一種基于FPGA實現稀疏化GRU神經網絡的硬件加速器及方法與流程
本申請要求于2016年8月22日提交的美國專利申請no.15/242,622、于2016年8月22日提交的美國專利申請no.15/242,624、于2016年8月22日提交的美國專利申請15/242,625的優先權。其全部內容在此參考并入。發明領域本發明涉人工智能領域,特別地,本發明涉及一種基于fpga實現稀疏化gru神經網絡的硬件加速器及方法。
背景技術:
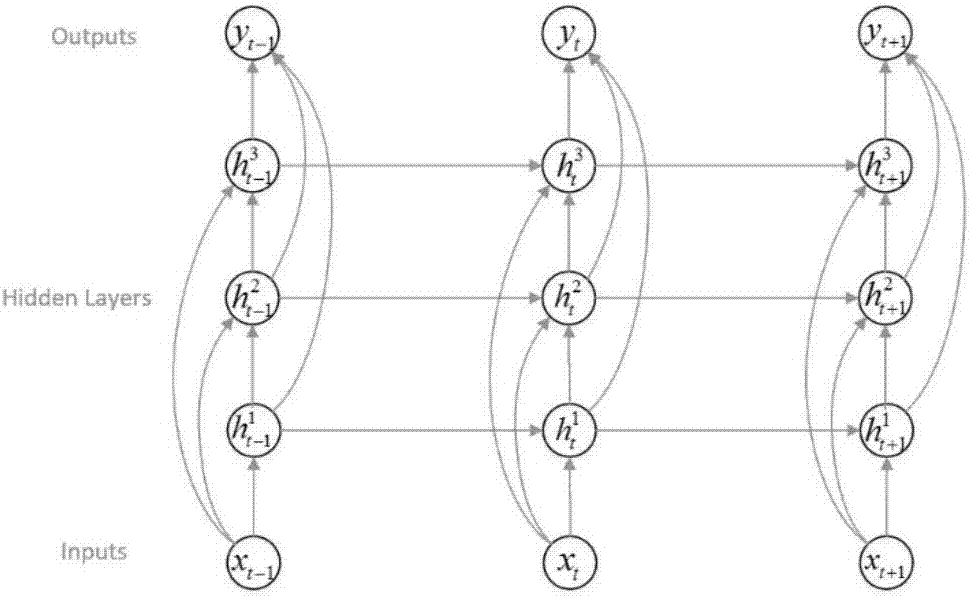
:rnn簡介循環神經網絡(rnn)是一類人工神經網絡,其中單元之間的連接形成有向循環。這創建了網絡的內部狀態,其允許其展現動態的時間行為。rnn可以通過具有循環隱藏狀態來處理可變長度序列,其中每個時刻的激活依賴于先前時刻的激活。傳統地,標準rnn以如下方式計算下一步驟的隱藏層:ht=f(w(hh)ht-1+w(hx)xt)其中f是平滑的有界函數,例如邏輯s形函數(logisticsigmoidfunction)或雙曲正切函數。w(hh)是狀態到狀態的循環權重矩陣,w(hx)是輸入到隱藏權重矩陣。輸入序列是x=(x1,...,xt)。我們可以將任意長度的序列的概率分解為:p(x1,...,xt)=p(x1)p(x2|x1)p(x3|x1,x2)…p(xt|x1,...,xt-1)然后,如圖1所示,我們可以訓練rnn來對該概率分布建立模型,給定隱藏狀態ht,使其預測下一個符號xt+1的概率。其中ht是所有先前符號x1,x2,...xt的函數:p(xt+1|x1,…,xt)=f(ht)隱藏層激活通過從t=1到t和從n=2到n重復以下等式來計算:其中w項表示權重矩陣(例如wihn是將輸入連接到第n個隱藏層的權重矩陣,wh1h1是第一隱藏層的循環連接,等等),b項表示偏置向量(例如by是輸出偏置向量),h是隱藏層函數。給定隱藏序列,輸出序列的計算如下:其中y是輸出層函數。因此,完整網絡定義了這樣一個函數,由權重矩陣作為參數,從輸入歷史序列x(1:t)到輸出向量yt。圖2示出了rnn的基本網絡框架,其中上一次隱藏層的輸出作為這一次隱藏層的輸入,即當前層的輸出僅和上一層的隱藏層、當前層的輸入有關。gru簡介門控循環單元(gatedrecurrentunit,gru)是rnn的一種。gru可以根據輸入信號來記憶或者忘記狀態。gru的結構如圖3所示。rt=σ(w(r)xt+u(r)ht-1)其中,重置門rt的計算如下:更新門的計算與重置門相似,如下:zt=σ(w(z)xt+u(z)ht-1)候選激勵值的計算和傳統rrn相似,如下:如果重置門是一個全部元素都為零的向量,那么丟掉以前的記憶,只保留新信息。gru在時間t時的激勵值是在先激勵值和候選激勵值之間的線性插值。神經網絡的壓縮近年來,神經網絡的規模不斷增長,公開的比較先進的神經網絡都有數億個連接,屬于計算和訪存密集型應用。現有方案這些算法通常是在通用處理器(cpu)或者圖形處理器(gpu)上實現。隨著晶體管電路逐漸接近極限,摩爾定律也受到了極大的挑戰。在神經網絡逐漸變大的情況下,模型壓縮就變得極為重要。模型壓縮將稠密神經網絡變成稀疏神經網絡,可以有效減少計算量、降低訪存量。稀疏化矩陣的編碼:crs和ccs如前所述,對于稀疏矩陣的處理,為了減少內存,往往需要對矩陣進行壓縮存儲,比較經典的存儲方法包括:行壓縮(compressedrowstoragecrs)和列壓縮存儲(compressedcolumnstorageccs)。為了利用激勵函數的稀疏性,可以將編碼稀疏權重矩陣w存入壓縮列存儲(ccs)格式的變量中。對于w矩陣每列wj,我們存儲一個包含非零權重的向量v,以及等長向量z,向量z用于編碼v的相應條目之前零的個數,v和z各自由一個四位數值表示。