg/dL 男性,<39 mg/dL 女性);c)內臟型肥胖,定義為高體重指數(BMI)(30 kg/m2)和/或高腰臀比(>0.90 男性,>0.85 女性);和 d) 微量白蛋白尿(尿白蛋白排泄率:20 g/min),則存在代謝綜合征。參見WHO-國際高血壓學會高血壓管理指南(International Society of Hypertension Guidelines for the Management of Hypertension)。指導委員會(Guidelines Subcommittee)。J. Hypertens.17:151-183, 1999。
根據全美膽固醇教育計劃(NCEP ATP III 研究),如果存在下列五(5)項風險因素中的三(3)項或更多項,則診斷為代謝綜合征:1)腰圍 >102 cm (40 in) 男性 或 >88 cm (37 in) 女性;2)甘油三酯水平:150 mg/dL;3)HDL膽固醇水平 <40 mg/dL 男性 或 <50 mg/dL 女性;4)血壓 >130/85 mm Hg;或5)空腹血糖 >110 mg/dL。JAMA 285: 2486-2497, 2001。
與代謝綜合征相關的各項失調自身就是風險因素,并且可以促發動脈粥樣硬化、心血管疾病、腦卒中、全身性微血管和大血管并發癥以及其它不良健康后果。然而,當同時存在時,這些因素對增加的心血管疾病、腦卒中以及全身性微血管和大血管并發癥的風險具有預測性。
本實施方案可以降低代謝綜合征的癥狀的嚴重程度和/或數量,如在分析個體中所示。此類癥狀可包括:血糖升高、葡萄糖耐受不良、胰島素抵抗、甘油三酯升高、LDL膽固醇升高、低高密度脂蛋白(HDL)膽固醇、血壓升高、腹型肥胖、促炎癥反應狀態和血栓前狀態。本實施方案還可以降低發展相關疾病的風險,和/或推遲此類疾病的發作。此類相關疾病包括:心血管疾病、冠心病和其它與動脈壁斑塊有關的疾病以及糖尿病。
糖尿病包括:例如,1型糖尿病、2型糖尿病、妊娠期糖尿病、糖尿病前期、緩慢發作的自身免疫性1型糖尿病(LADA)、高血糖和代謝綜合征。所述糖尿病可能是顯性的、確診的糖尿病,例如,2型糖尿病,或是糖尿病前期狀況。
糖尿病(diabetes mellitus)(本文中一般稱為“糖尿病(diabetes)”)是以血糖調節受損為特征的疾病。糖尿病是當胰腺無法產生足夠的胰島素或當身體無法有效利用所產生的胰島素時而發生的慢性疾病,其導致血液中葡萄糖濃度升高(高血糖)。糖尿病可分為1型糖尿病(胰島素依賴型、青少年或兒童期發作的糖尿病)、2型糖尿病(非胰島素依賴型或成年期發作的糖尿病)、LADA糖尿病(成年晚期自身免疫性糖尿病)或妊娠期糖尿病。另外,中間狀況(如葡萄糖耐受性異常和空腹血糖異常)被認為是表明發展出2型糖尿病的高風險的狀況。
在1型糖尿病中,由于胰腺β細胞的自身免疫性破壞而缺乏胰島素生產。所述自身免疫性破壞具有若干可在體液和組織中檢測到的標記物,包括:胰島細胞自身抗體、胰島素自身抗體、谷氨酸脫羧酶自身抗體和酪氨酸磷酸酶ICA512/IA-2自身抗體。在2型糖尿病(占世界上糖尿病的90%)中,胰島素分泌可能不足,但據信,外周組織胰島素抵抗才是主要缺陷。2型糖尿病通常(盡管并非總是)與肥胖癥(胰島素抵抗的成因之一)相關。
2型糖尿病之前通常具有糖尿病前期,其中血糖水平高于正常但尚未高到足以被診斷為糖尿病。
術語“糖尿病前期”,如本文所用,可與術語“葡萄糖耐受性異常”或“空腹血糖異常”互換使用,這些都是涉及用于測量血糖水平的測試的術語。
糖尿病中的慢性高血糖與影響微血管和/或大血管的多種(主要是血管)并發癥相關。這些遠期并發癥包括:視網膜病變(導致焦距模糊、視網膜脫離以及部分或全部視力喪失)、腎臟病變(導致腎功能衰竭)、神經病變(導致疼痛、麻木以及四肢失去知覺,并可能會導致足部潰瘍和/或截肢),心臟病變(導致心力衰竭)和感染風險增加。2型糖尿病或非胰島素依賴型糖尿病(NIDDM)與利用葡萄糖的組織(如脂肪組織、肌肉和肝臟)對胰島素的生理作用的抵抗有關。與NIDDM相關的長期高血糖可以導致引起衰弱的并發癥,包括:腎臟病變(通常必須透析或腎移植);周圍神經病變;視網膜病變(導致失明);下肢潰瘍和壞死(導致截肢);脂肪肝(可能發展為肝硬化);以及易發冠心病和心肌梗死。本實施方案可以用于降低發展糖尿病的風險,或推遲此類疾病的發作。本實施方案可以用于降低發展相關并發癥的風險,和/或推遲此類并發癥的發作。
糖尿病的狀況可以使用本領域已知的多種測定法中的任一種進行診斷或監測。用于將個體診斷或分類為糖尿病或糖尿病前期或監測所述個體的測定法的實例包括但不限于:糖化血紅蛋白(HbA1c)測試、連接肽(C-肽)測試、空腹血糖(FPG)測試、口服葡萄糖耐受測試(OGTT)以及非正式的血糖測試。
HbA1c是生物標記物,其測量血液中糖化血紅蛋白的量。HbA1c代表了血紅蛋白的穩定的輕微糖基化的亞部分。其反映了在過去6-8周內的平均血糖水平,并且以總血紅蛋白的百分數(%)表示。作為另外一種選擇,糖尿病或糖尿病前期可以通過測量血糖水平來診斷,例如,使用血糖監測儀或本領域已知的數種測試中的任一種,包括但不限于,空腹血糖測試或口服葡萄糖耐受測試。當使用空腹血糖(FPG)測試時,如果患者的閾值FPG大于125 mg/dl,則該患者被歸類為糖尿病人,而如果患者的閾值FPG大于100 mg/dl但小于或等于125 mg/dl,則該患者被歸類為糖尿病前期。當使用口服葡萄糖耐受測試(OGTT)時,如果患者的閾值2小時OGTT葡萄糖水平大于200 mg/dl,則該患者被分類為糖尿病。如果患者的閾值2小時OGTT葡萄糖水平大于140 mg/dl但小于200 mg/dl,則該患者被分類為糖尿病前期。
由胰島素原分子產生的C-肽,自胰島細胞以與胰島素的等摩爾比例分泌到血液中,并用作β-細胞功能和胰島素分泌的生物標記物。大于2.0 ng/ml的空腹C-肽測量結果表明高水平的胰島素,而小于0.5 ng/ml空腹C-肽測量結果表明胰島素產量不足。
已被分類為具有糖尿病狀況并且根據本發明的一些實施方案進行了分析的個體,可通過測量血糖來監測治療的功效,例如,使用血糖監測儀和/或通過測量生物標記物指標(包括但不限于:糖化血紅蛋白水平、C-肽水平、空腹血糖水平以及口服葡萄糖耐受測試(OGTT)水平)。
本發明的一些實施方案可以用于預防、治療和/或控制血脂過多(也稱為高脂蛋白血癥或高脂血癥),其涉及血液中任何或所有脂質和/或脂蛋白的異常高水平。其是血脂異常(其包括任何異常的脂質水平)的最常見的形式。血脂過多也根據升高的脂質的類型來分類,即高膽固醇血癥、高甘油三酯血癥或二者并存的混合型高脂血癥。升高水平的脂蛋白也被歸類為血脂過多的形式。根據本術語還包括:I型高脂蛋白血癥、II型高脂蛋白血癥、III型高脂蛋白血癥、IV型高脂蛋白血癥和V型高脂蛋白血癥,以及未分類的家族型和獲得型高脂血癥。
本發明的一些實施方案可以用于預防、治療和/或控制肝臟疾病和失調,包括肝炎、肝硬化、非酒精性脂肪性肝炎(NASH)(也被稱為非酒精性脂肪肝-NAFLD)、肝中毒和慢性肝臟疾病。
術語“肝臟疾病”適用于許多疾病和失調,其引起肝功能異常或功能停止,而這種肝功能的喪失指示肝臟疾病。因此,肝功能測試經常用于診斷肝臟疾病。此類測試的實例包括但不限于下列:(1) 測定血清酶(如乳酸脫氫酶(LDH)、堿性磷酸酶(ALP)、天冬氨酸轉氨酶(AST)和丙氨酸轉氨酶(ALT))水平的測定法,其中酶水平的升高指示肝臟疾病。本領域技術人員將適當理解,這些酶測定法僅僅表明肝臟已受損。其并不評估肝臟的功能。其它測試可以用于測定肝臟的功能;(2) 測定血清膽紅素水平的測定法。血清膽紅素水平以總膽紅素和直接膽紅素的形式報告。總血清膽紅素的正常值為0.1-1.0 mgdl(例如,約2-18 mmol/L)。直接膽紅素的正常值為0.0-0.2 mg/dl(0-4 mmol/L)。血清膽紅素的升高指示肝臟疾病。(3) 測定血清蛋白質水平,例如,血清白蛋白和球蛋白(例如,α、β、γ)的測定法。總血清蛋白質的正常值為6.0-8.0 g/dl(60-80 g/L)。血清白蛋白的降低指示肝臟疾病。球蛋白的升高指示肝臟疾病。
其它測試包括:凝血酶原時間、國際標準化比值、活化凝血時間(ACT)、部分凝血活酶時間(PTT)、凝血酶原消耗時間(PCT)、纖維蛋白原、凝血因子、甲胎蛋白和甲胎蛋白-L3(百分比)。
肝臟疾病的一種類型是肝炎。肝炎是肝臟炎癥,其可由病毒(例如甲肝病毒、乙肝病毒和丙肝病毒(分別為HAV、HBV和HCV))、化學物質、藥物、酒精、遺傳病或患者自身免疫系統(自體免疫肝炎)引起。這種炎癥可以是急性的并在數周至數月內消退,或者是慢性的并持續多年。慢性肝炎在引發顯著癥狀(如肝硬化(瘢痕形成和喪失功能)、肝癌或死亡)前可以持續幾十年。術語“肝臟疾病”所涵蓋的并根據本發明的一些實施方案適于治療或預防或控制的不同疾病和失調的其它實例包括但不限于:阿米巴性肝膿腫、膽道閉鎖、肝纖維化、肝硬化、球孢子菌病、D型肝炎病毒、肝細胞癌(HCC)、酒精性肝病、原發性膽汁性肝硬化、化膿性肝膿腫、瑞氏綜合征、硬化性膽管炎、威爾遜氏病。本發明的一些實施方案可用于治療以肝實質細胞的損耗或損壞為特征的肝臟疾病。在一些方面,其病因可以是局部或全身性炎癥反應。
