基于局部紋理特征的人群密度譜估計方法與流程
本發明涉及視頻圖像處理技術,特別涉及對大型公共場所人流密度實時檢測的技術。
背景技術:
以往的人群密度估計方法大多數都是提取圖像的全局特征并對整幅圖像的人群密度做估計。然而,這種方法具有兩個嚴重的缺點:1.行人可能只出現在圖像的某一部分區域,例如:在包含道路的圖片中,行人可能只出現在人行道上;2.在實際應用中,人們更加關心的是特定區域的人群密度,例如:在電影院,入口處的人群密度比坐在等候區域的人群密度更重要。所以,為了更好地適應于各種應用場景,就必須對圖像的人群密度譜進行估計。
人群密度譜估計需要綜合考慮圖像的所有局部和空間信息,通過不同的顏色或者亮度將密度結果展示出來。密度譜就像是一幅熱量圖,顏色深或亮度大的區域代表高密度區域,顏色淺或亮度低的區域則對應著低密度區域,這樣的展示結果讓監測人員對監控畫面中的人群分布情況一目了然。基于密度譜,我們還可以做更多更深入的智能研究。
傳統的密度譜估計方法首先提取大量的圖像局部塊特征,例如SIFT;再通過k-means等聚類方法對所有圖像局部特征進行聚類,由此得到圖像的“詞袋模型”(Bag of Words)或者“碼書”(codebooks);然后提取每個像素點的“詞袋模型”特征表達;最后學習得到該特征與像素點人群密度之間的回歸模型,由此估計出整幅圖像的人群密度譜。這一類方法過于依賴場景,導致訓練出的模型往往泛化能力不夠,并且需要提取很復雜的特征集,如Bow-Sift等。
目前較好的方法是提取圖像的若干塊,利用所有圖像塊的特征與該圖像塊內行人分布的向量集訓練得到一個隨機森林。在檢測階段,首先提取圖像塊的特征,然后利用訓練好的隨機森林預測該塊的行人分布標簽,再利用視頻前后幀之間的密度先驗概率得到每一個圖像塊的密度,最后每一個像素點的密度由所有包含該點的圖像塊的密度加權得到。該方法由于提取的特征塊數量較多、特征維度較高,且采用隨機森林這樣的樹狀結構存儲特征,所以在內存和時間上都消耗非常大,導致很難達到實時性要求。
真實監控場景下的人群密度譜估計問題,面向的場景是校園、車站、商場等公共場所,在這些場景中,行人可能會出現在視頻圖像中的任何位置。現實生活中監控場景復雜多變,密度譜估計算法必須要滿足實時性要求,并且需要對場景具有無依賴性,同時還能夠直觀反映出當前監控場景下的行人分布及擁擠情況。
技術實現要素:
本發明所要解決的技術問題是,提供一種不依賴場景且能滿足實時性要求的人群密度譜估計方法。
本發明為解決上述技術問題所采用的技術方案是,基于局部紋理特征的人群密度譜估計方法,包括以下步驟:
1)訓練步驟:
1-1)采集視頻樣本圖片,根據單位面積內包含的行人數量對樣本設置人群密度分類標簽;設置各人群密度分類標簽對應的得分;
1-2)提取樣本圖片的紋理特征,將樣本圖片的紋理特征與對應的人群密度分類標簽輸入SVM分類器進行分類器訓練。
2)測試步驟:
2-1)利用SIFT關鍵點檢測器提取出候選關鍵點,再在候選關鍵點中通過間隔采樣選取出關鍵點;以每個關鍵點為中心,提取出固定大小的鄰域圖像塊,提取鄰域圖像塊的紋理特征;
2-2)將鄰域圖像塊的紋理特征輸入SVM分類器進行分類,得到該圖像塊的一個人群密度分類標簽,并得到該人群密度分類標簽對應得分;
2-3)計算鄰域圖像塊內的所有像素點的密度得分,密度得分為鄰域圖像塊的SVM預測得分與距離加權因子的乘積;
像素點的距離加權因子w(i,j)為
其中,p(i,j)代表(i,j)位置的像素點,dist(p(i,j),C)代表該像素點與關鍵點的歐式距離;
2-4)遍歷檢測圖像中每個像素點所在的所有鄰域圖像塊,將對應的像素點密度得分進行累加得到每個像素點的最終密度得分;
2-5)將每個像素點的最終密度得分歸一化到0到255之間,再將最終密度得分對應成灰度值,得到一幅灰度密度譜圖;或將最終密度得分對應成RGB三個通道值,得到一幅彩色密度譜圖。
本發明采用SIFT關鍵點檢測器可以有效檢測出圖像中行人所在的區域,使用SVM分類器對每個關鍵點區域進行分類,有效得到各個關鍵點區域的人群密度。另外,本發明還提供一種紋理特征的提取方式,通過提取局部紋理模式的灰度共生矩陣特征來表達圖像塊的行人密度,簡單有效。
本發明的有益效果是,具有非常高的實用性和可行性,并且能夠滿足實時性要求。
附圖說明
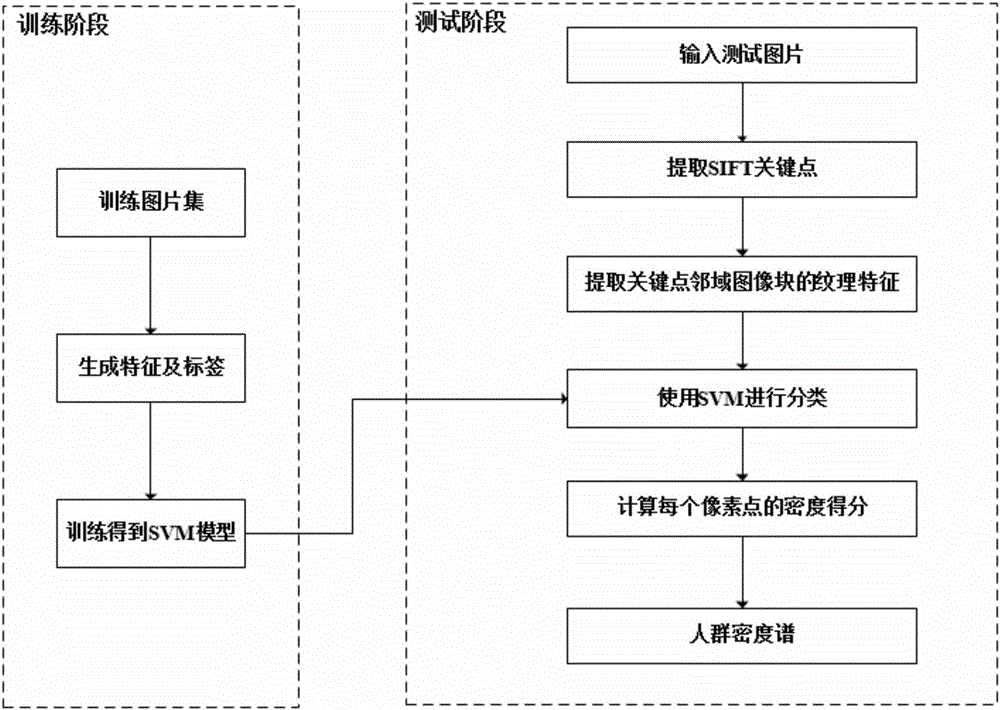
圖1:本發明的人群密度譜估計流程示意圖
具體實施方式
本發明需要用到的現有技術包括SIFT關鍵點檢測器、SVM分類器,所采用的特征為局部二值模式LBP、局部三值模式LTP、灰度共生矩陣特征。
根據單位面積內包含的行人數量多少,我們將人群密度分為五種類型:非常低、低、中等,高,非常高。這種分類依據來自于Polus提出的人群可自由活動水平概念,Polus將人群密度分為四種水平:自由人流、受限制人流、密集人流、擁堵人流。
本發明主要工作分為兩個階段:訓練階段和測試階段,如圖1所示。
其中訓練階段可以分為以下三個步驟:
步驟一、對真實監控場景下拍攝好的大量視頻樣本進行采樣,對于五種類型的人群密度,分別提取等量的訓練圖片。事先利用攝像頭在校園教學樓以及圖書館門前廣場拍攝得到大量的視頻,通過裁剪,挑選出非常低、低、中等、高、非常高密度的圖片各600張,每張圖片大小都是63×63,將這3000張圖片分別標上對應的標簽,由此構成訓練圖片集。
步驟二、提取特征:對訓練集中的每一張圖片,可以分為以下五步來提取其紋理特征。
1.計算原圖像對應的梯度圖像;
2.對于原圖像中每個像素點,提取其3×3鄰域,計算得到對應的局部三值模式LTP三值碼(-1,0,1),并分解成正局部二值模式LBP二值碼(0,1)以及負LBP二值碼(-1,0)。對于正LBP碼,通過順時針的方式計算得到其對應的LBP值;對于負LBP碼,通過逆時針的方式計算得到其對應的LBP值,在這個計算過程中,負LBP碼中的-1被當作+1處理。經過計算,原圖像每一個像素點都得到了正負LBP值,由此便得到了對應的正負兩幅LBP圖。