如果超過15個零出現在一個非零的條目,在向量v中添加一個零。例如,以下列被編碼為:[0,0,1,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,3]v=[1,2,0,3],z=[2,0,15,2]。所有列的v和z的都存儲在一對大陣列中,其中指針向量p指向每個列的向量的開始。p指針向量中的最后一項指向超過最后一個向量元素,這樣pj+1-pj給出了第j列中的非零數(包括填補的零)。通過壓縮列存儲格式(ccsformat)中列存儲稀疏矩陣,使得利用激勵函數的稀疏性變得容易。只需要用每個非零激勵與其相應列中的所有非零元素相乘。美國專利uspatent9317482“universalfpga/asicmatrix-vectormultiplicationarchitecture”中更詳細地披露了如何使用compressedsparserow(csr)在基于cpu和gpu的方案中,其中也采用compressedvariablelengthbitvector(cvbv)format。稀疏神經網絡存儲需要編碼,計算之前需要解碼。但是,現有通用處理器(例如gpu或cpu)并不能從稀疏化技術中獲得較好的收益。已公開實驗表明模型壓縮率較低時,現有通用處理器的加速比有限。因此,希望專有定制電路(例如fpga)可以解決上述問題,以使得處理器在較低壓縮率下獲得更好的加速比。本發明的目的之一是采用高并發流水線設計來設計gru專有定制電路,從而能夠有效處理稀疏gru神經網絡,從而獲得更好的計算效率,更低的處理延時。技術實現要素:本發明提供了一種用于實現稀疏化gru神經網絡的裝置,包括:輸入接收單元,用于接收多個輸入向量,并將多個輸入向量分配到多個計算單元;多個計算單元,從所述輸入接受單元獲取輸入向量,讀取神經網絡權值矩陣數據,將其解碼后與輸入向量進行矩陣運算,并將矩陣運算結果輸出至隱含層狀態計算模塊;隱含層狀態計算模塊,從所述計算單元pe獲取矩陣運算結果,計算出隱含層狀態;控制單元,用于進行全局控制。此外,所述每個計算單元進一步包括:稀疏矩陣讀取單元,用于讀取所述神經網絡的權重矩陣w,其中所述權重矩陣w被用于表示所述神經網絡中的權重;運算單元,用于執行所述神經網絡的乘法運算和加法運算;運算緩存單元,用于存儲從所述運算單元中輸出的矩陣運算的中間結果以及最終計算結果,并將矩陣運算中間結果輸出至運算單元,并且將矩陣運算最終計算結果輸出至數據組合單元。此外,所述隱含層狀態計算模塊進一步包括:數據組合單元,用于接收從各個計算單元中的緩存單元輸出的矩陣運算的結果,并將其組合成一個完整的運算結果輸出至加法器;選擇器,從數據組合單元模塊和從點乘器接收數據,選擇其中之一輸入到加法器;wx緩存單元,接收并存儲從數據組合單元中輸出的矩陣運算計算結果,再根據控制單元的指令將相應運算結果輸出至加法器進行計算;加法器,針對分配到所述多個計算單元的各個輸入向量,完成gru神經網絡算法中的向量累加操作;函數單元,與所述加法器連接,用于實現激活函數;點乘器,從數據組合單元和函數單元接收數據,進行點乘運算,并將運算結果輸出至選擇器。本發明還提供了一種實現稀疏gru神經網絡的方法,所述gru神經網絡的矩陣包括:wz,wz是更新門作用于輸入數據的權值矩陣,wr,wr是重置門作用于輸入數據的權值矩陣,w,w是輸入數據變換矩陣,wx,wx是wz、wr和w合并后的結果uz,uz是更新門作用于隱含層的權重矩陣,ur,ur是重置門作用于隱含層的權值矩陣,u,u是隱含層變換矩陣,以及uh,uh是uz、ur和u合并后的結果,輸入序列是x=(x1,...,xt),所述方法包括:初始化步驟,完成數據的初始化,包括:將計算wxxt所需所有的數據讀入fpga片上內存,包括輸入向量x,和輸入向量x對應的權值矩陣wx的所有信息;步驟1,計算單元(pes)開始計算wxx,同時將計算uhht-1所需的數據讀入fpga片上內存,其中ht-1是隱含層對上一個輸入向量的激勵值;步驟2,計算單元(pes)計算uhht-1,同時將計算下一個wxx所需數據讀入fpga片上內存。