當肝臟的大部分被損壞時,發生肝衰竭,而肝臟不再能夠發揮其正常的生理功能。在一些方面,肝衰竭可以使用上述肝功能測定法或通過個體癥狀來診斷。與肝衰竭有關的癥狀包括,例如,以下一種或多種:惡心、食欲不振、疲勞、腹瀉、黃疸、異常/出血過多(如凝血病)、腹部腫大、精神迷失或困惑(如肝性腦病)、嗜睡和昏迷。
慢性肝衰竭發生在數月至數年中并且最常由病毒(例如,HBV和HCV)、長期/過量飲酒、肝硬化、血色素沉著癥和營養不良引起。急性肝衰竭是肝臟疾病的初期體征(例如,黃疸)后的嚴重并發癥的表觀并且包括多種狀況,所有這些狀況均涉及嚴重的肝細胞損傷或壞死。本發明的一些實施方案可用于治療超急性、急性和亞急性肝衰竭、暴發性肝衰竭和晚發性暴發性肝衰竭,所有這些在本文中均被稱為“急性肝衰竭”。急性肝衰竭的常見誘因包括,例如,病毒性肝炎、暴露于某些藥物和毒素(例如,氟化烴(例如,三氯乙烯和四氯乙烷)、鵝膏蕈(例如,常見的“死帽菇”)、醋氨酚(撲熱息痛)、鹵乙烷、磺胺類、苯妥英)、心臟相關的肝缺血(例如,心肌梗死、心臟驟停、心肌病和肺栓塞)、腎功能衰竭、肝靜脈流出道阻塞(例如,Budd-Chiari綜合征)、威爾遜氏病、妊娠急性脂肪肝、阿米巴膿腫和播散性結核。
術語“肝炎”用于描述肝臟狀況,其意味著肝臟損傷,特征在于器官組織中存在炎癥細胞。該狀況可以是自限性的、自愈的,或可以進展為肝臟瘢痕形成。當肝炎持續短于六個月,則其為急性的,而當持續長于六個月,則其為慢性的。被稱為肝炎病毒的病毒類別引發全世界大多數肝臟損壞的病例。肝炎也可以是由于毒素(值得注意的是酒精)、其它感染引起或來自自體免疫過程。肝炎包括下列來源的肝炎:病毒感染,包括甲型肝炎至戊型肝炎(A、B、C、D和E--占超過95%的病毒誘因)、單純皰疹病毒、巨細胞病毒、愛潑斯坦-巴爾病毒、黃熱病病毒、腺病毒;非病毒感染,包括弓形蟲、鉤端螺旋體、Q熱、落磯山斑點熱、酒精、毒素(包括鵝膏毒蘑菇、四氯化碳、阿魏等等)、藥物(包括對乙酰氨基酚、羥氨芐青霉素、抗結核藥、米諾環素及如本文所述的其它藥物);缺血性肝炎(循環不足);妊娠;自身免疫性疾病,包括系統性紅斑狼瘡(SLE);和非酒精性脂肪性肝炎。
“無菌性炎癥”用于描述這樣的肝臟炎癥,其由從已經失去其質膜完整性的瀕死細胞釋放的細胞內分子所觸發。此炎癥發生時不存在致病因子如病毒或細菌和酒精。已經識別出多種細胞內分子,其可刺激其它細胞產生促炎癥反應細胞因子和趨化因子。此類促炎癥反應細胞分子被認為是通過接合產生細胞因子的細胞上的受體而發揮作用。如果放任而不治療,無菌性炎癥可能進展為非酒精性脂肪肝(NAFLD)、非酒精性脂肪性肝炎(NASH)或肝硬化。
“非酒精性脂肪性肝炎”或“NASH”是這樣一種肝臟狀況,其中炎癥是由肝臟內脂肪積聚而引起的。NASH是一類肝臟疾病中的一部分,被稱為非酒精性脂肪肝,其中脂肪在肝臟內積聚并且有時引起隨時間推移而惡化的肝臟損壞(進行性肝臟損壞)。“非酒精性脂肪肝”(NAFLD)是肝臟的脂肪性炎癥,其不是由于過量飲酒引起的。其與胰島素抵抗和代謝綜合征、肥胖癥、高膽固醇和甘油三酯以及糖尿病有關,并且可能響應于最初針對其它胰島素抵抗狀態(例如,2型糖尿病)而開發的治療,如減重、二甲雙胍和噻唑烷二酮類藥物。非酒精性脂肪性肝炎(NASH)是NAFLD的最極端形式,其被視為成因未知的肝臟的硬化的主要誘因。
已知的促成NASH的其它因素包括:縮腸手術、縮胃手術或二者皆有,如空腸旁路手術或膽胰分流;長期使用飼管或接收營養的其它方法;某些藥物,包括胺碘酮、糖皮質素、合成雌激素和他莫昔芬。
NASH是可能隨時間推移而惡化的狀況(稱為進行性狀況)并可以引起肝臟瘢痕形成(肝纖維化),而導致肝硬化。“肝硬化”描述了這樣的狀況,其中肝臟細胞已經被瘢痕組織所替換。術語“肝臟的硬化”或“肝硬化”用于描述慢性肝臟疾病,其特征在于肝臟組織被纖維化瘢痕組織以及再生性結節所替換,導致肝功能的進行性喪失。肝硬化最常由脂肪肝(包括NASH以及酗酒和乙型肝炎和丙型肝炎)引起,但也可能具有未知成因。肝硬化的可能危及生命的并發癥是肝性腦病(混亂和昏迷)和食管靜脈曲張破裂出血。肝硬化歷來被認為是一旦發生即一般不可逆的,并且傳統治療著重于防止進展和并發癥。在肝硬化晚期,肝臟移植是唯一的選擇。本發明的一些實施方案可以用于限制、抑制、降低可能性或治療肝臟的硬化而無論其病因。
本發明的一些實施方案可以用于治療、預防或控制化學性肝臟損傷和肝中毒。“化學性損傷”或“急性化學性損傷”指代患者在短時間內發生的嚴重損傷,其是化學中毒(包括藥物誘發的中毒或損傷)的結果。藥物誘發的急性肝臟損傷,包括醋氨酚誘發的急性肝臟損傷,是急性肝臟損傷,其發生是暴露于藥物(例如,藥物過量)(尤其是醋氨酚中毒)的結果。
肝中毒是肝臟毒性劑或誘發肝中毒的生物活性劑造成的化學性肝臟損傷。術語“肝臟毒性劑”和“誘發肝中毒的生物活性劑”在上下文中同義使用以描述在被施用此類試劑的患者體內經常產生肝中毒的化合物。肝臟毒性劑的實例包括,例如,麻醉劑、抗病毒劑、抗逆轉錄病毒劑(核苷逆轉錄酶抑制劑和非核苷逆轉錄酶抑制劑),尤其是抗艾滋病劑、抗腫瘤劑、器官移植藥物(環孢素、他克莫司、OKT3)、抗微生物劑(抗結核、抗真菌、抗生素)、抗糖尿病藥物、維生素A衍生物、甾體藥劑(特別是包括口服避孕藥、類固醇、雄激素)、非甾體類抗炎劑、抗抑郁藥(尤其是三環類抗抑郁藥)、糖皮質素、天然產物和草藥以及替代療法(尤其是包括圣約翰草)。
肝中毒可能表現為甘油三酯積聚,其導致小滴(微泡)或大滴(大泡)脂肪肝。存在單獨類型的脂肪變性,其中磷脂積聚導致與具有遺傳性磷脂代謝缺陷的疾病(例如,泰-薩克斯病)類似的特征。
本發明的一些實施方案可以用于治療、預防或控制慢性肝臟疾病。慢性肝臟疾病以隨時間推移而逐漸破壞肝臟組織為標志。數種肝臟疾病落入此類別,包括肝硬化和肝纖維化,其中后者常常是肝硬化的前身。肝硬化是急性和慢性肝臟疾病的結果,并且其特征在于肝臟組織被纖維化瘢痕組織和再生性結節所替換,導致肝功能的進行性喪失。肝纖維化和結節再生導致肝臟的正常微觀小葉結構的喪失。肝纖維化表示由例如感染、炎癥、損傷和甚至愈合造成的瘢痕組織的生長。隨時間推移,纖維化瘢痕組織慢慢地替換正常作用的肝臟組織,導致流入肝臟的血量減少,使得肝臟不能充分處理血液中存在的營養物質、激素、藥物和毒素。肝硬化的更常見的誘因包括酗酒、丙肝病毒感染、攝入毒素以及脂肪肝,但也存在許多其它可能的誘因。慢性丙肝病毒(HCV)感染和非酒精性脂肪性肝炎(NASH)是美國慢性肝臟疾病的兩個主要誘因,據估計影響3-5百萬人。讓人擔憂的是患有肥胖癥和代謝綜合征并同時患有非酒精性脂肪肝(NAFLD)的美國公民數目(目前數目為3千多萬)持續升高,其中大約10%將最終發展為NASH。其它身體的并發癥是肝功能喪失的結果。肝硬化的最常見的并發癥是被稱為腹水的狀況,液體在腹膜腔內積聚,其可導致自發性細菌性腹膜炎的風險增加,可能造成患者過早死亡。
例如,根據本發明的一些實施方案預測對食物的升糖反應可以用于構建分析個體的個體化飲食。此類飲食可以包括例如保持相對低的血糖水平的食物清單,從而預防、降低發展風險、控制和/或治療以上綜合征或疾病中的一種或多種。
本文實施方案的方法也可以用于針對普通大眾中的健康個體從市場上現有的飲食之一或通過設計新的飲食來私人定制減重或維持重量的飲食。使用本文實施方案的數據庫,本文實施方案的方法可以任選地并優選地預測:健康或易患病個體可能被置于我們先進的個體集群之一中,允許準確預測其對未在研究期間食用的食物的反應。在一些實施方案中,所述方法可以用于甚至僅僅基于數據的一部分而將人置于集群中。
以下是對根據本發明的一些實施方案的方法更詳細的說明。
本文實施方案設想了個體特異性數據庫和組數據庫,其包含食物和相應反應之外的額外的數據。在一些實施方案中,所述數據庫中的至少一個包含一個或多個(例如,復數個)多維條目,其中每個條目均具有至少三個緯度,在一些實施方案中,所述數據庫中的至少一個包含一個或多個(例如,復數個)多維條目,其中每個條目均具有至少四個緯度,在一些實施方案中,所述數據庫中的至少一個包含一個或多個(例如,復數個)多維條目,其中每個條目均具有至少五個緯度,而在一些實施方案中,所述數據庫中的至少一個包含一個或多個(例如,復數個)多維條目,其中每個條目均具有大于五個緯度。
所述數據庫的額外的維度提供了關于分析個體的、關于其它個體的和/或關于相應個體所食用的食物的額外的信息。在下文中,“個體”總體指代這樣的個體,其可以是分析個體或來自組數據庫的另一名個體。
在本發明的一些實施方案中,所述額外的信息屬于該個體的微生物組概況或部分微生物組概況。
通常,個體的微生物組從該個體的糞便樣本中測定。
如本文所用,術語“微生物組”指代在確定環境中微生物(細菌、真菌、原生生物)、其遺傳成分(基因組)的總體。
