股票分析方法和系統與流程
本發明涉及股票分析技術領域,特別是涉及一種股票分析方法和系統。
背景技術:
全球的股票市場內,股票種類眾多,價格瞬息萬變,不同行業的股票之間存在一定的關聯性,同時因為某些股票投資機構的投資操作,也導致不同的股票之間存在很強的關聯,但由于股票自身價格波動的不確定性,股票數據量大、以及股票關聯的不確定性因素眾多,無論是眾多的股票散戶,還是股票分析機構,如何從海量的股票數據中,準確分析各股票之間的關聯性,是股票分析領域一個重要的課題。
技術實現要素:
基于此,有必要針對各股票間關聯性的分析問題,提供一種股票分析方法和系統,其中所述方法包括:
獲取第一原始股票序列和第二原始股票序列;
根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量;
對所述各第一股票狀態向量進行排序,獲取各第一股票重排序向量,并根據所述各第一股票重排序向量和所述各第二股票狀態向量,獲取各第二股票重排序向量;
根據所述各第二股票重排序向量和預設的權重系數,計算所述各第二股票重排序向量的非單調交叉點取值概率;
根據所述各第二股票重排序向量的非單調交叉點取值概率,計算第一股票到第二股票方向的交叉置換熵;
根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。
在其中一個實施例中,在所述獲取第一原始股票序列和第二原始股票序列的步驟之后,所述方法還包括:
將所述第一原始股票序列和所述第二原始股票序列進行時間同步處理,獲取第一股票同步后序列和第二股票同步后序列;
對所述第一股票同步后序列和第二股票同步后序列進行標準化處理,獲取第一股票標準化序列和第二股票標準化序列,
所述根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量,還包括:
根據預設的嵌入維數、預設的嵌入延遲、所述第一股票標準化序列和所述第二股票標準化序列,構建各第一股票狀態向量和各第二股票狀態向量。
在其中一個實施例中,所述根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量,包括:
以所述預設的嵌入延遲為提取步長,在所述第一原始股票序列和所述第二原始股票序列中,分別從第一個數據開始提取預設的嵌入維數個數據,組成所述第一原始股票序列和所述第二原始股票序列的第一個狀態向量,直至最后一個狀態向量的最后一個數據為所述第一原始股票序列和所述第二原始股票序列的最后一個數據為止。
在其中一個實施例中,所述對所述各第一股票狀態向量進行排序,獲取各第一股票重排序向量,并根據所述各第一股票重排序向量和所述各第二股票狀態向量,獲取各第二股票重排序向量,包括:
對所述各第一股票狀態向量進行非遞減排序,獲取所述各第一股票重排序向量;
根據所述各第一股票重排序向量,獲取所述各第一股票重排序向量的位置向量;
根據所述各第一股票重排序向量的位置向量,對與所述各第一股票重排序向量相對應的各第二股票狀態向量進行排序,獲取所述各第二股票重排序向量。
在其中一個實施例中,所述預設的權重系數包括:
根據所述第二股票重排序向量的特征值計算所述預設的權重系數,所述特征值包括算術平均值、方差值、相關系數、連乘累計賦權值其中的一個。
在其中一個實施例中,在根據所述各第二股票重排序向量的非單調交叉點取值概率,計算第一股票到第二股票方向的交叉置換熵的步驟之后,所述方法還包括:
對所述各第二股票狀態向量進行排序,獲取各第二股票重排序向量,并根據所述各第二股票重排序向量和所述各第一股票狀態向量,獲取各第一股票重排序向量;
根據所述各第一股票重排序向量和預設的權重系數,計算所述各第一股票重排序向量的非單調交叉點取值概率;
根據所述各第一股票重排序向量的非單調交叉點取值概率,計算第二股票到第一股票方向的交叉置換熵;