;迭代重復執行上述步驟1和步驟2。本發明還提供了一種基于fpga實現壓縮后rnn神經網絡的方法,包括以下步驟:接收數據,從外部存儲器將計算權值矩陣運算所需要的數據加載到fpga片上存儲器,所述數據包括輸入向量,以及壓縮后的權值矩陣數據;解壓數據,根據上述接收數據步驟讀取的數據以及權值矩陣的壓縮方法,利用fpga片上處理器解壓出權值矩陣原始數據,并存儲至fpga片上存儲器;矩陣運算,使用fpga片上乘法器和加法器進行權值矩陣和向量的乘加運算,并把結果向量存儲至fpga片上存儲器,所述向量包括輸入向量以及隱含層的激勵值向量;向量加法運算,使用fpga片上加法器進行向量加法運算,并將結果存儲在fpga片上存儲器,所述向量包括上述矩陣運算的結果向量和偏置向量;激活函數運算,對上述向量加法運算的結果進行激活函數運算,并將結果存儲在fpga片上存儲器;迭代上述接收數據、解壓數據、矩陣運算、向量加法運算、激活函數運算步驟,算出rnn網絡的激勵值序列,再根據激勵值序列利用fpga片上乘法器和加法器進行矩陣運算和向量加法運算計算出gru輸出序列。附圖說明圖1顯示了包含隱藏狀態的神經網絡的模型的例子。圖2顯示了包含隱藏狀態的rnn神經網絡的模型例子。圖3顯示了包含隱藏狀態的gru神經網絡的模型例子。圖4顯示了一種用于實現壓縮神經網絡的高效的硬件設計。圖5進一步顯示了基于圖3所示的硬件設計方案來把工作任務分配到多個計算單元。圖6顯示了對應圖4的某個計算單元(pe0)的矩陣壓縮(例如ccs)格式。圖7顯示了圖3的硬件設計方案中的解碼器(weightdecoder)部分,用于對編碼的矩陣進行解碼。圖8顯示了根據本發明實施例的在一個信道的多個計算單元(pe)的布置。圖9顯示了根據本發明的實施例的狀態機的狀態轉移。圖10a,10b,10c,10d顯示了根據本發明的實施例計算輸出ht的過程。圖11顯示了矩陣稀疏性不平衡對計算資源利用的影響。圖12顯示了根據本發明一個實施例的特定硬件設計來實施神經網絡運算的例子。具體實施方法發明人之前的研究成果:采用eie并行處理壓縮神經網絡本發明的發明人之一曾經提出了一種高效的推理引擎(eie)。為了更好的理解本發明,在此簡要介紹eie的方案。圖4顯示了一種高效的推理引擎(eie),適用于用于機器學習應用的壓縮深度神經網絡模型,尤其是采用上述ccs或crs格式存儲的壓縮dnn。中央控制單元(ccu)控制pes的陣列,每個pes計算壓縮網絡中的一片(slice)。ccu從分布式前置零檢測網絡接收非零輸入激勵,并把它們廣播給pes。上述方案中,幾乎所有eie中的計算對于pes是局部的,除了向所有pes廣播的非零輸入激勵的集合。然而,激勵集合和廣播的時間并不是關鍵的,因多數pes需要多種周期來完成每個輸入激勵的計算。激勵隊列和負載平衡輸入激勵向量aj的非零元素和相應的指標索引j被ccu廣播到每個pe中的激勵隊列。如果任何一個pe有一個完整的隊列,廣播失效。在任何時間,每個pe處理在其隊列頭部的激勵。激勵隊列:允許每個pe建立一個工作隊列,以消除可能出現的過載不平衡。因為在一個給定列j中的非零的數量可能對于不同pe會有所不同。指針讀取單元:在激勵隊列頭部的條目的索引j被用來查找開始和結束的指針pj和pj+1,對應于第j列的v和x陣列。為了允許在一個周期中讀取兩個指針且使用單口sram陣列,在兩sram內存庫中存儲指針,使用地址的lsb在內存庫之間進行選擇。pj,pj+1總會在不同的內存庫中。eie指針的長度是16位。