本文實施方案涵蓋了認識到微生物標記可以倚為微生物組組成和/或活性的代替物。微生物標記包括指示微生物組組成和/或活性的數據點。因此,根據本發明,可以通過檢測微生物標記的一項或多項特征來檢測和/或分析微生物組的變化。
在一些實施方案中,微生物標記包括涉及一種或多種類型微生物和/或其產物的絕對量的信息。在一些實施方案中,微生物標記包括涉及五種、十種、二十種或更多種類型微生物和/或其產物的相對量的信息。
在一些實施方案中,微生物標記包括涉及至少十種類型微生物的存在、水平和/或活性的信息。在一些實施方案中,微生物標記包括涉及5種至100種類型微生物的存在、水平和/或活性的信息。在一些實施方案中,微生物標記包括涉及100種至1000種或更多種類型微生物的存在、水平和/或活性的信息。在一些實施方案中,微生物標記包括涉及該微生物組內基本上所有類型微生物的存在、水平和/或活性的信息。
在一些實施方案中,微生物標記包括至少五種或至少十種或更多種類型微生物或其組分或產物的水平或水平組。在一些實施方案中,微生物標記包括至少五種或至少十種或更多種DNA序列的水平或水平組。在一些實施方案中,微生物標記包括十種或更多種16S rRNA基因序列的水平或水平組。在一些實施方案中,微生物標記包括18S rRNA基因序列的水平或水平組。在一些實施方案中,微生物標記包括至少五種或至少十種或更多種RNA轉錄物的水平或水平組。在一些實施方案中,微生物標記包括至少五種或至少十種或更多種蛋白質的水平或水平組。在一些實施方案中,微生物標記包括至少五種或至少十種或更多種代謝物的水平或水平組。
16S和18S rRNA基因序列分別編碼原核生物和真核生物核糖體的小的亞單元組分。rRNA基因對于區分微生物類型尤其有用,因為盡管這些基因的序列在微生物物種間有所不同,但是這些基因具有用于引物結合的高度保守的區域。保守引物結合區域間的這種特異性允許用單組引物擴增許多不同類型微生物的rRNA基因并隨后通過擴增序列進行區分。
優選地,分析個體的微生物組概況被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的微生物組概況被包括在組數據庫中。當個體特異性數據庫包括微生物組概況時,該微生物組概況可以作為單獨的條目被收錄。當組數據庫包括微生物組概況時,該微生物組概況任選地并優選地針對每名個體收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{M})描述,其中S、F和R已在之前介紹,而{M}是個體S的微生物組概況。
微生物組概況{M}任選地并優選地包含多個值,其中每個值表示特定微生物的豐度。特定微生物的豐度可以例如通過對該微生物組的核酸進行測序而測定。然后可以通過已知的軟件分析此測序數據以測定該個體的特定微生物的豐度。
本發明人發現,相比苗條的人,肥胖個體的微生物組不夠多樣化。因此,對包括微生物組概況的數據庫的分析是有利的,因為其提供了關于分析個體與其它個體間的相似性的額外的信息,從而增加了預測能力的準確性。本發明人還發現,微生物組概況通過胰島素抵抗和腸道微生物群間的關聯而關系到血糖水平。胰島素抵抗是這樣的狀態,其中身體細胞對胰腺產生的胰島素沒有反應。因此,身體無法降低血液中的葡萄糖水平。例如,2型糖尿病與微生物組概況間存在已知關聯[Qin 等人, 2012, Nature, 490(7418):55-60]。
在本發明的一些實施方案中,所述額外的信息屬于個體的至少部分血液化學。
如本文所用的“血液化學”指代血液中溶解的或包含的任何和所有物質的濃度。此類物質的代表性實例包括但不限于:白蛋白、淀粉酶、堿性磷酸酶、碳酸氫鹽、總膽紅素、BUN、C-反應性蛋白、鈣、氯、LDL、HDL、總膽固醇、肌酐、CPK、γ-GT、葡萄糖、LDH、無機磷、脂肪酶、總蛋白質、AST、ALT、鈉、甘油三酯、尿酸和VLDL。
優選地,個體的血液化學被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的血液化學被包括在組數據庫中。當個體特異性數據庫包括血液化學時,該血液化學可以作為單獨的條目被收錄。當組數據庫包括血液化學時,該血液化學任選地并優選地針對每名個體收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{C})描述,其中S、F和R已在之前介紹,而{C}是個體S的血液化學。
本發明人發現,對包括血液化學的數據庫的分析是有利的,因為其提供了關于分析個體與其它個體間的相似性的額外的信息,從而增加了預測能力的準確性。
在本發明的一些實施方案中,所述額外的信息屬于個體的遺傳學概況。
如本文所用的“遺傳學概況”指代對大量不同基因的分析。遺傳學概況可以涵蓋該個體的整個基因組中的基因,或其可以涵蓋特定的基因亞組。遺傳學概況可包括基因組學概況、蛋白質組學概況、表觀基因組學概況和/或轉錄物組學概況。
優選地,分析個體的遺傳學概況被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的遺傳學概況被包括在組數據庫中。當個體特異性數據庫包括遺傳學概況時,該遺傳學概況可以作為單獨的條目被收錄。當組數據庫包括遺傳學概況時,該遺傳學概況任選地并優選地針對每名個體收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{G})描述,其中S、F和R已在之前介紹,而{G}是個體S的遺傳學概況。
本發明人發現,對包括遺傳學概況的數據庫的分析是有利的,因為其提供了關于分析個體與其它個體間的相似性的額外的信息,從而增加了預測能力的準確性。
在本發明的一些實施方案中,所述額外的信息屬于與個體相關的代謝組學數據。
如本文所用,術語“代謝組”指代個體內存在的代謝物的集合。人類代謝組涵蓋了天然小分子(可天然生物合成的、非聚合的化合物),其參與一般代謝反應并且是細胞的保持、生長和正常功能所需的。通常,代謝物是小分子化合物,如代謝途徑中酶的底物、此類途徑的中間體或由代謝途徑獲得的產物。
根據本發明的一些實施方案所設想的代謝途徑的代表性實例至少包括但不限于:檸檬酸循環、呼吸鏈、光合成、光呼吸、糖酵解、糖異生、磷酸己糖途徑、氧化磷酸戊糖途徑、脂肪酸的產生和β-氧化、尿素循環、氨基酸生物合成途徑、蛋白質降解途徑(如蛋白酶體降解、氨基酸降解途徑)、下列物質的生物合成或降解:脂類、聚酮類化合物(包括,例如,黃酮和異黃酮)、類異戊二烯(包括,例如,萜類、甾醇、甾體類、類胡蘿卜素、葉黃素)、糖類、苯丙素及衍生物、生物堿、苯類、吲哚、吲哚-硫化合物、卟啉類、花青素、激素、維生素、輔因子(如輔基或電子載體、木質素、芥子油苷、嘌呤、嘧啶、核苷、核苷酸及相關分子(如tRNA、微RNA(miRNA)或mRNA)。
因此,代謝組是對細胞生理狀態的直接觀測,并因而可以用于確定分析個體和其它個體間的相似性。代謝組學數據可以是代謝組或其部分,即,包含個體內存在的一些但并非全部代謝物的數據。
優選地,分析個體的代謝組學數據被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的代謝組學數據被包括在組數據庫中。當個體特異性數據庫包括代謝組學數據時,該代謝組學數據可以作為單獨的條目被收錄。當組數據庫包括代謝組學數據時,該代謝組學數據任選地并優選地針對每名個體收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{B})描述,其中S、F和R已在之前介紹,而{B}是個體S的代謝組學數據。
在本發明的一些實施方案中,所述額外的信息屬于個體的身體狀況。身體狀況任選地并優選地包括該個體正在經受或在過去曾經經受的疾病或綜合征(如果存在)的列表。身體狀況可以例如在構建或更新數據庫期間通過對相應個體進行問卷而獲得。
優選地,分析個體的身體狀況被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的身體狀況被包括在組數據庫中。當個體特異性數據庫包括身體狀況時,該身體狀況可以作為單獨的條目被收錄。當組數據庫包括身體狀況時,該身體狀況任選地并優選地針對每名個體收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{D})描述,其中S、F和R已在之前介紹,而{D}是個體S的身體狀況。
在本發明的一些實施方案中,所述額外的信息屬于個體的食物攝入習慣。食物攝入習慣可以包括該個體經常食用的食物的清單,任選地連同對應的攝入頻率。攝入頻率表示該個體在一定時間段(例如,24小時、周,等)內習慣食用該食物的次數或體積或重量的估計數值。食物攝入習慣也可以通過問卷獲得。由于食物攝入習慣通過問卷獲得,所以食物攝入習慣中的食物清單可任選地包括這樣的食物,該個體對該食物的反應是未知的。
優選地,分析個體的食物攝入習慣被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的食物攝入習慣被包括在組數據庫中。當個體特異性數據庫包括食物攝入習慣時,該食物攝入習慣可以作為單獨的條目被收錄。當組數據庫包括食物攝入習慣時,該食物攝入習慣任選地并優選地針對每名個體收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{I})描述,其中S、F和R已在之前介紹,而{I}是個體S的食物攝入習慣。