根據所述第一股票到第二股票方向的交叉置換熵和所述第二股票到第一股票方向的交叉置換熵,確定所述第一原始股票序列和第二原始股票序列的耦合方向。
本發明所提供的股票分析方法,提取兩個股票的原始數據后,按照預設的嵌入維數和嵌入延遲,分別構建各第一股票狀態向量和各第二股票狀態向量,將各所述第一股票狀態向量進行重排序后,根據排序后的第一股票重排序向量,獲取各第二股票重排序向量,再根據所述各第二股票重排序向量和預設的權重系數,計算第一股票到第二股票方向的交叉置換熵,最后根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。本發明所提供的股票分析方法,對于價格波動大的股票的分析,計算出來的股票間的耦合強度結果更加準確。
在其中一個實施例中,對原始的股票數據進行同步及標準化的處理,使得用于分析的基礎數據更加完善和標準,從而使得股票間的耦合強度的計算結果更加準確。
在其中一個實施例中,根據第一股票狀態向量非遞減排序后的位置向量,對第二股票狀態向量進行排序,能夠挖掘不同股票間的關聯度,在股票間的耦合強度的計算結果中,體現股票間的關聯強度。
在其中一個實施例中,根據重排序后的股票狀態向量的特征值,設定權重系數,加入非單調交叉點取值概率的計算中,能夠更好的體現狀態向量的選定特征,在最終的股票關聯度的計算結果中,更好的體現原始股票數據的波動性等特征。
在其中一個實施例中,通過比較兩只股票間的相互之間的耦合強度,確定所述兩只股票間的耦合方向,在確定股票間耦合強度的同時,進一步確定股票間的耦合方向,為股票間的關聯性分析提供了更加清晰的關聯方向。
本發明還提供一種股票分析系統,包括:
原始股票序列獲取模塊,用于獲取第一原始股票序列和第二原始股票序列;
狀態向量構建模塊,用于根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量;
重排序向量確定模塊,用于對所述各第一股票狀態向量進行排序,獲取各第一股票重排序向量,并根據所述各第一股票重排序向量和所述各第二股票狀態向量,獲取各第二股票重排序向量;
交叉點取值概率計算模塊,用于根據所述各第二股票重排序向量和預設的權重系數,計算所述各第二股票重排序向量的非單調交叉點取值概率;
交叉置換熵計算模塊,用于根據所述各第二股票重排序向量的非單調交叉點取值概率,計算第一股票到第二股票方向的交叉置換熵;
耦合強度確定模塊,用于耦合強度確定模塊,用于根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。
在其中一個實施例中,還包括:
序列同步模塊,用于將所述第一原始股票序列和所述第二原始股票序列進行時間同步處理,獲取第一股票同步后序列和第二股票同步后序列;
序列標準化模塊,用于對所述第一股票同步后序列和第二股票同步后序列進行標準化處理,獲取第一股票標準化序列和第二股票標準化序列,
所述重排序向量確定模塊,還用于根據預設的嵌入維數、預設的嵌入延遲、所述第一股票標準化序列和所述第二股票標準化序列,構建各第一股票狀態向量和各第二股票狀態向量。
在其中一個實施例中,所述狀態向量構建模塊,用于以所述預設的嵌入延遲為提取步長,在所述第一原始股票序列和所述第二原始股票序列中,分別從第一個數據開始提取預設的嵌入維數個數據,組成所述第一原始股票序列和所述第二原始股票序列的第一個狀態向量,直至最后一個狀態向量的最后一個數據為所述第一原始股票序列和所述第二原始股票序列的最后一個數據為止。
在其中一個實施例中,所述重排序向量確定模塊,包括:
狀態向量排序單元,用于對所述各第一股票狀態向量進行非遞減排序,獲取所述各第一股票重排序向量;
位置向量獲取單元,用于根據所述各第一股票重排序向量,獲取所述各第一股票重排序向量的位置向量;