稀疏矩陣讀取單元:稀疏矩陣讀取單元使用指針的pj,pj+1從稀疏矩陣sram讀ij列的該pe片(slice)的非零元素(如果有的話)。sram中的每個條目是8位長度,包含v的4位數據和x的4位數據。為了效率,編碼的稀疏矩陣i的pe的片(slice)被存儲在64位寬的sram中。因此,每次從sram讀取8條。當前指針p的高13位用于選擇sram行,低3位選擇該行中的八條之一。單個(v,x)條被提供給每個周期的算術單元。運算單元:算術單元從稀疏矩陣讀取單元接收(v,x)條,執行乘法累加操作bx=bx+v×aj。索引x是用來索引一個累加器陣列(目的地激勵寄存器),而v乘以在激勵隊列頭部的激勵值。因為v以4位編碼形式存儲,它首先通過查表(codebook)擴展成16位定點數。如果在兩個相鄰的周期上選擇相同的累加器,則提供旁路通路,將加法器的輸出導向其輸入。激勵讀/寫:激勵讀/寫單元包含兩個激勵寄存器文件,分別容納一輪fc層計算期間的源激勵值和目的地激勵值。在下一層,源和目標寄存器文件交換它們的角色。因此,不需要額外的數據傳輸來支持多層前饋計算。每個激勵寄存器文件擁有64個16位激勵。這足以容納64pes的4k激勵向量。更長的激勵向量可容納在2kb的激勵sram中。當激勵向量大于4k長度時,m×v將分批次(batch)完成,其中每個批次的長度是4k或更少。所有本地減法是在寄存器完成,sram只在批次的開始時被讀取、在結束時被寫入。分布式前置非零檢測:輸入激勵分層次地分布于各個pe。為了利用輸入向量稀疏性,我們使用前置非零檢測邏輯來選擇第一個正向(positive)的結果。每一組4pes進行輸入激勵的局部前置非零檢測。結果被發送到前置非零檢測節點(lnzd節點),如圖4所示。4個lnzd節點找到下一個非零激勵,并發送結果給lnzd節點樹。這樣的布線不會因為添加pes而增加。在根lnzd節點,正向激勵是通過放置在h樹的單獨導線被廣播給所有pes。中央控制單元:中央控制單元(ccu)是根lnzd節點。它與主控器,如cpu通訊,通過設置控制寄存器來監控每個pe的狀態。中央單元有兩種模式:i/o和計算。在i/o模式,所有的pes閑置,每個pe的激勵和權重可以通過與中央單元連接的dma訪問。在計算模式,ccu會持續地從源激勵存儲庫順序收集和發送數值,直到輸入長度溢出。通過設置指針陣列的輸入長度和起始地址,eie將被指示執行不同的層。圖5顯示了如何使用多個處理單元(pes),交織計算矩陣w的各個行,分配矩陣w和并行化矩陣向量計算。對于n個pes,pek擁有所有列wi,輸出激勵bi和輸入激勵ai,因子i(modn)=k。pek中的列wj的部分被存儲為ccs格式,但計數的零僅指這個pe的列的子集的零。每個pe有自己的v,x和p陣列,v,x和p陣列用于編碼其所計算的稀疏矩陣的一部分。圖5中,顯示了矩陣w和向量a和b在4pes交錯。相同顏色的元素都存儲在相同的pe里。圖5中,將輸入激勵向量a(長度為8)乘以一個16×8權重矩陣w產生一個輸出激勵向量b(長度為16)在n=4的pes上。a,b和w的元素根據他們的pe配置情況進行顏色編碼。每一個pe擁有w的4行,a的2個元素,和b的4個元素。通過掃描向量a以找到它的下一個非零值aj,依據索引j向所有pes廣播aj,進行稀疏矩陣×稀疏向量運算。每個pe再將aj乘以在列wj部分的非零元素,在累加器中累加各個部分和,以輸出激勵向量b中的每個元素。在ccs表示中,這些非零權重被連續存儲,每個pe只需沿著其v陣列從位置pj到pj+1-1加載權重。為了尋址輸出累加器,通過保持x陣列條目的運行總和,產生對應于每個權重wij的行數i。在圖5的例子中,第一個非零是pe2上的a2。a2的值和其列索引2向所有pes廣播。每個pe將a2乘以其列2部分中的每個非零值。