在本發明的一些實施方案中,所述額外的信息屬于個體在一定時間段內所進行的活動。此信息可以該個體在一定時間段內所進行的分立活動(睡覺、鍛煉、坐、休息,等)列表的形式提供。這些活動任選地并優選地被提供為與在所述活動期間所食用的食物和/或在所述活動期間所測量的對食物的反應(例如,血糖水平)有關。
優選地,分析個體的分立活動列表被包括在個體特異性數據庫中,而一名或多名(更優選所有)其它個體的分立活動列表被包括在組數據庫中。這些活動任選地并優選地針對數據庫中每個反應條目而被收錄。因此,例如,組數據庫條目可以由元組(S,F,R,{A})描述,其中S、F和R已在之前介紹,而{A}是個體S在反應R期間所進行的活動。類似的,個體特異性數據庫條目可以由元組(F,R,{A})描述。數據庫還可以包含這樣的條目,其包括個體所進行的與特定食物無關的活動。這是因為對于一些測得的血糖水平而言,尚不清楚這些水平是否是該個體對特定食物的反應。因此,一些組數據庫條目也可以由元組(S,R,{A})描述,而一些個體特異性數據庫條目可以由元組(R,{A})描述。
在本發明的一些實施方案中,所述額外的信息屬于與相應個體所食用的相應食物相關的特征性攝入頻率。不同于以上所定義的食物攝入習慣,特征性攝入頻率是針對個體對其的反應是已知的食物而提供的,而因此任選地并優選地針對數據庫中每個食物條目而提供。因此,個體特異性數據庫條目中的一個或多個可以元組(F,R,f)表示,組數據庫條目中的一個或多個可以元組(S,F,R,f)表示,其中S、F和R已在之前介紹,而f是與食物F相關的攝入頻率。所述攝入頻率表示個體在一定時間段(例如,24小時、周,等)內食用該食物的次數或體積或重量的數值。
在本發明的一些實施方案中,所述額外的信息屬于食物的至少部分化學組成。在這些實施方案中,個體特異性數據庫條目中的一個或多個可以元組(F,R,{L})表示,而組數據庫條目中的一個或多個可以元組(S,F,R, {L})表示,其中S、F和R已在之前介紹,而{L}是食物F的化學組成或部分化學組成。
應當理解,雖然分別描述了以上類型的額外信息,但本文實施方案設想了針對數據庫的兩種或多種類型的信息的任意組合。例如,組數據庫條目中的一個或多個可以元組(S,F,R,{X})表示,其中{X}表示這樣的數據結構,其包含下列中的兩項或多項:微生物組概況、血液化學、遺傳學概況、代謝組學數據、身體狀況、食物攝入習慣、活動和化學組成,如上所述。類似地,以上信息類型中的兩種或多種可以單獨條目的形式或以補充個體特異性數據庫的元組(F,R)的額外維度的形式被收錄。
對個體特異性數據庫和組數據庫的基于所選食物的分析任選地并優選地包括:遍歷數據庫或其一些選定部分,并搜索個體特異性數據庫中的數據對象與組數據庫中的數據對象之間的相似性。然后將所述相似性用于限定組數據庫的一部分,其窄于所搜索的數據庫或其部分。然后可以從該收窄的組數據庫部分提取對所選食物的反應。
如果組數據庫中存在對所選食物的若干種反應,則可任選地并優選地執行似然比檢驗從而提取具有更高似然性的反應作為分析個體的反應。作為另外一種選擇,可以將平均化程序應用于所找到的反應。仍作為另外一種選擇,可以重復搜索相似性從而限定組數據庫的一部分,其窄于先前所限定的部分。此過程可以迭代重復直到可以提取其它個體對所選食物的反應。
本文實施方案也設想了針對下述情況的分析程序,其中組數據庫中不存在對所選食物的反應。在此情況下,組數據庫任選地并優選地包含一名或多名其它個體對與所選食物類似的食物的反應,而該方法可以從組數據庫中選擇與所選食物類似的一種或多種食物。然后該方法可以進行以上程序中的一種或多種,就好像那些食物是在11處所選。
食物間的相似性可以基于例如食物組,其中含有相似的相同食物組的相對量的兩種食物可被視為是相似的。因此,在這些實施方案中,組數據庫包含一名或多名其它個體對含有一種或多種(例如,2、3、4、5或更多種)食物組的食物的反應,所述食物組也任選地并優選地以相同或大致相同(例如,在10%以內)的相對量被包含在所選組中。例如,當所選食物含有食物組G的某個相對量P而組數據庫不含所選食物時,該方法可以從組數據庫中選擇一種或多種食物,其食物組G的量與P相似(例如,在10%以內),并且進行以上程序中的一種或多種,就好像那些食物是在11處所選。食物組G可以是上述食物組(例如,碳水化合物、蛋白質、脂肪、礦物質、維生素等)中的任一種。應當認識到,可以使用不止一種食物組用于確定相似性。例如,當所選食物含有相應的食物組G1、G2、...、GN的相對量P1、P2、...、PN而組數據庫不含所選食物時,該方法可以從組數據庫中選擇一種或多種食物,其食物組G1的量與P1相似(例如,在10%以內)、食物組G2的量與P2相似(例如,在10%以內),以此類推。
在本發明的一些實施方案中,組數據庫包含根據預定的分類組群進行分類的數據。所述分類可以基于如上所述的數據的任何維度。在這些實施方案中,所述分析包括根據相同的分類組群對個體進行分類。然后可以基于組數據庫中的反應估計個體對所選食物的反應,所述組數據庫中的反應對應于該個體所劃歸的分類組。
根據本發明的一些實施方案的數據庫分析包括執行機器學習程序。
如本文所用,術語“機器學習”指代這樣的程序,其體現為計算機程序,被配置為從先前收集的數據中歸納出模式、規律或規則從而將合適的反應形成未來的數據,或以某種有意義的方式描述該數據。
當數據庫包含多維條目時,使用機器學習具有特別但并非專屬的優勢。
組數據庫和個體特異性數據庫可以用作訓練組,機器學習程序可以從中提取能最佳描述該數據集的參數。一旦提取了參數,即可以將其用于預測對所選食物的反應。
在機器學習中,信息可以通過監督學習或無監督學習來采集。根據本發明的一些實施方案,所述機器學習程序包含或就是監督學習程序。在監督學習中,全局或局部目標功能被用于優化學習系統的結構。換句話講,在監督學習中,存在期望的反應,系統將其用于指導學習。
根據本發明的一些實施方案,所述機器學習程序包含或就是無監督學習程序。在無監督學習中,通常不存在目標功能。具體地講,沒有為學習系統提供一套規則。根據本發明的一些實施方案的無監督學習的一種形式是無監督聚類,其中數據對象沒有被先驗地進行類別標記。
適于本文實施方案的“機器學習”程序的代表性實例包括但不限于:聚類、關聯規則算法、特征評價算法、子集選擇算法、支持向量機、分類規則、成本敏感的分類器、投票算法、堆棧算法、貝葉斯網絡、決策樹、神經網絡、基于實例的算法、線性建模算法、K-最近鄰分析、集成學習算法、概率模型、圖形模型、回歸分析法、梯度上升法、奇異值分解法和主成分分析。在神經網絡模型中,自組織映射和自適應共振理論是常用的無監督學習算法。自適應共振理論模型允許集群的數目隨問題的大小而變化并且讓用戶通過用戶定義的常數(稱為警戒參數)控制相同集群中成員間的相似程度。
以下是適于本文實施方案的一些機器學習程序的概述。
關聯規則算法是用于提取特征間有意義的關聯模式的技術。
術語“關聯”,在機器學習的語境中,指代特征間的任何相互關系,而不僅僅是預測特定類別或數值的那些。關聯包括但不限于:尋找關聯規則、尋找模式、進行特征評價、進行特征子集選擇、開發預測模型和理解特征間的相互作用。
術語“關聯規則”指代在數據庫內頻繁共現的要素。其包括但不限于:關聯模式、判別模式、頻繁模式、閉合模式和巨型模式。
關聯規則算法的慣常主要步驟是尋找在所有觀測結果中最頻繁的一組項目或特征。一旦獲得該列表,即可以從其中提取規則。
上述自組織映射是常用于高維數據的可視化和分析的無監督學習技術。典型的應用聚焦在對映射上的數據內的中心依賴性的可視化。該算法所生成的映射可以用于加快其它算法對關聯規則的識別。該算法通常包括處理單元(被稱為“神經元”)的網格。每個神經元均與特征向量(被稱為觀測結果)相關。所述映射試圖使用一組限定的模型以最佳的準確性來表示所有可用的觀測結果。同時,所述模型在網格上變得有序,使得相似的模型彼此靠近而相異的模型彼此遠離。此程序使得能夠對數據中特征間的依賴性或關聯進行識別以及可視化。
特征評價算法涉及特征排序或涉及在排序后基于特征對分析個體對所選食物的反應的影響來選擇特征。
術語“特征”在機器學習的語境中指代一個或多個原始輸入變量、一個或多個經處理的變量、或其它變量(包括原始變量和經處理的變量)的一種或多種數學組合。特征可能是連續的或離散的。
信息增益是適于特征評價的機器學習方法中的一種。定義信息增益需要定義熵,其是對訓練實例的集合中雜質的測量。通過知曉某項特征的值而發生的靶特征的熵減被稱為信息增益。信息增益可用作參數以確定特征在解釋分析個體對所選食物的反應上的有效性。根據本發明的一些實施方案,對稱不確定性是可以被特征選擇算法使用的算法。對稱不確定性通過將特征規一化到[0,1]的范圍來補償信息增益對具有更高價值的特征的偏向。