重排序向量獲取單元,用于根據所述各第一股票重排序向量的位置向量,對與所述各第一股票重排序向量相對應的各第二股票狀態向量進行排序,獲取所述各第二股票重排序向量。
在其中一個實施例中,所述預設的權重系數,包括根據所述第二股票重排序向量的特征值計算所述預設的權重系數,所述特征值包括算術平均值、方差值、相關系數、連乘累計賦權值其中的一個。
在其中一個實施例中,所述狀態向量構建模塊,還用于對所述各第二股票狀態向量進行排序,獲取各第二股票重排序向量,并根據所述各第二股票重排序向量和所述各第一股票狀態向量,獲取各第一股票重排序向量;
所述交叉點取值概率計算模塊,還用于根據所述各第一股票重排序向量的非單調交叉點取值概率,計算第二股票到第一股票方向的交叉置換熵;
所述交叉置換熵計算模塊,還用于根據所述各第一股票重排序向量的非單調交叉點取值概率,計算第一股票的交叉置換熵;
耦合方向確定模塊,用于根據所述第一股票到第二股票方向的交叉置換熵和所述第二股票到第一股票方向的交叉置換熵,確定所述第一原始股票序列和第二原始股票序列的耦合方向。
本發明所提供的股票分析系統,提取兩個股票的原始數據后,按照預設的嵌入維數和嵌入延遲,分別構建各第一股票狀態向量和各第二股票狀態向量,將各所述第一股票狀態向量進行重排序后,根據排序后的第一股票重排序向量,獲取各第二股票重排序向量,再根據所述各第二股票重排序向量和預設的權重系數,計算第一股票到第二股票方向的交叉置換熵,最后根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。本發明所提供的股票分析系統,對于價格波動大的股票的分析,計算出來的股票間的耦合強度結果更加準確。
在其中一個實施例中,對原始的股票數據進行同步及標準化的處理,使得用于分析的基礎數據更加完善和標準,從而使得股票間的耦合強度的計算結果更加準確。
在其中一個實施例中,根據第一股票狀態向量非遞減排序后的位置向量,對第二股票狀態向量進行排序,能夠挖掘不同股票間的關聯度,在股票間的耦合強度的計算結果中,體現股票間的關聯強度。
在其中一個實施例中,根據重排序后的股票狀態向量的特征值,設定權重系數,加入非單調交叉點取值概率的計算中,能夠更好的體現狀態向量的選定特征,在最終的股票關聯度的計算結果中,更好的體現原始股票數據的波動性等特征。
在其中一個實施例中,通過比較兩只股票間的相互之間的耦合強度,確定所述兩只股票間的耦合方向,在確定股票間耦合強度的同時,進一步確定股票間的耦合方向,為股票間的關聯性分析提供了更加清晰的關聯方向。
附圖說明
圖1為一個實施例中的股票分析方法的流程示意圖;
圖2為另一個實施例中的股票分析方法的流程示意圖;
圖3為又一個實施例中的股票分析方法的流程示意圖;
圖4為重排序向量的走勢圖;
圖5為一個實施例中的股票分析系統的結構示意圖;
圖6為另一個實施例中的股票分析系統的結構示意圖;
圖7為又一個實施例中的股票分析系統的結構示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅用以解釋本發明,并不用于限定本發明。
圖1為一個實施例中的股票分析方法的流程示意圖,如圖1所示的股票分析方法包括:
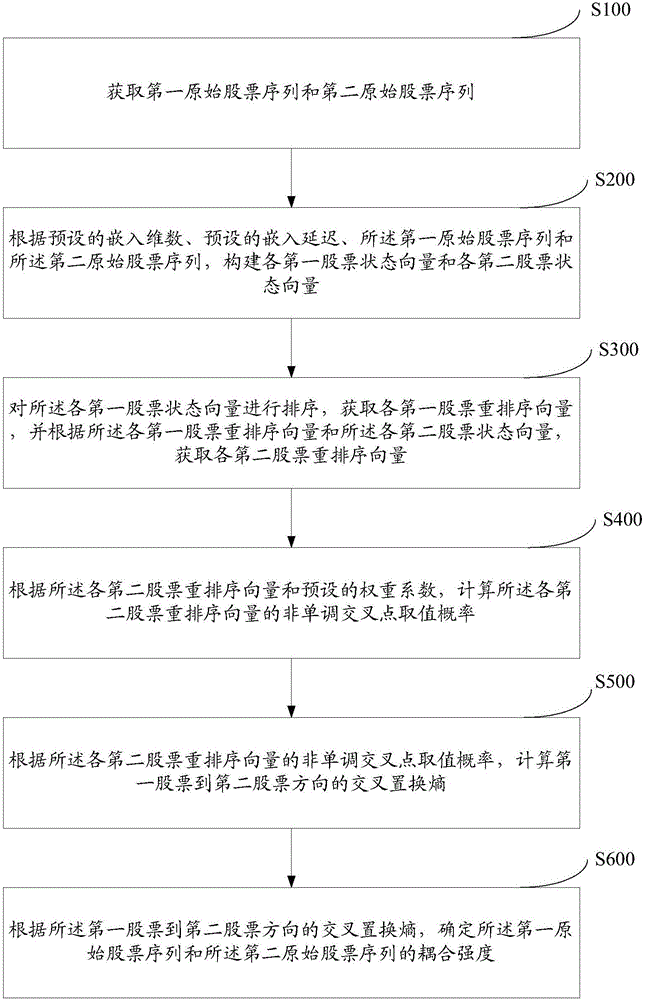
步驟S100,獲取第一原始股票序列和第二原始股票序列。
具體的,獲取任意兩個需要計算相關性的股票的原始數據,且所述兩個股票的原始數據需按照相同的時段提取。
例如,獲取兩個股票的原始序列分別為(xi,i=1,2,...,N}和和(yi,i=1,2,...,N}。
步驟S200,根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量。