3.計算梯度圖像的每個像素點對應的LBP值,由此得到梯度LBP圖;
4.計算正LBP圖、負LBP圖和梯度LBP圖的灰度共生矩陣;
5.對正LBP圖、負LBP圖和梯度LBP圖的灰度共生矩陣分別計算其能量、對比度、一致性和熵,將各灰度共生矩陣對應的能量、對比度、一致性和熵進行串聯得到特征向量(能量,對比度,一致性,熵);最后將正LBP圖、負LBP圖和梯度LBP圖的灰度共生矩陣的特征向量進行串聯構成了圖像特征(正LBP特征向量,負LBP特征向量,梯度LBP特征向量)。其中,計算能量、對比度、一致性、熵的方法均為現有,不在此贅述。
步驟三、訓練支持向量機SVM分類器:將步驟二中得到的3000個特征向量以及對應的標簽用來訓練SVM分類器。
測試階段分為以下五個步驟:
步驟一、提取關鍵點:首先,使用尺度不變特征變換SIFT關鍵點檢測器檢測到若干候選關鍵點;由于邊界關鍵點所在區域往往沒有包含任何行人,因此去掉以后對實際效果并沒有多大影響,故去除一些邊界上的關鍵點;最后對于關鍵點較多的情況,我們選擇間隔采樣的方式,只保留部分關鍵點。對于關鍵點是否屬于較多的情況的判斷可通過與閾值比較的方式進行。
步驟二、提取關鍵點鄰域的紋理特征:首先,對于每個關鍵點,提取其大小為63×63的鄰域圖像塊,采用與訓練階段相同的方式,計算得到該鄰域圖像塊的紋理特征。
步驟三、使用SVM模型進行分類:對于每個關鍵點鄰域圖像塊,利用訓練階段訓練好的SVM分類模型,對這些鄰域圖像塊進行分類,對應5個密度類別:非常低、低、中等、高、非常高分別對應打分:1,2,3,4,5。
步驟四、計算每個像素點的密度得分:
對于每個關鍵點鄰域圖像塊內的所有像素點計算密度得分,密度得分等于鄰域圖像塊的SVM預測得分與距離加權因子的乘積,距離加權w(i,j):
其中,w(i,j)代表該像素點的加權因子,p(i,j)代表(i,j)位置的像素點,dist(p(i,j),C)代表該像素點與關鍵點的歐式距離。
遍歷每個像素點所在的所有鄰域圖像塊,將對應的像素點密度得分進行累加得到每個像素點的最終密度得分;
步驟五、將每個像素點的最終密度得分歸一化到0到255之間,將得分對應成灰度值,得到一幅灰度密度譜圖;或將最終密度得分對應成RGB三個通道值,得到一幅彩色密度譜圖。
通過以上步驟便可以完成對一幅輸入圖像或視頻幀的行人密度譜計算。之后,可以對得到的人群密度譜進行應用。例如,設定密度閾值,當某區域的人群密度超過該閾值時,則可以給系統發出警告信息,以提示監控人員該區域可能存在人群過于擁擠情況;同時分析密度譜的變化情況,當某區域人群密度快速增大,則表示該區域可能存在人群突然聚集現象;通過人群密度譜積分圖,還可以得到任意區域的人數近似估計。
- 還沒有人留言評論。精彩留言會獲得點贊!