子集選擇算法依賴于評價算法和搜索算法的組合。類似于特征評價算法,子集選擇算法對特征子集進行排序。然而,不同于特征評價算法,適于本文實施方案的子集選擇算法的目標在于選擇針對分析個體對所選食物的反應具有最高影響的特征子集,同時考慮到該子集所包含特征間的冗余度。特征子集選擇的好處包括:便于數據的可視化和理解、減少測量和存儲的要求、縮短訓練和利用的時間、以及消除干擾特征以改善分類。
子集選擇算法的兩種基本方法是向工作子集中添加特征的過程(前向選擇)和從當前子集中刪除特征的過程(后向消除)。在機器學習中,前向選擇的完成與具有相同名字的統計程序是不同的。在機器學習中,通過使用交叉驗證來評價一個新特征對當前子集表現的增強,從而找到待加入當前子集中的特征。在前向選擇中,通過將各個剩余特征依次加入到當前子集中來構建子集,并同時使用交叉驗證評價所期望的各個新子集的表現。在被加入到當前子集后帶來最佳表現的特征被保留下來,而該過程繼續。當剩余可用的特征中無一能提高當前子集的預測能力時,搜索結束。此過程找出特征的局部最優集。
后向消除以類似方式實現。在后向消除中,當特征集的進一步消減無法提高子集的預測能力時,搜索結束。本文實施方案設想了前向、后向或在兩個方向上搜索的搜索算法。適于本文實施方案的搜索算法的代表性實例包括但不限于:窮舉搜索、貪婪爬山、子集隨機擾動、封裝算法、概率比賽搜索、圖式搜索、排序比賽搜索和貝葉斯分類器。
決策樹是決策支持算法,其形成在考慮輸入時所涉及步驟的邏輯路徑以做出決策。
術語“決策樹”指代任何類型的基于樹的學習算法,包括但不限于,模型樹、分類樹和回歸樹。
決策樹可以用于將數據庫或其關系分層歸類。決策樹具有樹狀結構,其包括分支節點和葉結點。每個分支節點指定一項屬性(分裂屬性)和一項基于該分裂屬性的值而進行的測試(分裂測試),并針對該分裂測試的所有可能結果分支出其它節點。作為決策樹的根的分支節點被稱為根節點。每個葉結點可以表示一個分類(例如,組數據庫的特定部分是否與個體特異性數據庫的特定部分匹配)或一個值(例如,分析個體對所選食物的預測反應)。葉結點還可以包含關于所代表分類的額外信息,如置信度分數,其測量所代表分類的置信度(即,該分類為準確的可能性)。例如,置信度分數可以是0到1的連續值,其中0分指示非常低的置信度(例如,所代表分類的指示價值非常低)而1分指示非常高的置信度(例如,所代表分類幾乎肯定是準確的)。個體對所選食物的反應可以通過如下分類:基于路徑上分支節點的分裂測試的結果向下遍歷決策樹直至到達葉結點,該葉結點提供個體對所選食物的反應。
支持向量機是基于統計學習理論的算法。根據本發明的一些實施方案的支持向量機(SVM)可以用于分類目的和/或用于數值預測。用于分類的支持向量機在本文中被稱為“支持向量分類器”,用于數值預測的支持向量機在本文中被稱為“支持向量回歸”。
SVM的特征通常在于核函數,對核函數的選擇決定了所得SVM是否提供分類、回歸或其它功能。通過應用核函數,SVM將輸入向量映射到高維特征空間中,其中可以構建決策超曲面(也稱為分離器)以提供分類、回歸或其它決策功能。在最簡單的情況下,該曲面是超平面(也稱為線性分離器),但還可以想到更復雜的分離器并可以使用核函數而應用。限定該超曲面的數據點被稱為支持向量。
支持向量分類器選擇這樣的分離器,其中該分離器距最近的數據點的距離盡可能的大,從而將與給定類別中的對象相關的特征向量點從與該類別外的對象相關的特征向量點分離開來。對于支持向量回歸,構建具有可接受誤差半徑的高維管,其使數據集的誤差最小化,并同時使相關曲線或函數的平面度最大化。換句話講,該管是圍繞擬合曲線的包層,由最靠近該曲線或曲面的數據點的集合所限定。
支持向量機的優點在于:一旦識別出支持向量,則可以從計算結果中移除剩余的觀測結果,因而極大地降低該問題的計算復雜性。SVM通常以兩個階段工作:訓練階段和測試階段。在訓練階段,生成一組支持向量用于執行決策規則。在測試階段,使用該決策規則做出決策。支持向量算法是用于訓練SVM的方法。通過執行該算法,生成參數訓練組,其包含表征SVM的支持向量。適于本文實施方案的支持向量算法的代表性實例包括但不限于序列最小優化。
最少絕對收縮和選擇算子(LASSO)算法是用于線性回歸的收縮和/或選擇算法。LASSO算法可通過正則化而使平方誤差的一般和最小化,其可以是L1范數正則化(系數的絕對值之和的界限)、L2范數正則化(系數的平方之和的界限),等等。LASSO算法可與小波系數的軟閾值化、前向逐步回歸和boosting方法相關聯。LASSO算法在下列文獻中有述:Tibshirani, R, Regression Shrinkage and Selection via the Lasso, J. Royal.Statist.Soc B., 第58卷, No. 1, 1996, 第267-288頁,其公開內容通過引用并入本文中。
貝葉斯網絡是表示變量以及變量間的條件相互依存關系的模型。在貝葉斯網絡中,變量由節點表示,而節點可以通過一個或多個連接彼此相連。連接指示兩個節點間存在關聯。節點通常具有對應的條件概率表,其用于當與該節點相連的其它節點的狀態給定時,確定該節點處于某一狀態的概率。在一些實施方案中,采用貝葉斯最優分類器算法以將后驗假設的最大值應用于新紀錄上,從而預測其分類的概率,以及從得自訓練組的其它假設中的每一者計算概率并且使用這些概率作為加權因子用于對食物的反應的未來預測。適于搜索最佳貝葉斯網絡的算法包括但不限于基于全局分數量度的算法。在構建該網絡的替代方法中,可以采用馬爾科夫毯。馬爾科夫毯隔離節點使之不受在其邊界外的任何節點影響,所述邊界由該節點的親代、其子代以及其子代的親代構成。
基于實例的算法針對每個實例生成新模型,而不是將預測基于從訓練組生成(一次)的樹或網絡。
術語“實例”,在機器學習的語境中,指代來自數據庫的實例。
基于實例的算法通常將整個數據庫存儲在存儲器中并從與那些正在測試的類似的紀錄的組中構建模型。此相似性可以例如通過最近鄰或局部加權法(例如,使用歐氏距離)來評價。一旦選定了紀錄組,即可以使用若干種不同算法(如樸素貝葉斯)構建最終模型。
現在參考圖3,其是根據本發明的一些實施方案的適用于構建數據庫的方法的流程圖。
數據庫可以從收集自單個個體或一組個體的數據來構建。當數據收集自單個個體時,所構建的數據庫可以用作上文中方法10的個體特異性數據庫(例如,數據庫22)。當數據收集自一組個體時,所構建的數據庫可以用作上文中方法10的組數據庫(例如,數據庫24)。
該方法從30開始并繼續到31,在該處于至少數天的時間內(例如,一周)監測個體體內至少一種物質的水平。該物質可以是葡萄糖、膽固醇、鈉、鉀、鈣中的一種或多種。在本發明的一些實施方案中,該物質包括至少葡萄糖,而在本發明的一些示例性實施方案中,該物質是葡萄糖。所述監測可以是連續的或在多個時間點(例如,每10分鐘或每5分鐘或每2分鐘或每1分鐘或每30秒)。優選地,所述水平是血液水平,例如,血糖水平。所述監測可以通過在整個監測期間連接至該個體(例如,與該個體的血管連通)的測量裝置進行。
該方法繼續到32,在此處監測該個體在一定時間內所食用的食物。監測所食用食物的時間段任選地并優選地與監測水平的時間段相同。
該方法繼續到33,在此處分析所監測的水平和所監測的食物以與反應(例如,對所食用的食物的至少一部分中的每種食物的升糖反應)相關聯。所述分析可以例如通過如下進行:對所食用的食物和水平在相同時間軸上作圖,并搜索可能響應于食物攝入而出現的水平變化的模式。為此,可以采用機器學習程序,如以上算法中的一種或多種。
該方法繼續到34,在此處于一個或多個數據庫(例如,組數據庫或個體特異性數據庫)中制作屬于關聯的數據庫記錄。
在35處,該方法任選地并優選地獲得屬于個體和/或食物的額外數據,并在至少一個數據庫中制作額外數據的記錄。所述額外數據可以描述任何上述類型的額外信息,包括但不限于:微生物組概況、血液化學、遺傳學概況、代謝組學數據、身體狀況、食物攝入習慣、活動和化學組成。該方法任選地并優選地繼續到36,在此處于一個或多個數據庫(例如,組數據庫或個體特異性數據庫)中制作屬于所述額外數據的數據庫記錄。優選地,將36和34應用于相同的數據庫。因此,操作36得到包含多維條目的數據庫,如上文中所進一步詳述的。該方法可以從34或36(如果執行)環回到31,而可以對另一名個體進行操作31-36中的一項或多項。當想要構建組數據庫時,則執行此回路。
在本發明的各種示例性實施方案中,該方法繼續到37,在此處任選地并優選地使用多維分析程序處理數據庫記錄,并繼續到38,在此處響應于所述分析而更新數據庫。當數據庫被用作個體特異性數據庫時,優選地在收集單個個體的數據之后開始操作37,而當數據庫被用作組數據庫時,優選地在收集多名個體的數據之后開始操作37。