具體的,為分析所述兩個原始股票序列之間的關聯性,首先根據預設的嵌入維數和嵌入時延,構建兩個股票的狀態向量。所述嵌入維數和所述嵌入延遲,用于將原始股票序列構建為預設的多維度的數據向量后,進行后續交叉置換熵的計算。
以所述預設的嵌入延遲為提取步長,在所述第一原始股票序列和所述第二原始股票序列中,分別從第一個數據開始提取預設的嵌入維數個數據,組成所述第一原始股票序列和所述第二原始股票序列的第一個狀態向量,直至最后一個狀態向量的最后一個數據為所述第一原始股票序列和所述第二原始股票序列的最后一個數據為止。
分別計算步驟S100中的兩個原始股票序列在s維空間上的狀態向量:
Xt={xt,xt+τ,xt+2τ,...,xt+(s-1)τ}
Yt={yt,yt+τ,yt+2τ,...yt+(s-1)τ}
其中τ為嵌入延遲,t=1,2,…,N-(s-1)τ。在狀態向量重構步驟中,嵌入維數s與嵌入延遲的選擇十分重要,維數s的選擇要保證時間序列的重構不會破壞序列本身的任何拓撲結構;嵌入延遲τ不可過大填充整個狀態空間,也不可使重構的狀態空間主對角線坍塌,本方案中,取用時間延遲τ恒等于1。
舉例說明,假設第一原始股票序列為{X1,X2,X3,X4,X5},以3為嵌入維度,1為嵌入步長,獲取到的第一股票狀態向量為:
若以3為嵌入維度,2為嵌入步長,則獲取到的第一股票狀態向量為:
步驟S300,對所述各第一股票狀態向量進行排序,獲取各第一股票重排序向量,并根據所述各第一股票重排序向量和所述各第二股票狀態向量,獲取各第二股票重排序向量;
具體的,對所述第一股票狀態向量進行排序,可采用非遞減排序的方式,也可采用非遞增排序的方式。
例如,對所述各第一股票狀態向量進行非遞減排序,獲取所述各第一股票重排序向量;根據所述各第一股票重排序向量,獲取所述各第一股票重排序向量的位置向量;根據所述各第一股票重排序向量的位置向量,對與所述各第一股票重排序向量相對應的各第二股票狀態向量進行排序,獲取所述各第二股票重排序向量。
設第一股票狀態向量為Xt’,第二股票狀態向量為Yt’,首先對Xt’向量進行非遞減的排列,并以π(X)表示其置換的位置(也就是原數據在向量Xt’中的位置),例如,π(X):以π(X)記錄的位置為標準,重新排列向量Yt’,結果記為gt(X,Y)=Yt(π(X))。由于兩條完全同步的向量按照上述規則重新排列之后,gt(X,Y)會是一條單調遞增的序列,因此可以以gt(X,Y)的單調遞增程度來量化向量之間的同步性水平。
舉例說明,如第一個第一股票狀態向量為(14,12,18),第一個第二股票狀態向量為(21,25,28)對所述第一個第一股票狀態向量進行非遞減排序后,變為(12,14,18),其位置向量為(2,1,3),相應的第二個股票重排序向量為(25,21,28)。
步驟S400,根據所述各第二股票重排序向量和預設的權重系數,計算所述各第二股票重排序向量的非單調交叉點取值概率;
具體的,計算所述各第二股票重排序向量的非單調交叉點取值概率,在序列gt(X,Y)的曲線上,對每一個數據點自左向右畫水平線,水平線與序列本身組成的曲線之間的交叉點總數即為gt(X,Y)的單調遞增程度,具體過程如圖4所示,圖4表示Xt’與Yt’的原始走勢,黑色曲線表示以從小到大的順序排列Xt’之后的走勢圖,灰色曲線表示以π(X)的位置,重新排列向量Yt’之后的曲線走勢,圓圈表示交叉點。
將上述過程遍歷第二股票重排序向量的所有狀態向量,并記第t個區間內交叉點數目為κt:
其中Θ[x]是Heaviside函數,定義為:
若第一股票重排序向量和第二股票重排序向量是完全同步的,那么gt(X,Y)應該是一條單調遞增的序列,此時交叉點數目為0。另外,在每個區間內,交叉點個數的最大值為Δ=(s-1)(s-2)/2,因此區間內交叉點的數目可以表示為唯一的整數δ,δi∈[0,Δ],i=1,2,...,Δ+1。統計所有區間內交叉點的個數κt,總共會有Δ+1種取值,分別計算每一個取值可能出現的相對頻率:
