一種分布式數據庫的擴容方法及裝置與流程
本發明屬于分布式數據庫領域,尤其是涉及一種分布式數據庫的擴容方法及裝置。
背景技術:
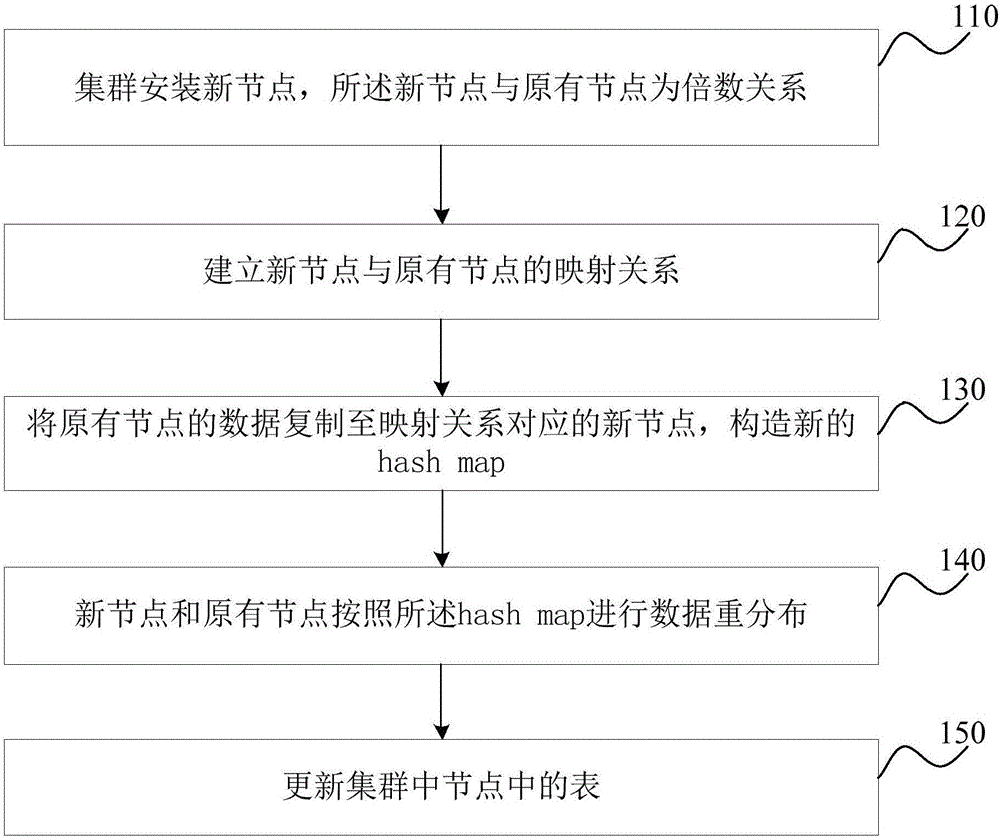
:分布式數據庫系統通常使用較小的計算機系統,每臺計算機可單獨放在一個地方,每臺計算機中都可能有DBMS的一份完整拷貝副本,或者部分拷貝副本,并具有自己局部的數據庫,位于不同地點的許多計算機通過網絡互相連接,共同組成一個完整的、全局的邏輯上集中、物理上分布的大型數據庫。在客戶的業務場景中,當前集群滿足不了用戶的業務需求而需要對集群進行擴容時,需要在給定的時間窗口完成集群的擴容。目前市場上主流的分布式數據庫系統GBaseMPPCluster、vertica、GreepPlum一般采用一致性的hash方式來分布集群中的數據,經過hash分布的表,在擴容時,需要逐條進行hash值的計算,然后根據計算的hash值來搬移部分的數據,按行遷移數據造成遷移性能較低。GBaseMPPCluster采用的一致性hash算法是按照65536個hash桶來對應到集群的實際物理節點(簡稱為集群的hashmap),理論上集群支持的最大節點數為65536,帶來的缺陷是hash桶數太多,導致多個hashkey對應到一個節點,數據擴展和縮容時必須讀取所有的數據并且計算hash后按行來重分布數據,導致重分布存在以下問題:1.每個節點必須計算所有數據,并按照hash分布數據到所有節點上;2.擴容性能較低;3.delete行的空間不能釋放。技術實現要素:本發明實施例提供了一種分布式數據庫的擴容方法及裝置,以解決分布式數據庫擴容時數據運算量大且擴容性能低的技術問題。一方面,本發明實施例提供了一種分布式數據庫的擴容方法,包括:集群安裝新節點,所述新節點與原有節點為倍數關系;建立新節點與原有節點的映射關系;將原有節點的數據復制至映射關系對應的新節點;構造新的hashmap;新節點和原有節點按照所述hashmap進行數據重分布;更新集群中節點中的表。進一步的,所述新節點和原有節點按照所述hashmap進行數據重分布,包括:原有節點保留原表的一半數據;與原有節點對應的新節點插入所述原有節點的另一半數據。進一步的,所述方法還包括:刷新所有節點的元數據,以使得所有節點實現提供對外服務。更進一步的,所述數據包括:二進制文件。另一方面,本發明實施例還提供了一種分布式數據庫的擴容裝置,包括:安裝單元,用于安裝新節點,所述新節點與原有節點為倍數關系;映射關系建立單元,用于建立新節點與原有節點的映射關系;構造單元,用于將原有節點的數據復制至映射關系對應的新節點,構造新的hashmap;重分布單元,用于使新節點和原有節點按照所述hashmap進行數據重分布;更新單元,用于更新集群中節點中的表。進一步的,所述重分布單元用于:原有節點保留原表的一半數據;與原有節點對應的新節點插入所述原有節點的另一半數據。進一步的,所述裝置還包括:刷新單元,刷新所有節點的元數據,以使得所有節點實現提供對外服務。更進一步的,所述數據包括:二進制文件。本發明實施例提供的分布式數據庫的擴容方法及裝置,在集群安裝新節點與原有節點為倍數關系時,通過建立新節點與原有節點的映射關系,構造hashmap,并對數據重分布,減少了節點數據的計算量,實現了強擴容性能,并能快速釋放刪除行的存儲空間。附圖說明為了更清楚地說明本發明實施例的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。