pe0將a2乘以w0,2和w12,2;pe1在列2中全為零,故不執行乘法;pe2將a2乘以w2,2和w14,2,等等。將每個點積的結果相加到相應的行累加器。例如,pe0計算b0=b0+w0,2a2和b12=b12+w12,2a2。在每層的計算前,累加器被初始化為零。交錯(interleaved)ccs表示法有助于利用激勵向量a的動態稀疏性,權重矩陣w的靜態稀疏性。通過僅廣播輸入激勵a的非零元素,利用了輸入激勵的稀疏性。a中對應于零的列被完全跳過。交錯(interleaved)ccs表示法允許每個pe迅速在每列找到非零并乘以aj。這種組織方式也保持了所有的計算在本地pe,除了廣播輸入激勵以外。圖5中的矩陣的交錯ccs表示法如圖6所示。圖6顯示了對應圖5的pe0的相對索引的存儲器布局、間接加權和交錯的ccs格式。相對行索引(relativerowindex):當前非零權值與前一個非零權值之間的零元素的個數;列位置(columnpointer):當前“列位置”與前一個“列位置”之差=本列的非零權值的個數。基于圖6的編碼方式來讀取非零權值方式:(1)讀取2個連續的“列位置”,求差,該差值=本列的非零權重的個數(2)利用相對行索引,獲得該列的非零權重的行位置,從而獲得非零權重的行、列位置信息。此外,圖6所示的權重值是被進一步壓縮后得到的虛擬權重(virtualweight)。圖7示出了根據eie的硬件結構中的解碼器(weightdecoder)部分。如圖7所示,權重查找表(weightlook-up)和索引(indexaccum)對應于圖3的權重解碼器(weightdecoder)。通過權重查找表和索引,解碼器把虛擬權重(例如,4bit)解碼為真實權重(例如,16bit)。這是因為壓縮dnn模型具有稀疏性,以索引方式存儲和編碼。在對輸入數據進行處理時,壓縮dnn的編碼權重被解碼,通過權重查找表被轉換為真實權重,再進行計算。本發明提出的改進現有技術方案中gru算法通常是采用通用處理器(cpu)或者圖形處理器(gpu)來實現的,稠密gru網絡需要較大io帶寬、較多存儲和計算資源。近年來晶體管電路逐漸接近極限,摩爾定律快走到盡頭,同時神經網絡的規模還在不斷增大,這都給現有處理器帶來了挑戰。為了適應算法需求,模型壓縮技術變得越來越流行。模型壓縮后的稀疏神經網絡存儲需要編碼,計算需要解碼。當前通用處理器或圖形處理器沒有硬編解碼電路,無法充分享受網絡稀疏化帶來的好處。因此,本發明的目的在于提供一種稀疏gru網絡加速器的實現裝置和方法,以便達到提高計算性能、降低響應延時的目的。為此,本發明設計了一種專用電路,支持稀疏化gru網絡,采用ping-pong緩存并行化流水線設計,有效平衡io帶寬和計算效率,從而獲得較好的性能功耗比。圖8示出了根據本發明實施例的多個計算單元(pe)的布置.如圖8所示,主要包括如下模塊:輸入接收單元110:該模塊用于接收并存儲稀疏神經網絡的輸入向量,并把輸入向量發送至運算單元140。該模塊還包含多個先進先出緩存單元(fifo),每個計算單元pe對應一個fifo,從而在相同輸入向量的情況下能夠有效平衡多個計算單元之間計算量的差異。多個計算單元pe可以共享輸入向量。fifo深度的設置可以選取經驗值,fifo深度過大會造成浪費資源,過小又不能有效地平衡不同pe之間的計算差異。如圖8所示,每個計算單元pe還進一步包括如下子模塊。位置單元120:該模塊用于讀取并存儲壓縮后的稀疏神經網絡的指針信息,并將指針信息輸出至解碼單元130。例如,如果稀疏矩陣采用ccs存儲格式,那么位置單元120存儲列指針向量(即圖6中的第3行)。其中,在輸入接收單元110頭部的條目的索引j被用來查找開始和結束的列指針pj和pj+1。向量中的pj+1-pj值表示第j列中非零元素的個數。在本發明的一個實施例中,位置單元120包括一對乒乓結構緩存(ping-pongbuffer)。