所述多維分析程序任選地并優選地包括機器學習程序,如上述程序中的一種或多種。所述分析的目的在于確定數據中的模式,其允許找出數據庫中不同條目間的相似性。例如,所述分析可以包括:定義可以將數據庫條目劃歸其中的分類組,并根據該分類組將數據庫條目分類。隨后,可以根據其分類對條目進行標記。所述多維分析可以額外地或可替換地包括構建決策樹。隨后,可以更新數據庫以包含所構建的決策樹。所述多維分析可以額外地或可替換地包括提取數據庫中特征間的關聯模式和/或關聯規則。隨后,可以更新數據庫以包含所述關聯模式和/或關聯規則。所述多維分析可以額外地或可替換地包括例如使用特征評價算法對數據庫中的特征進行排序。隨后,可以更新數據庫以包含所述排序。所述多維分析可以額外地或可替換地包括從數據庫的至少一部分數據構建貝葉斯網絡。隨后,可以更新數據庫以包含所構建的貝葉斯網絡。還設想了其它類型的分析。
數據庫的處理和更新可以重復一次或多次。在這些實施方案中,該方法可以從38環回到37。
所述方法在39結束。
如本文所用,術語“約”指代 ± 10 %。
詞語“示例性”在本文中用于意指“用作示例、實例或舉例說明”。任何被描述為“示例性”的實施方案不一定被理解為優選的或優于其它實施方案和/或不一定排除結合來自其它實施方案的特征。
詞語“任選地”在本文中用于意指“在一些實施方案中提供而并不在其它實施方案中提供”。本發明的任何特定實施方案可包含多個“任選的”特征,除非此類特征相互沖突。
術語“包含/包括”(“comprises”、“comprising”、“includes”、“including”)、“具有”(“having”)及其動詞變化形式意指“包含/包括但不限于”。
術語“由…組成”意指“包括但不限于”。
術語“主要由…組成”意指組合物、方法或結構可包括額外的成分、步驟和/或部分,但僅限于所述成分、步驟和/或部分不會實質性地改變所要求保護的組合物、方法或結構的基礎和新穎特性。
如本文所用,單數形式“一個/種”和“所述”包括復數指代物,除非上下文另外清楚地指明。例如,術語“化合物”或“至少一種化合物”可包括多種化合物,包括其混合物。
在整個本申請中,本發明的各種實施方案可以范圍格式呈現。應當理解,范圍格式的描述僅僅是為了方便和簡潔,而不應當被理解為對本發明范圍的硬性限制。因此,對范圍的描述應當被視為已經具體公開了所有可能的子范圍以及該范圍內的單個數值。例如,對范圍(如1至6)的描述應當被視為已經具體公開了子范圍(如1至3、1至4、1至5、2至4、2至6、3至6等)以及該范圍內的單個數值(例如,1、2、3、4、5和6)。無論范圍的寬度如何,這均適用。
只要本文中指定了數值范圍,則其意味著包含該指定范圍內任何引用的數值(分數或整數)。短語“范圍在/在第一指定數值和第二指定數值間的范圍內”以及“范圍在/在第一指定數值“至”第二指定數值間的范圍內”在本文中可以互換使用并意味著包含所述第一和第二制定數值以及其間所有的分數和整數數值。
應當認識到,本發明的某些特征(其出于清楚的目的而在單獨的實施方案的上下文中分別描述)也可在單個實施方案中以組合形式提供。相反地,本發明的各種特征(其出于簡潔的目的而在單個實施方案的上下文中描述)也可分別提供或以任何合適的子組合提供或作為適于本發明的任何其它所述實施方案的形式提供。在各種實施方案的上下文中所述的某些特征不應當被視為那些實施方案的必要特征,除非該實施方案在缺乏那些要素的情況下無法實現。
如上所述并在以下權利要求書部分中要求保護的本發明的各種實施方案和方面將在下列實施例中找到實驗支持。
實施例
現在參考下列實施例,其與以上描述一起以非限制性方式說明了本發明的一些實施方案。
實施例1
在普通人群中,血糖水平正在迅速升高,導致糖尿病前期和葡萄糖耐受性異常的患病率急劇上升,并最終發展為II型糖尿病。飲食攝入和食物組成被視為血糖水平的核心決定因素,并很關鍵地涉及到血糖正常個體和糖尿病前期個體等的血糖穩態。糖尿病前期的飲食調整確實可以導致高血糖及其遠期并發癥的完全逆轉。然而,食物攝入在升糖反應上的個體化效應尚不清楚,因而極大地限制了通過飲食干預來有效誘導升糖控制的能力。這一主要障礙的根源在于對食物的升糖反應中的個體差異缺乏基本了解。飲食相關差異的一個關鍵但研究較少的決定因素是腸道微生物群的組成和功能。
本實施例提供了實驗與計算相結合的研究,其包括血糖正常個體和糖尿病前期個體對食物的血糖反應的大規模前瞻性分析,并解讀了微生物群對該反應的貢獻。已經表征了微生物群和數百名個體對食物攝入的升糖反應以及不同類型的升糖反應模式。已經設計出個人化的機器學習算法用于預測對食物攝入的個體化升糖反應。
方法
在特拉維夫Sourasky醫療中心召募了217名健康志愿者。其中,182名完成了整個研究并且針對他們中的每一者,已經獲得了多維概況并記錄在組數據庫中。所述概況包括:(1) 一般生活方式和健康問卷;(2) 食物頻率問卷(FFQ);(3)寬泛的血液化學狀況;(4) 一般身體參數(例如,體重、身高、腰圍、血壓);(5) 綜合宿主遺傳學概況;(6) 完整的微生物組分析(由16s rDNA分析和鳥槍宏基因組測序二者組成);(7) 一整周的血糖測量結果,使用連續血糖監測儀(CGM);(8) 樣本的綜合代謝組學分析;和(9) 一整周的記錄,包括食物攝入的次數和內容、身體活動、睡眠時間以及壓力和饑餓水平;(10) 對七種預定的測試食物的血糖反應。
通過計算機軟件分析數據庫,其目標在于:表征個體間存在的不同類型的升糖反應模式,并預測個體對食物攝入的升糖反應。
收集綜合的代謝、遺傳和微生物群概況
參與者到達特拉維夫Sourasky醫療中心。每名參與者簽署同意書,并獲得信息/樣本。以下所有的數據和樣本被冠以獨特的參與者標識符(不允許識別出參與者)而分別匿名存儲在數據庫和文庫中。
從每名參與者獲得下列信息和樣本:
1)由每名參與者填寫的一般生活方式和健康問卷,包括有關過去和現在的身體狀況和生活方式習慣(例如,鍛煉和吸煙習慣)的一組綜合問題。
2)由每名參與者填寫的食物頻率問卷(FFQ),包括有關飲食習慣和各種食物種類的日常食用的一組綜合問題。
3)寬泛的血液化學狀況(例如,膽固醇水平、全血細胞計數、HbA1c),由我們從每名參與者所抽取的血液測量。
4)由我們測量的一般身體參數(例如,體重、身高、腰圍、血壓)。
5)綜合宿主遺傳學概況,通過Illumina陣列獲得,應用于從參與者在剛抵達中心時所抽取的血液中提取的DNA上,測量了約700,000種不同的單核苷酸多態性(SNP)。
6)綜合的微生物群分析,通過對從每名參與者在他/她剛抵達中心時提供的糞便樣品中提取的DNA同時進行16S和宏基因組分析而獲得。
7)一整周的連續血糖測量結果,通過使每名參與者在一整周中與iPro2連續血糖監測儀(CGM)(其每五分鐘測量一次血糖水平)相連而測得。一名參與者的一個測量日的實例示于圖4中。圖4中所示的是一名研究參與者在七個連接日期間的原始血糖測量結果的實例。用箭頭標明了進餐次數;還標明了睡眠時間。
8)樣本的完整代謝組學分析,通過對所收集的糞便和血液樣品應用LC-MS和GC-MS質譜分析而進行。
9)一整周的活動記錄,包括每名參與者在連接周內所進行的并且可能影響他/她血糖水平的活動的全部次數和類型(例如,全部食物攝入的內容和次數、身體活動的次數和強度、睡眠次數、以及壓力和饑餓水平)。
10)對七種預定的測試食物的血糖反應。每天早晨,每名參與者食用由工作人員提供的七種測試餐食(純白面包食用兩次、純白面包加30g黃油食用兩次、50g葡萄糖加250g水食用兩次、以及50g果糖加250g水食用一次)中的一種,其包含精確的50g可用碳水化合物。
結果
對相同食物的血糖反應的個體間偏差
檢查了不同個體對相同食物具有的不同反應的程度。為此,比較了個體對他們每人在研究中的每天早晨被要求食用并由工作人員供應的七種預定的測試食物的血糖反應。對于所檢查的全部類型的測試食物,個體對相同食物的反應均存在差異。對于50g可用碳水化合物(甚至對于純葡萄糖)的食物激發,一些個體幾乎不表現出升糖反應,而其它個體則表現出非常明顯的反應。
圖5A-F示出了研究參與者對葡萄糖(圖5A)、面包(圖5B)和面包加黃油(圖5C)的血糖反應的柱狀圖,其中所食用的每種食物的量被設定為總碳水化合物含量為50克。還示出了三名具有高血糖反應的個體和三名具有低血糖反應的個體對葡萄糖(圖5D)、面包(圖5E)和面包加黃油(圖5F)的飯后反應的實例。注意到,平均而言,黃油降低了升糖反應,但這僅僅是針對該個體子集的情況。
本發明人令人驚奇地發現,不同個體間對食物的反應的差異相當大。不同個體間的差異示于圖5G中,其示出了不同個體對葡萄糖、面包和面包加黃油的反應的聚類。圖5G中的每一行對應一名個體,而彩色條目表示對每種食物激發的升糖反應的強度(紅色表明更高的反應,而綠色表明更低的反應)。如圖所示,在每個集群內存在具有相似反應的個體的集群,在這些個體中,約10%對面包加黃油反應最強烈,約30%對面包反應最強烈,而約60%對純葡萄糖反應最強烈。
經驗證,所述差異不是由于連續血糖測量結果的不準確性,因為:(1) 在整個群體中測得的平均血糖反應與這些食物的公布的升糖反應(其也是按群體平均計算)非常吻合,并且(2) 通過比較兩個重復測量結果(其各自被要求針對三種不同類型的預定的測試食物進行),發現在這些個體內其對相同食物的反應具有高度可重復性。圖6A-C示出了如根據本發明的一些實施方案進行的研究過程中獲得的葡萄糖(圖6A)、面包(圖6B)和面包加黃油(圖6C)的血糖反應的柱狀圖,其中所食用的每種食物的量被設定為總碳水化合物含量為50克。每個點表示一名研究參與者。對于所述三種不同類型的測試食物,重復間的相關性為0.76-0.78。