圖1是本發明實施例一提供的分布式數據庫的擴容方法的流程示意圖;圖2是本發明實施例二提供的分布式數據庫的擴容方法的流程示意圖;圖3是本發明實施例三提供的分布式數據庫的擴容方法的流程示意圖;圖4是本發明實施例四提供的分布式數據庫的擴容裝置的結構示意圖。具體實施方式下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。實施例一圖1為本發明實施例一提供的分布式數據庫的擴容方法的流程圖,本實施例可適用于在集群安裝新節點與原節點數量為倍數關系時,對分布式數據庫進行擴容的情況,該方法可以由分布式數據庫的擴容裝置來執行,該裝置可由軟件/硬件方式實現,并可集成于分布式數據庫系統的管理節點中。S110,集群安裝新節點,所述新節點與原有節點為倍數關系。在實際的項目中,大部分分布式系統中節點按照比例關系,成倍的進行擴容和縮容,例如由n個節點擴容到2n個節點。或者由n個節點擴容到3n個節點。S120,建立新節點與原有節點的映射關系。示例性的,把原有集群的n個節點和需要擴容的新的n個節點建立一對一的映射關系。或者原有集群的n個節點和需要擴容的新的2n個節點建立一對二的映射關系。S130,將原有節點的數據復制至映射關系對應的新節點,構造新的hashmap。示例性的,按照該對應關系,把原有集群的n個節點的二進制數據文件一對一的拷貝到需要擴容的新的n個節點,并在集群中構造新的hashmap,其中hashmap是hash值和節點的對應關系,并使所述hashmap生效。例如:原來的hashmap如下:hashkeyNodeid01(Node1)11(Node1)21(Node1)31(Node1)41(Node1)51(Node1)....m1(Node1)新增加的Noden+1和Node1建立對應關系,Noden+1和Node1節點所屬的hashmap如下:S140,新節點和原有節點按照所述hashmap進行數據重分布。在擴容后有2n個節點的集群中創建和原有表結構相同的新表,在擴容后有2n個節點的集群中針對每一個節點,查詢原表的數據,按照新的hashmap,對查詢出的數據進行hash計算,把屬于該節點的數據插入到新表中。S150,更新集群中節點中的表。刪除系統中各個節點的原表,把新表名更名為原表名。本實施例提供的分布式數據庫的擴容方法及裝置,在集群安裝新節點與原有節點為倍數關系時,通過建立新節點與原有節點的映射關系,構造hashmap,并對數據重分布,減少了節點數據的計算量,實現了強擴容性能,并能快速釋放刪除行的存儲空間。在本實施例的一個優選方式中,所述數據為二進制數據,通常可以為二進制數據文件,使用二進制將數據儲存到文件更快捷、省時且不會造成有效位的丟失。實施例二圖2是本發明實施例二提供的分布式數據庫的擴容方法的流程示意圖,本發明實施例以上述實施例為基礎,進一步的,將所述新節點和原有節點按照所述hashmap進行數據重分布,具體優化為:原有節點保留原表的一半數據;與原有節點對應的新節點插入所述原有節點的另一半數據。參見圖2,所述分布式數據庫的擴容方法,包括:S210,集群安裝新節點,所述新節點與原有節點為倍數關系。S220,建立新節點與原有節點的映射關系;S230,將原有節點的數據復制至映射關系對應的新節點,構造新的hashmap。S240,原有節點保留原表的一半數據,與原有節點對應的新節點插入所述原有節點的另一半數據。