解碼單元130:該模塊用于存儲壓縮后的稀疏神經網絡的權重信息,并將其輸出至運算單元140。在本發明的一個實施例中,權重信息包括相對索引值和權重值等(即圖6中的前兩行)。在本發明的一個實施例中,信息的讀取和處理也由一對乒乓結構緩存(ping-pongbuffer)并行處理。此外,該模塊基于位置單元120輸出的pj+1和pj值讀取權重矩陣中對應的權重值,系統從指針pj移動至pj+1-1即可加載j列的權重值。運算單元140:該模塊用于實現乘累加計算,其根據輸入接收單元110輸出的向量和解碼單元130輸出的相對索引值以及權重值進行矩陣運算,并把運算結果輸出至運算單元緩存150。該運算單元140主要進行以下兩步計算:第一步,讀取神經元的輸入向量和權重值以進行對應的乘法計算;第二步,根據相對索引值讀取運算單元緩存150中對應位置歷史累加結果,再與第一步結果進行加法運算。運算單元緩存150:該模塊用于存儲從運算單元140中輸出的矩陣運算的中間結果以及最終計算結果,并將矩陣運算中間結果輸出至運算單元140,并且將矩陣運算最終計算結果輸出至數據組合單元160。在本發明的實施例中,為提高下一級的計算效率,運算單元緩存140也采用一堆乒乓結構緩存(ping-pongbuffer)設計,進行流水線操作。此外,圖8所示的如下模塊由所述多個計算單元pe所共用。數據組合單元160:該模塊用于接收從各個pe中運算緩存單元150輸出的矩陣運算的結果,然后將其組合成一個完整的運算結果,再根據矩陣運算的類型,將結果輸出至選擇器170,wx緩存180或點乘器210中。由于本發明的并行設計,每個pe都將矩陣中的部分行與輸入向量進行乘累加運算,得到結果向量的一部分。數據組合單元160將這些部分組合成一個完整的結果向量。選擇器170:該模塊從數據組合單元160和從點乘器210接受數據,并從中選擇一組數據輸入到加法器190中。wx緩存單元180:該模塊接收狀態1階段從數據組合單元160中輸出的計算結果wxxt(合并后更新門、重置門權重矩陣以及變換矩陣與輸入向量相乘的結果即w(z)xt、w(r)xt和wxt合并后的結果),并在下一個狀態1階段時將w(z)xt、w(r)xt和wxt分別輸出至加法器190計算出重置信號rt,更新信號zt或新的記憶加法器190:該模塊從選擇器170和wx緩存180接收數據,進行加法運算后,講結果輸出至激活函數模塊200。函數單元200:該模塊用于實現算法中的sigmoid/tanh激活函數運算。當加法器190完成了各組權重與向量的疊加運算后,經該激活函數后可獲得最終的計算結果。點乘器210:該模塊從數據組合單元160和函數單元200接受數據,進行點乘運算,并將運算結果輸出至選擇器。緩存單元220:該模塊接收并存儲函數單元200輸出的結果,并將其輸出至點乘加單元240,用于計算隱含層狀態ht.zt緩存單元230:該模塊接收并存儲函數單元200輸出的zt結果,并將其輸出至點乘加單元240,用于計算隱含層狀態ht.點乘加單元240:該模塊從緩存單元220,zt緩存單元230以及向量緩存單元260讀取zt以及ht-1進行點乘及加法運算,計算出隱含層狀態ht。向量緩存單元250:該模塊用于存儲各個隱含層的計算結果ht。控制單元260:該模塊負責全局控制。本發明設計gru狀態機,通過狀態機的狀態轉移,實現gru網絡操作的高速流水運行。狀態機的控制包括,控制指針向量的讀取、控制輸入向量與權值矩陣的信號同步、控制內部乒乓結構緩存(ping-pongbuffer)的切換、控制運算單元140的計算,控制pe外部各個運算單元及緩存。在根據本發明的一個實施例中,對于含有相同向量的矩陣運算,采用合并的方式計算。具體而言,在下面的公式中,w(z)、w(r)和w都要與xt相乘,u(z)、u(r)和u都要與ht-1相乘。