預測個體對食物的個人反應
為了評估預測未見過的餐食的能力,采用了交叉驗證方案。將約8,000種餐食(獲得針對其的血糖反應測量結果)隨機分入10個大小相等的組。使用模型(其參數僅使用其它9個餐食組中的餐食而習得)預測各組中餐食的血糖反應。因此,在模型學習階段期間不會觀測到其預測被評估的每種餐食,從而代表了對本文實施方案的預測能力的真實評估。
比較了三種不同的模型,如下:
1)普適(One size fits all)的僅基于碳水化合物的模型。此模型僅使用各餐食中的一項特征,即該餐食中含有的碳水化合物的量,其原理是:碳水化合物是升糖反應的主要已知決定因素。
2)普適(One size fits all)的多項餐食特征模型。此模型擴大了僅基于碳水化合物的模型以包含10項額外的參數,其組成如下:餐食的重量、卡路里數、蛋白質的量、脂肪的量、餐食的碳水化合物分數、餐食的蛋白質分數、餐食的脂肪分數、碳水化合物對蛋白質的對數比、碳水化合物對脂肪的對數比、以及餐食中食物組分的數目。
3)個人化模型。此模型使用模型2的參數,但還另外包含:
a)三項個人臨床參數,由年齡、血液中糖化血紅蛋白的水平(HbA1c)和血液中磷的水平組成。
b)來自先前餐食(在過去10小時內食用的餐食)的四項參數,由先前餐食中的卡路里量、碳水化合物量、碳水化合物對脂肪的比率以及先前餐食后所過去的時間本身組成。
僅基于訓練數據(即,用于構建預測因子的餐食,而非被預測的單列出的餐食)而將研究個體聚類到三個不同的組中。然后針對所述三個不同人群組中的每一者構建單獨的模型。這些組是基于每個人所具有的餐食中碳水化合物的量與他/她的血糖反應之間的相關性而定義的。本發明人注意到碳水化合物的量與血糖反應間的這種關系在個體間變化很大,并因而試圖使用此特征來針對各個子群體或集群分別構建單獨的預測因子。圖7A-E展示了此模型的原理,其中可以清楚看到在碳水化合物的量與血糖反應之間的關系中人群間的高度差異。圖7A-E中所示的是所有研究參與者的餐食中的碳水化合物量與升糖反應間的相關性柱狀圖(圖7A)、在碳水化合物量與升糖反應間具有低相關性的兩名參與者的實例(圖7B和7C)和具有高的此類相關性的兩名參與者的實例(圖7D和7E)。
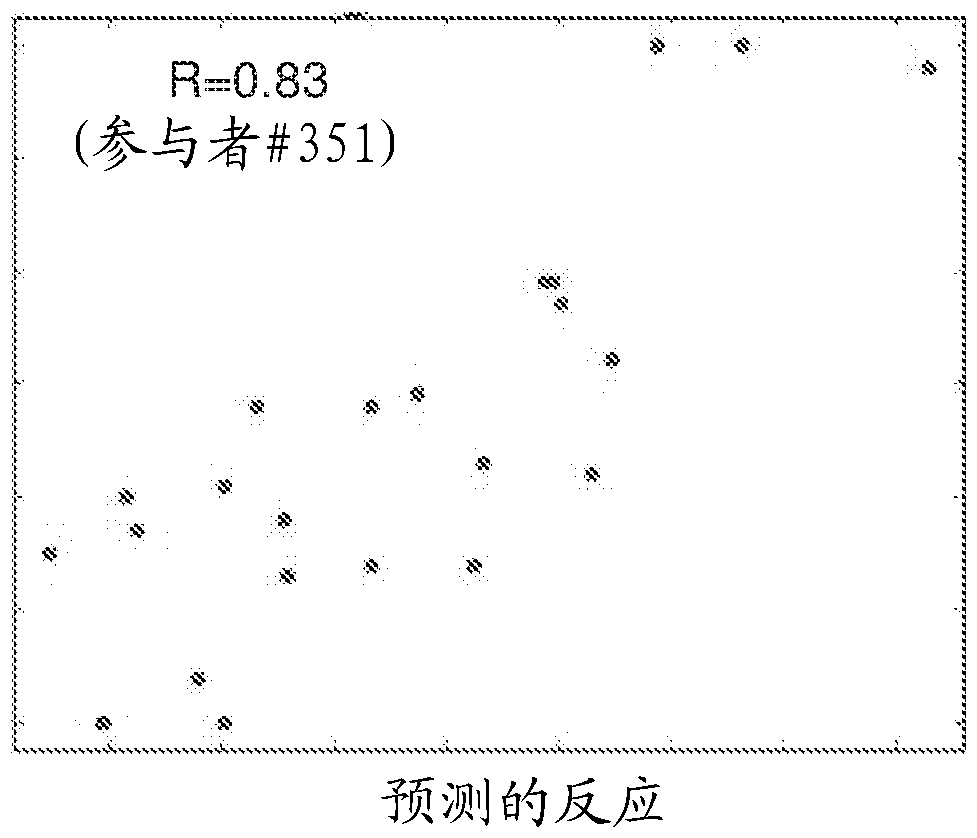
這些模型是使用L1(絕對值之和)正則化的LASSO算法的線性模型而習得的。在所有被預測的餐食中(回想一下,每種餐食均使用基于將其排除在外的餐食而習得的模型來預測),模型1、2和3分別達到0.35、0.36和0.44的預測相關性。所有模型的預測值均為正值,這證明了使用本文實施方案的組數據庫來預測對未見過的餐食的升糖反應的效力。使用模型3帶來預測準確性的提升,這證明利用個體的個人參數私人定制的預測因子可以導致性能的極大提升。在具有最高的碳水化合物含量與血糖反應間相關性的兩個個體集群上,該模型預測了單列的未見過的餐食,其中集群1和2的相關性分別為0.50和0.51。這些集群統共占全部個體的幾乎50%,證明對于幾乎半數的研究參與者(事先確定的),所述預測因子實現了非常好的預測。
這些結果匯總于圖8A-D中,其示出了個體升糖反應的私人定制的預測因子。圖8A示出了使用餐食的一般參數(模型1和2)或還使用個體的個人參數(模型3)的三種模型之間預測單列的未見過的餐食的相關性的比較。還示出了針對用于模型3中的個體集群中的每一者的預測。圖8B-D示出了對三個個體集群的得自私人定制的模型(模型3)的預測,所述三個個體集群是基于各集群中個體所表現出的其餐食中碳水化合物的量與其血糖反應間的關系而定義的。注意到個體集群1和2中0.5和0.51的高相關性,所述個體集群表現出餐食中碳水化合物含量與血糖反應間的高相關性。
結論
本實施例證明了本文實施方案的方法在預測個體對食物攝入的升糖反應上的實用性。本實施例顯示,針對個體參數私人定制的預測因子可以實現性能改善。本實施例顯示,對于由大致半數人口組成的并且其身份可以事先確定的個體子集而言,所述預測更加準確。這些個體具有這樣的特質:(相比人口中的其它個體)其表現出餐食中碳水化合物的量與血糖反應間的高度相關性。
實施例2
使用決策樹通過隨機boosting重新分析上文實施例1中收集的數據。結果示于圖9A-G中。
圖9A示出了對應于5個不同的血糖水平預測中每一者的實際測得的血糖反應的箱線圖。中心線是中值,而頂部和底部的橫杠分別表示75和25百分位數。還指明了全部餐食的總體相關性(R=0.56)。
圖9B示出了根據本發明的一些實施方案所預測的全部7072種餐食。示出的是預測的血糖反應(橫坐標)和所測得的反應(縱坐標)之間的比較。還示出的是總體相關性(R=0.56)和指示出移動窗口平均值(100個連續預測)的線。
圖9C示出了不同相關性預測水平的參與者數目的柱狀圖。
圖9D-G示出了來自典型預測的兩名參與者的預測反應和測得反應的比較(圖9D和9E),以及兩名最佳預測的參與者的預測反應和測得反應的比較(圖9F和9G)。
實施例3
本實施例證明了根據本文所述的實施方案的數據庫預測個體對食物的反應的能力,其使用組數據庫(包含其它個體對食物的反應)和個體特異性數據庫(包含描述該個體的數據但不包含對任何食物的任何反應)。數據和在學習階段對所收集數據的分析與實施例2中是相同的。在預測階段,將分析個體的血糖水平數據從數據庫中移除。所述個體特異性數據庫包含描述以下的數據:生活方式、健康、血液化學和食物攝入習慣(包括該個體慣常食用的食物的清單連同對應的攝入頻率)。所述生活方式、健康和食物攝入習慣通過問卷收集。
圖10A示出了對應于5個不同的血糖水平預測中每一者的測得的血糖反應的箱線圖。注釋和標記與
圖9A中相同。如圖所示,全部餐食的總體相關性為R=0.46。
圖10B示出了根據本發明的一些實施方案所預測的全部7072種餐食。注釋和標記與
圖9B中相同。
實施例4
本實施例說明了可以如何使用數據庫預測個體對食物的升糖反應。
材料和方法
16名升糖反應異常的參與者和健康參與者參加了為期三周的飲食干預實驗。第一周是分析周,其中計算了兩種個人化的測試飲食:(1) 一整周的個人化飲食,其預測具有“好的”(低)飯后血糖反應;和(2) 一整周的個人化飲食,其預測具有“不好的”(高)飯后血糖反應。本發明人評價了相比在所述“不好的”周給予的個人化飲食,所述“好的”周的個人化飲食是否確實引發了更低的血糖反應。
在實驗前,膳食學家制定了為期6天的私人定制的飲食,如下:每名參與者決定他/她在一天中吃幾餐和攝入多少卡路里。6天中所有的餐食都是不同的,并且每天食用相同數量的餐食和卡路里,其中餐食之間的間隔為至少3小時。餐食的內容由參與者決定以符合其口味和正常飲食。例如,參與者可能選擇一天食用5種餐食類別,如下:300卡路里的早餐、200卡路里的早午餐、500卡路里的午餐、200卡路里的零食和800卡路里的晚餐。該參與者針對每種餐食類別(所述實例中的5種餐食類別:早餐、早午餐、午餐、零食和晚餐)在膳食學家的幫助下就6種不同的選擇作出決定,以確保所有的早餐都是等卡路里的,其最大偏差為10%。
實驗從對該參與者采集血樣并進行人體測量開始,將該參與者連接至連續血糖監測儀并開始所述6天飲食,同時記錄在研究期間所有食用的餐食。在實驗的第7天,該參與者進行標準(50g)口服葡萄糖耐受測試,其后他在那一整天中正常攝食。被稱為“混合周”的第一周將該參與者暴露于各種食物,此做法隨后將確定哪種餐食相對“好”和“不好”,即哪種餐食分別導致低和高血糖反應。使用連續血糖監測儀(Medtronic iPro2)以密集的5分鐘時間間隔監測血糖水平。測量了每種餐食的血糖上升以及血糖增量的曲線下面積(AUC)。按從低到高的反應選擇餐食,其中選擇了每個餐食類別中最好和最差的兩種餐食并標記為好的餐食和不好的餐食。
在選定好的和不好的餐食之后,該參與者繼續進行實驗的另外兩周,即測試周。“好的周”僅由好的餐食構成,而“不好的周”則僅由經預測會引發“不好的”(高)血糖反應的餐食構成。一周包括6天的飲食和一天的50克葡萄糖耐受測試,如上所述。周的次序是隨機選擇的,并且參與者和膳食學家均不知曉周的次序。三周后,比較各周之間的血糖水平。
到目前為止,16名個體完成了實驗,其中10名具有升糖反應異常,而6名是健康的。
結果
“好的”和“不好的”餐食被正確地歸類:據發現,在所述兩個測試周中所測試的餐食中的絕大多數顯示出與預測(低/高)相符的血糖反應。
相比“不好的”周,在“好的”周中的餐食之后觀察到了平均AUC的顯著改善。此結果對于健康個體和葡萄糖耐受性異常個體均成立,其中在后者組中,“好的”周與“不好的”周之間的差別更大(圖11)。
該結果還顯示,餐后的血糖反應顯示出晝夜變化規律(圖12)。當通過一個類別中所有餐食的平均AUC反應進行線性擬合時,可以看到早餐AUC趨勢相對低,然后是午餐,而晚餐具有最高的AUC趨勢。在通過餐食中的碳水化合物或卡路里規一化后,此趨勢依然保持(圖13A-B)。