在擴容后有2n個節點的集群中,原有節點保留原表的一半數據,而將,與原有節點對應的新節點插入所述原有節點的另一半數據。從而將數據重新分布到對應的新增節點上。S250,更新集群中節點中的表。本實施例通過將所述新節點和原有節點按照所述hashmap進行數據重分布,具體優化為:原有節點保留原表的一半數據;與原有節點對應的新節點插入所述原有節點的另一半數據。在新增節點數量與原有節點數量一致時,通過將原有節點的一半數據分布在對應新增節點上。降低數據分布時的運算量,減少了數據分布的時間。實施例三圖3是本發明實施例三提供的分布式數據庫的擴容方法的流程示意圖,本發明實施例以上述實施例為基礎,進一步的,所述方法還包括:刷新所有節點的元數據,以使得所有節點實現提供對外服務。參見圖3,所述分布式數據庫的擴容方法,包括:S310,集群安裝新節點,所述新節點與原有節點為倍數關系。S320,建立新節點與原有節點的映射關系;S330,將原有節點的數據復制至映射關系對應的新節點,構造新的hashmap。S340,新節點和原有節點按照所述hashmap進行數據重分布;S350,更新集群中節點中的表。S360,刷新所有節點的元數據,以使得所有節點實現提供對外服務。元數據為描述數據的數據,主要是描述數據屬性的信息,用來支持如指示存儲位置、歷史數據、資源查找、文件記錄等功能。根據元數據,可以查找對應的數據。在元數據更新完成后,可以使得所有節點實現提供對外服務。實施例四圖4是本發明實施例四提供的分布式數據庫的擴容裝置的結構示意圖,如圖4所示,所述裝置包括:安裝單元410,用于安裝新節點,所述新節點與原有節點為倍數關系;映射關系建立單元420,用于建立新節點與原有節點的映射關系;構造單元430,用于將原有節點的數據復制至映射關系對應的新節點,構造新的hashmap;重分布單元440,用于使新節點和原有節點按照所述hasmap進行數據重分布;更新單元450,用于更新集群中節點中的表。本實施例提供的分布式數據庫擴容裝置,本發明實施例提供的分布式數據庫的擴容方法及裝置,在集群安裝新節點與原有節點為倍數關系時,通過建立新節點與原有節點的映射關系,構造hashmap,并對數據重分布,減少了節點數據的計算量,實現了強擴容性能,并能快速釋放刪除行的存儲空間。進一步的,所述重分布單元用于:原有節點保留原表的一半數據;與原有節點對應的新節點插入所述原有節點的另一半數據。進一步的,所述裝置還包括:刷新單元,刷新所有節點的元數據,以使得所有節點實現提供對外服務。更進一步的,所述數據包括:二進制文件。本領域普通技術人員可以理解:實現上述各方法實施例的全部或部分步驟可以通過程序指令相關的硬件來完成。前述的程序可以存儲于一計算機可讀取存儲介質中。該程序在執行時,執行包括上述各方法實施例的步驟;而前述的存儲介質包括:ROM、RAM、磁碟或者光盤等各種可以存儲程序代碼的介質。最后應說明的是:以上各實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述各實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分或者全部技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的范圍。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1