一種基于視頻流與人臉多屬性匹配的三維人臉建模方法和打印裝置與流程
本發明涉及人臉三維建模技術,特別是涉及一種基于視頻流與人臉多屬性匹配的三維人臉建模方法和打印裝置。
背景技術:
許多研究者充分利用計算機在處理圖像圖形方面的優良性能來模擬和演示三維人臉模型并取得了很大成就。人臉動畫已經從傳統的關鍵幀技術發展到表演驅動技術。從可視電話到游戲娛樂,從多通道用戶界面到虛擬現實,到處都體現著人臉建模與動畫的技術。同時,人們對利用計算機進行三維人臉建模的效果和質量要求也越來越嚴格,不再僅僅滿足于動作僵硬、表情呆板、背景單調的三維人臉及其動畫。如何提高建模精確度、豐富模型表情逼真度的技術問題,仍然是該領域的研究熱點和研究者共同追求的目標。
目前,關于三維人臉建模的方法主要包括如下幾種:1)基于三維掃描儀的三維人臉建模;2)基于單幅人臉圖像的建模;3)基于擬合或重建的技術。
但是,現有的三維人臉建模技術存在以下幾個問題:
基于三維掃描儀的方法往往存在通用性和靈活性較差的問題,此外,其建模過程的數據量大,操作較為復雜,且其硬件設備的成本昂貴,計算復雜度過高。
基于單幅人臉圖像的建模方法由于計算過程復雜,從而導致運算時間過長、計算結果偏差大等不足,通常難以獲得良好的建模效果。
基于擬合或重建的技術一般都需要用戶的配合,用戶友好性較差。例如手工標記關鍵點、使用前進行用戶注冊、在建模時需保持無表情或者固定表情等,不能精確地模擬實時的用戶表情;同時,外貌、姿態對表情參數精度的影響較大,導致建模精度存在一定的瓶頸。
技術實現要素:
為克服現有技術的不足,本發明的目的在于提供一種精確度高、實現方式簡單、用戶友好性好、自動快速、建模結果逼真且極具個性化的三維人臉建模方法和裝置。
本發明為解決其技術問題采用的技術方案是:
一種基于視頻流與人臉多屬性匹配的三維人臉建模方法,包括:
建立通用三維人臉模型庫,所述三維人臉模型庫按照屬性分類,所述屬性包括性別、年齡、臉型;
采集實時視頻中的多幅正側面人臉圖像進行歸一化處理,通過預先訓練好的多任務學習深度神經網絡進行人臉檢測及人臉關鍵點信息提取,并結合多人臉個關鍵點信息對齊人臉;
利用預先訓練好的多任務學習深度神經網絡進行人臉屬性分析預測,所述屬性包括性別、年齡、臉型,結合人臉關鍵點數據和人臉屬性信息與所述的通用三維人臉模型庫進行粗配準,獲得最接近實時采集的人臉通用模型;
采用關鍵點優化技術和紋理細化處理技術對粗配準的通用三維人臉模型進行微調修正,合成具有真實感的實時三維人臉視覺外觀。
進一步,所述建立通用三維人臉模型庫,三維人臉模型庫按照屬性分類具體包括:
利用三維掃描儀采集原始真實的三維人臉模型并進行規一化處理;