本發明在矩陣運算階段,將w(z)、w(r)和w合并為一個矩陣wx與xt相乘,將u(z)、u(r)和u合并為一個矩陣uh與ht-1相乘。rt=σ(w(r)xt+u(r)ht-1)zt=σ(w(z)xt+u(z)ht-1)在這個實施例中,只需要加載一次向量xt和ht-1即可完成矩陣運算,提高了計算效率。本發明的實施例中,定制電路的并行化流水線設計體現在對狀態機的控制上,流水線設計可以有效地平衡io帶寬與計算性能。已知,在數據加載時間小于計算時間的情況下,計算單元pe效率可以最大化。如下公式所示,左側是每個計算單元pe需要完成的計算復雜度,右側是所需的io帶寬。其中data_size為權值矩陣的大小,通常是mxn維度,compress_ratio是gru網絡壓縮率,pe_num是計算矩陣乘向量的計算單元并發度,freq_pe是計算單元運行的時鐘頻率,data_bit是權值矩陣量化后的定點位寬,ddr_width是計算單元與內存控制模塊的數據位寬,freq_ddr是計算單元與內存控制模塊數據的時鐘頻率。如上公式所示,左側大于右側io是瓶頸,左側小于右側計算是瓶頸。通過上述公式可以推算不同io帶寬下需要計算單元的個數。圖9示出了根據本發明的實施例的狀態機的狀態轉移。具體而言,在每個狀態中包括數據讀取和計算。前三行操作是獲取權重、指針、輸入向量,以準備下一次計算。第四行中的操作是矩陣向量乘法,包括合并w(z)、w(r)和w與輸入向量xt的操作,合并u(z)、u(r)和u與上一幀隱層ht-1的操作。第五行中的操作是涉及求和以及激活函數等的計算。水平方向上的操作必須被順序執行,垂直方向上的操作同時執行。在本發明的一個實施例中,狀態機包括三個狀態。在初始化狀態,完成數據的初始化,準備計算whxxt所需的數據。其中,xt為輸入向量,wx(w(z)、w(r)和w合并后的結果)包含向量對應權重矩陣的所有信息,例如,在采用ccs壓縮時,包含指針信息、相對索引值和權重值等數據;狀態1,計算單元pes開始計算wxxt,同時從內存讀取uh(u(z)、u(r)和u合并后的結果)。在下一個狀態1時依次計算zt,rt,(rt。uht-1),和ht;狀態2,計算單元pes計算uhh(t-1),io讀取下一幀或者下一層的wx(w(z)、w(r)和w)、指針以及輸入向量。如圖9所示,狀態1和狀態2交替進行,當一層對應的稀疏矩陣與向量的運算完成后,在計算下一層的矩陣運算(圖9中第4行)的同時,進行加法樹和激活函數等運算(圖9中第5行),從而達到高效流水的目的。xt的準備由輸入接收單元110完成,wx的準備由位置單元120和解碼單元130完成。在本發明的一個實施例中,使用上述模塊實現稀疏gru網絡加速器過程如下:步驟1:初始化依據全局控制信息讀取gru權值矩陣的位置信息。步驟2:根據步驟1的位置信息讀取稀疏神經網絡的位置索引、權重值。步驟3:根據全局控制信息,輸入接收單元110把輸入向量廣播給多個計算單元pe。步驟4:運算單元140把解碼單元130發送來的權重值與輸入接收單元110送來的輸入向量對應元素做乘法計算,得到矩陣運算的中間結果,存儲至運算緩存單元150中。步驟5:運算單元140根據步驟2的位置索引值讀取運算緩存單元150中相應位置的中間結果,然后將其與步驟4的乘法結果做加法計算。步驟6:根據步驟2的索引值把步驟5的加法結果寫入運算緩存單元150中。步驟7:重復步驟1-6,依次計算wxxt和uht-1,計算完wxxt后先緩存到wx緩存單元180中,如圖10a所示,計算完uhht-1后的下一個狀態讀取wx緩存單元180中的w(z)xt與u(z)ht-1結果計算zt并存儲在zt緩存單元230中。步驟8:如圖10b所示,從wx緩存單元180讀取w(r)xt與運算緩存單元150中的u(r)ht-1計算rt,如圖10c所示,然后rt再與運算緩存單元150中uht-1做點乘操作。