參考文獻
1.Danaei, G. 等人,National, regional, and global trends in fasting plasma glucose and diabetes prevalence since 1980: systematic analysis of health examination surveys and epidemiological studies with 370 country-years and 2.7 million participants.Lancet 378, 31-40, doi:10.1016/S0140-6736(11)60679-X (2011).
2.Li, G. 等人,The long-term effect of lifestyle interventions to prevent diabetes in the China Da Qing Diabetes Prevention Study: a 20-year follow-up study.Lancet 371, 1783-1789, doi:10.1016/S0140-6736(08)60766-7 (2008).
3.Gerstein, H. C. 等人,Annual incidence and relative risk of diabetes in people with various categories of dysglycemia: a systematic overview and meta-analysis of prospective studies.Diabetes research and clinical practice 78, 305-312, doi:10.1016/j.diabres.2007.05.004 (2007).
4.Tabak, A. G. 等人,Trajectories of glycaemia, insulin sensitivity, and insulin secretion before diagnosis of type 2 diabetes: an analysis from the Whitehall II study.Lancet 373, 2215-2221, doi:10.1016/S0140-6736(09)60619-X (2009).
5.Is fasting glucose sufficient to define diabetes: Epidemiological data from 20 European studies.The DECODE-study group.European Diabetes Epidemiology Group.Diabetes Epidemiology: Collaborative analysis of Diagnostic Criteria in Europe.Diabetologia 42, 647-654 (1999).
6.Gong, Q. 等人,Long-term effects of a randomised trial of a 6-year lifestyle intervention in impaired glucose tolerance on diabetes-related microvascular complications: the China Da Qing Diabetes Prevention Outcome Study.Diabetologia 54, 300-307, doi:10.1007/s00125-010-1948-9 (2011).
7.Meyer, K. A. 等人,Carbohydrates, dietary fiber, and incident type 2 diabetes in older women.The American journal of clinical nutrition 71, 921-930 (2000).
8.Lau, C. 等人,Dietary glycemic index, glycemic load, fiber, simple sugars, and insulin resistance: the Inter99 study.Diabetes care 28, 1397-1403 (2005).
9.Vega-Lopez, S., Ausman, L. M., Griffith, J. L. & Lichtenstein, A. H. Interindividual variability and intra-individual reproducibility of glycemic index values for commercial white bread.Diabetes care 30, 1412-1417, doi:10.2337/dc06-1598 (2007).
10.Wolever, T. M. 等人,Determination of the glycaemic index of foods: interlaboratory study.European journal of clinical nutrition 57, 475-482, doi:10.1038/sj.ejcn.1601551 (2003).
11.Williams, S. M. 等人,Another approach to estimating the reliability of glycaemic index.The British journal of nutrition 100, 364-372, doi:10.1017/S0007114507894311 (2008).
12.Shulzhenko, N. 等人,Crosstalk between B lymphocytes, microbiota and the intestinal epithelium governs immunity versus metabolism in the gut.Nature medicine 17, 1585-1593, doi:10.1038/nm.2505 (2011).
13.Everard, A. 等人,Responses of gut microbiota and glucose and lipid metabolism to prebiotics in genetic obese and diet-induced leptin-resistant mice.Diabetes 60, 2775-2786, doi:10.2337/db11-0227 (2011).
14.Musso, G., Gambino, R. & Cassader, M. Interactions between gut microbiota and host metabolism predisposing to obesity and diabetes.Annual review of medicine 62, 361-380, doi:10.1146/annurev-med-012510-175505 (2011).
15.Turnbaugh, P. J. 等人,A core gut microbiome in obese and lean twins.Nature 457, 480-484, doi:10.1038/nature07540 (2009).
16.Turnbaugh, P. J. 等人An obesity-associated gut microbiome with increased capacity for energy harvest.Nature 444, 1027-1031, doi:10.1038/nature05414 (2006).
17.Claesson, M. J. 等人,Gut microbiota composition correlates with diet and health in the elderly.Nature 488, 178-184, 10.1038/nature11319 (2012)。
盡管本發明已經結合其具體實施方案進行了描述,但顯然許多替代形式、修改形式和變型形式對于本領域技術人員將是顯而易見的。因此,其旨在包含落入所附權利要求書的精神和寬廣范圍內的所有此類替代形式、修改形式和變型形式。
本說明書中提及的所有出版物、專利和專利申請均全文引入本說明書作為參考,其程度如同每個單獨的出版物、專利或專利申請被專門并單獨指明并入本文作為參考。另外,本申請中對任何參考文獻的引用或確認不應解釋為承認:這樣的參考文獻可作為本發明的現有技術。就節標題的使用程度而言,其不應理解為一定是限制性的。
- 還沒有人留言評論。精彩留言會獲得點贊!