對規一化人臉模型的形狀和紋理分別進行主成分分析,得到形變三維人臉模型,最終由三維掃描儀采集到的原始三維人臉模型和經過形變處理的三維人臉模型構成完備的通用三維人臉模型庫。
對完備通用三維人臉模型庫標注其對應的屬性,所述屬性包括性別、年齡、臉型,并根據屬性對應的類別建立最終的通用三維人臉模型庫。
進一步,所述對完備通用三維人臉模型庫標注其對應的屬性具體包括:
以性別細分為男、女兩項;
以年齡段為分類項,共設為兒童、少年、青年、中年、老年5大類,其中兒童時期細分為0-3、4-6歲,少年時期細分為7-12、13-17歲,青年時期細分為18-25、26-40歲,中年時期細分為41-50、51-65歲,老年時期為66歲以上;
以臉型為分類項,將每個年齡段分為多種臉型,分別是橢圓臉型、長臉型、四方臉型、倒三角型、菱形臉型、三角臉型、圓臉型。
進一步,所述人臉關鍵點包括:臉部輪廓、眼角點、眉間點、鼻下點、頜下點、嘴角點。
進一步,所述多任務學習深度神經網絡的訓練過程具體包括:
采集標準人臉圖像并標注其對應的多個屬性的類別,形成一個完備的訓練數據集合;
同時進行人臉檢測以及人臉關鍵點定位,并結合多個關鍵點坐標信息準確對齊人臉;
對標注類別中的屬性進行編碼;
構造深度神經網絡;
利用訓練數據集合,訓練深度神經網絡,最終通過大量訓練獲得多任務學習深度神經網絡模型。
進一步,所述深度神經網絡依次包括:輸入層、卷積層、非線性層、池化層、二次卷積層、混合卷積層、多屬性分類層、輸出層;
所述卷積層、非線性層、池化層、二次卷積層分別設置有一個或者一個以上,卷積層的輸出作為非線性層或者池化層或者二次卷積層的輸入,非線性層的輸出作為下一個卷積層的輸入;
二次卷積層和池化層的輸出作為混合卷積層的輸入;
混合卷積層的輸出作為多屬性分類層的輸入;
多屬性分類層的輸出連接輸出層,最終輸出分類結果。
進一步,所述采用關鍵點優化技術具體包括:
首先構造所述人臉關鍵點信息組合向量A={xc1,xc2,xc3…xcn},其中xci(i=1,2,3…n)表示所述的關鍵點信息的第i種信息子向量;
然后通過凸優化目標函數得到最優解使得所對齊的人臉關鍵點參數誤差最小;
其中,優化目標函數的約束條件為:θi≥0,∑θi=1;
表示所對齊的關鍵點和目標關鍵點之間的偏差,x為所述的關鍵點信息任意一種信息子向量,符號minθ表示關于求θ極小值,符號||||表示關于求范數;
最后根據最優解對所匹配獲得的通用三維人臉模型進行人臉關鍵點精確對齊。
進一步,所述的紋理細化處理技術,具體包括:
首先計算人臉紋理的有效區域,在紋理圖像上,如果一個像素所對應的頂點在圖像上的投影坐標位于人臉輪廓之內,并且該頂點在投影角度下是可見的,則相應的像素就位于人臉紋理的有效區域內;