步驟9:如圖10d所示,步驟8中的點乘結果和wx緩存單元180中的wxt計算求得并存儲在緩存單元230中步驟10:如圖10d所示,從zt緩存單元230讀取zt,從緩存單元230讀取并將它們輸出至點乘加單元240進行點乘和加法計算,最終得到ht。具體實施例例1接下來,以2個計算單元(processelement,簡稱pe)pe0和pe1計算一個矩陣向量乘,采用列存儲(ccs)為例,簡要說明基于本發明的硬件進行相應運算的基本思路。壓縮后gru中矩陣稀疏度并不平衡,這導致計算資源的利用率降低。如圖11所示,假設輸入向量a包含6個元素{a0,a1,a2,a3,a4,a5},權值矩陣包含8×6個元素。2個pe(pe0和pe1)負責計算a3×w[3],這里a3是輸入向量第4個元素,w[3]是權值矩陣的第4列。從圖11中可見,pe0和pe1的工作負載并不相同,pe0進行3次乘法運算,pe1只進行一次。在現有技術中,系統會使pe1完成a3的運算后處于等待狀態,直至pe0完成3次加法運算后,再開始進行a4的運算。本發明在輸入接收單元110加入先入先出緩存單元(fifo),將輸入向量a的一部分加載到fifo中。在本發明實施例中,pe1完成a3的運算后,會從fifo中讀取a4繼續計算。這樣的設計提高了計算資源的利用率。參見圖12,假設權值矩陣w和輸入向量x如圖12所示,奇數行元素由pe0完成,偶數行元素由pe1完成,輸出向量的奇數元素由peo計算所得,輸出向量的偶數元素由pe1計算所得。輸入向量x會被廣播給兩個計算單元pe0,pe1。針對pe0中的操作如下:表1為pe0對應的權重,相對索引位置和列位置信息。權值w00w20w41w62w43w04w24w45w26相對行索引004421042列位置023457899表1位置單元120:存儲奇數行非零元素的列位置信息,其中p(j+1)-p(j)為第j列中非零元素的個數。解碼單元130:存儲奇數行非零元素的權值和相對行索引。輸入接收單元110:存儲輸入向量xt,該模塊把輸入向量廣播給兩個計算單元peo和pe1,為了平衡計算單元間元素稀疏度的差異,每個計算單元的入口都添加先進先出緩存(fifo)來提高計算效率。解碼單元130讀取矩陣元素,例如w00,將其輸出至運算單元140,計算出w00·x00的結果存儲在運算緩存單元150中。待本行計算完畢后,運算緩存單元150將中間結果(w00·x00和w04·x04)輸出至運算單元140,計算出矩陣運算最終結果y0并輸出。數據組合單元160將peo輸出的y0,y2,y4,y6和pe1輸出的y1,y3,y5,y7組合成完整的輸出向量y。例2通過本實施例,旨在闡釋本發明的io帶寬與計算單元平衡。如果內存控制器用戶接口是512bit,時鐘為250mhz,那么需要的pe并發度為512*250mhz=(pe_num*freq_pe*data_bit),如果定點成8bit權值,pe計算模塊時鐘頻率為200mhz,需要pe數量為80個。針對2048*1024輸入為1024的網絡,在不同稀疏度下,計算耗時最大的依然是矩陣乘向量。對稀疏gru網絡zt,rt,以及對ht的計算可以被矩陣向量乘wxt和uht-1的計算所掩蓋。由于后續的點乘和加法操作是串行流水線設計,所以需要的資源也相對較少。綜上本發明充分結合稀疏矩陣向量乘,io和計算平衡,串行流水線設計,可高效提供稀疏gru網絡的算法加速。技術效果基于上述技術方案可知,根據本發明的稀疏gru網絡加速器的實現裝置和方法,通過采用定制電路,流水線設計,有效地平衡了io帶寬與計算,從而提高了計算性能、降低了響應延時。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1