其中1≤t≤N-(s-1)τ,0≤i≤Δ+1,#為集合的勢,也就是滿足條件的元素個數。
實際應用中,對于波動劇烈,帶有脈沖的序列,只提取排序結構的信息,很多時間序列中的振幅信息可能會丟失。為了量化波動幅度較大序列間的耦合性,本步驟通過增加一個權重ω來提升算法的信息量和精準度。
定義新的相對頻率為:
其中1≤t≤N-(s-1)τ,0≤i≤Δ,1A(U)表示集合A的指示函數,定義為:
根據所述第二股票重排序向量的特征值計算所述預設的權重系數,所述特征值包括算術平均值、方差值、相關系數、連乘累計賦權值其中的一個。
舉例說明,權重ωt可以使用兩個相鄰向量gt(X,Y)的均值計算:
權重ωt也可以使用兩個相鄰向量gt(X,Y)的方差計算:
其中表示gt(X,Y)的算術平均值。
步驟S500,根據所述各第二股票重排序向量的非單調交叉點取值概率,計算第一股票到第二股票方向的交叉置換熵。
具體的,根據上述非單調交叉點取值概率,獲得兩條原始時間序列在耦合模式下的概率分布P={p(δi),i=1,2,...,Δ+1},以香農熵形式定義的交叉置換熵(CPE)即為:
步驟S600,根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。
具體的,根據所述第一股票到第二股票方向的交叉置換熵,可以用來判斷所述第一原始股票序列和所述第二原始股票序列的耦合強度。若熵值越大,兩個股票原始序列之間的耦合強度就越弱,當兩個股票原始序列完全隨機時,熵值達到最大。理想情況下,若兩個股票原始序列相對頻率滿足均一分布,即那么對應的熵值會達到理論最大值log(Δ+1)。
本發明所提供的股票分析方法,提取兩個股票的原始數據后,按照預設的嵌入維數和嵌入延遲,分別構建各第一股票狀態向量和各第二股票狀態向量,將各所述第一股票狀態向量進行重排序后,根據排序后的第一股票重排序向量,獲取各第二股票重排序向量,再根據所述各第二股票重排序向量和預設的權重系數,計算第一股票到第二股票方向的交叉置換熵,最后根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。本發明所提供的股票分析方法,對于價格波動大的股票的分析,計算出來的股票間的耦合強度結果更加準確。
在本實施例中,根據第一股票狀態向量非遞減排序后的位置向量,對第二股票狀態向量進行排序,能夠挖掘不同股票間的關聯度,在股票間的耦合強度的計算結果中,體現股票間的關聯強度。
在本實施例中,根據重排序后的股票狀態向量的特征值,設定權重系數,加入非單調交叉點取值概率的計算中,能夠更好的體現狀態向量的選定特征,在最終的股票關聯度的計算結果中,更好的體現原始股票數據的波動性等特征。
圖2為另一個實施例中的股票分析方法的流程示意圖,如圖2所示的股票分析方法包括:在圖1所示的實施例中,在步驟S100之前,所述方法還包括一下步驟:
步驟S80,將所述第一原始股票序列和所述第二原始股票序列進行時間同步處理,獲取第一股票同步后序列和第二股票同步后序列。
具體的,由于取到的統一時段的原始股票數據,會存在數據遺漏等,所述第一原始股票序列和所述第二原始股票序列不能完全同步,導致最終的計算結果不準確,因此需要進行時間同步處理。
所述時間同步處理,包括剔除不能在時間上一一對應的股票原始數據,將缺失的數據進行插值等。最終獲取到時間完全同步的兩個原始股票序列。
步驟S90,對所述第一股票同步后序列和第二股票同步后序列進行標準化處理,獲取第一股票標準化序列和第二股票標準化序列。
具體的,為使最終的計算結果更加的準確,在對原始股票序列進行時間同步后,再進行數據的標準化處理。例如,采用如下標準化處理公式:
其中min(x)與max(x)分別為序列x的最小值與最大值。
相應的,圖1所示的實施例中,步驟S100的所述根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量,還包括:
根據預設的嵌入維數、預設的嵌入延遲、所述第一股票標準化序列和所述第二股票標準化序列,構建各第一股票狀態向量和各第二股票狀態向量。
在本實施例中,對原始的股票數據進行同步及標準化的處理,使得用于分析的基礎數據更加完善和標準,從而使得股票間的耦合強度的計算結果更加準確。
圖3為又一個實施例中的股票分析方法的流程示意圖,如圖3所示的股票分析方法包括:在圖1所示的方法之后,還包括如下步驟:
步驟S700,對所述各第二股票狀態向量進行排序,獲取各第二股票重排序向量,并根據所述各第二股票重排序向量和所述各第一股票狀態向量,獲取各第一股票重排序向量。
具體的,同圖1中的步驟300。
步驟S800,根據所述各第一股票重排序向量和預設的權重系數,計算所述各第一股票重排序向量的非單調交叉點取值概率。
具體的,同圖1中的步驟400。
步驟S900,根據所述各第一股票重排序向量的非單調交叉點取值概率,計算第二股票到第一股票方向的交叉置換熵。
具體的,同圖1中的步驟500。
步驟S1000,根據所述第一股票到第二股票方向的交叉置換熵和所述第二股票到第一股票方向的交叉置換熵,確定所述第一原始股票序列和第二原始股票序列的耦合方向。
具體的,通過比較所述第一股票到第二股票方向的交叉置換熵和所述第二股票到第一股票方向的交叉置換熵,可以分別得出所述第一股票原始序列與所述第二股票原始序列之間的兩個關聯強度,利用兩個所述關聯強度的大小,可以獲取到所述兩只股票之間的關聯方向。例如,所述第一股票原始序列對于所述第二股票原始序列的關聯強度,大于所述第二股票原始序列對于所述第一股票原始序列的關聯強度,則所述第一只股票關聯于所述第二只股票。
在本實施例中,通過比較兩只股票間的相互之間的耦合強度,確定所述兩只股票間的耦合方向,在確定股票間耦合強度的同時,進一步確定股票間的耦合方向,為股票間的關聯性分析提供了更加清晰的關聯方向。
圖5為一個實施例中的股票分析系統的結構示意圖,如圖5所示的股票分析系統包括:
原始股票序列獲取模塊100,用于獲取第一原始股票序列和第二原始股票序列。
狀態向量構建模塊200,用于根據預設的嵌入維數、預設的嵌入延遲、所述第一原始股票序列和所述第二原始股票序列,構建各第一股票狀態向量和各第二股票狀態向量;用于以所述預設的嵌入延遲為提取步長,在所述第一原始股票序列和所述第二原始股票序列中,分別從第一個數據開始提取預設的嵌入維數個數據,組成所述第一原始股票序列和所述第二原始股票序列的第一個狀態向量,直至最后一個狀態向量的最后一個數據為所述第一原始股票序列和所述第二原始股票序列的最后一個數據為止。包括:狀態向量排序單元,用于對所述各第一股票狀態向量進行非遞減排序,獲取所述各第一股票重排序向量;位置向量獲取單元,用于根據所述各第一股票重排序向量,獲取所述各第一股票重排序向量的位置向量;重排序向量獲取單元,用于根據所述各第一股票重排序向量的位置向量,對與所述各第一股票重排序向量相對應的各第二股票狀態向量進行排序,獲取所述各第二股票重排序向量。
重排序向量確定模塊300,用于對所述各第一股票狀態向量進行排序,獲取各第一股票重排序向量,并根據所述各第一股票重排序向量和所述各第二股票狀態向量,獲取各第二股票重排序向量。
交叉點取值概率計算模塊400,用于根據所述各第二股票重排序向量和預設的權重系數,計算所述各第二股票重排序向量的非單調交叉點取值概率;所述預設的權重系數,包括根據所述第二股票重排序向量的特征值計算所述預設的權重系數,所述特征值包括算術平均值、方差值、相關系數、連乘累計賦權值其中的一個。
交叉置換熵計算模塊500,用于根據所述各第二股票重排序向量的非單調交叉點取值概率,計算第一股票到第二股票方向的交叉置換熵。
耦合強度確定模塊600,用于根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。
本發明所提供的股票分析系統,提取兩個股票的原始數據后,按照預設的嵌入維數和嵌入延遲,分別構建各第一股票狀態向量和各第二股票狀態向量,將各所述第一股票狀態向量進行重排序后,根據排序后的第一股票重排序向量,獲取各第二股票重排序向量,再根據所述各第二股票重排序向量和預設的權重系數,計算第一股票到第二股票方向的交叉置換熵,最后根據所述第一股票到第二股票方向的交叉置換熵,確定所述第一原始股票序列和所述第二原始股票序列的耦合強度。本發明所提供的股票分析系統,對于價格波動大的股票的分析,計算出來的股票間的耦合強度結果更加準確。
在本實施例中,根據第一股票狀態向量非遞減排序后的位置向量,對第二股票狀態向量進行排序,能夠挖掘不同股票間的關聯度,在股票間的耦合強度的計算結果中,體現股票間的關聯強度。
在本實施例中,根據重排序后的股票狀態向量的特征值,設定權重系數,加入非單調交叉點取值概率的計算中,能夠更好的體現狀態向量的選定特征,在最終的股票關聯度的計算結果中,更好的體現原始股票數據的波動性等特征。
圖6為另一個實施例中的股票分析系統的結構示意圖,如圖6所示的股票分析系統包括:
序列同步模塊80,用于將所述第一原始股票序列和所述第二原始股票序列進行時間同步處理,獲取第一股票同步后序列和第二股票同步后序列。
序列標準化模塊90,用于對所述第一股票同步后序列和第二股票同步后序列進行標準化處理,獲取第一股票標準化序列和第二股票標準化序列。
所述狀態向量構建模塊200,還用于根據預設的嵌入維數、預設的嵌入延遲、所述第一股票標準化序列和所述第二股票標準化序列,構建各第一股票狀態向量和各第二股票狀態向量。
在本實施例中,對原始的股票數據進行同步及標準化的處理,使得用于分析的基礎數據更加完善和標準,從而使得股票間的耦合強度的計算結果更加準確。
圖7為又一個實施例中的股票分析系統的結構示意圖,如圖7所示的股票分析系統包括:
所述重排序向量確定模塊300,還用于對所述各第二股票狀態向量進行排序,獲取各第二股票重排序向量,并根據所述各第二股票重排序向量和所述各第一股票狀態向量,獲取各第一股票重排序向量;
所述交叉點取值概率計算模塊400,還用于根據所述各第一股票重排序向量和預設的權重系數,計算所述各第一股票重排序向量的非單調交叉點取值概率;
所述交叉置換熵計算模塊500,還用于根據所述各第一股票重排序向量的非單調交叉點取值概率,計算第二股票到第一股票方向的交叉置換熵;
耦合方向確定模塊700,用于根據所述第一股票到第二股票方向的交叉置換熵和所述第二股票到第一股票方向的交叉置換熵,確定所述第一原始股票序列和第二原始股票序列的耦合方向。
在本實施例中,通過比較兩只股票間的相互之間的耦合強度,確定所述兩只股票間的耦合方向,在確定股票間耦合強度的同時,進一步確定股票間的耦合方向,為股票間的關聯性分析提供了更加清晰的關聯方向。
以上所述實施例的各技術特征可以進行任意的組合,為使描述簡潔,未對上述實施例中的各個技術特征所有可能的組合都進行描述,然而,只要這些技術特征的組合不存在矛盾,都應當認為是本說明書記載的范圍。
以上所述實施例僅表達了本發明的幾種實施方式,其描述較為具體和詳細,但并不能因此而理解為對發明專利范圍的限制。應當指出的是,對于本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變形和改進,這些都屬于本發明的保護范圍。因此,本發明專利的保護范圍應以所附權利要求為準。
- 還沒有人留言評論。精彩留言會獲得點贊!