計算每個像素處的位置確定度p,將位置確定度作為代價函數中該像素處的權重,位置確定度定義為投影方向與頂點的法向量之間夾角的余弦;
為重建的三維人臉模型加入兩個光照,分別位于三維人臉模型的左前方和右前方各45度,光照的位置固定且強度可變;
以形狀無關紋理SIFT為擬合的目標圖像,以人臉形變模型的紋理分量合成人臉紋理S1;將代價函數Eξ設置為合成的紋理圖像與目標圖像之間的偏差,代價函數在紋理的有效區域內進行計算,通過目標函數Eξ>0利用梯度下降法將求得代價函數最小值,然后得到合成的紋理圖像S;
選取一個紋理融合的優化系數I,將合成的人臉紋理圖像S與形狀無關紋理SIFT進行融合,取出形狀無關紋理的中心區域補充到合成的紋理圖像上,以補充人臉的細節,得到最終融合后的紋理R,其中R=I·SIFT+(1-I)·S。
本發明還提供了一種基于視頻流與人臉多屬性匹配的三維人臉建模打印裝置,包括:
輸入單元,用于獲取實時視頻流中的原始人臉圖像;
特征點標記單元,用于在所述原始人像上標記特征點并記錄其坐標信息;
通用三維人臉模型庫單元,存儲有通用三維人臉模型庫離線包;
人臉多屬性分類單元,用于通過對多個人臉屬性任務進行聯合訓練,用一個深度網絡同時完成多個人臉屬性目標分類任務,包括進行人臉檢測、人臉關鍵點信息提取以及人臉多屬性分析預測;
人臉關鍵點優化單元,用于提取原始人像上標記特征點及坐標信息,采用凸優化方法進行人臉關鍵點優化和人臉精準對齊;
人臉紋理細化單元,對初步獲取的通用三維人臉模型進行紋理細化;
打印輸出單元,用于輸出顯示并打印建模結果。
本發明的有益效果是:具有精確度高、實現方式簡單、用戶友好性好、自動化程度高等優點,能夠更直觀、完整地獲得人臉的正面紋理信息、深度信息等,從而有利于建立起更加細膩逼真、快速精確且極具個性化的三維人臉模型。本發明提供的三維人臉建模打印裝置,能極大地降低傳統激光掃描進行三維人臉建模的成本和制作時間。
附圖說明
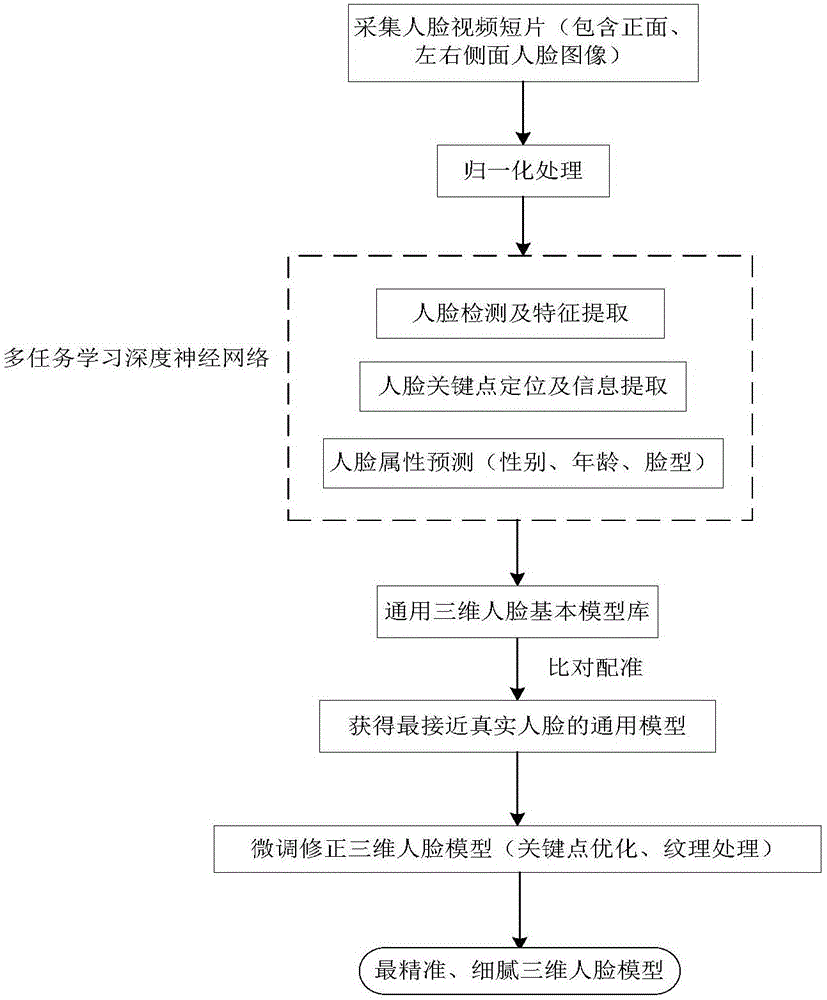
圖1是本發明的一種基于視頻流與人臉多屬性匹配的三維人臉建模方法的流程圖;
圖2是本發明所述的多人臉屬性任務學習深度神經網絡示意圖;
圖3是本發明所述的三維人臉建模打印裝置的結構示意圖。
具體實施方式
以下結合附圖和實例對本發明做進一步說明。
如圖1所示,本發明提供了一種基于視頻流與人臉多屬性匹配的三維人臉建模方法,該方法過程詳述如下。
步驟S1:利用三維掃描儀人工采集原始三維人臉模型數據,并人工標注其對應的屬性(性別、年齡、臉型),同時根據屬性對應的類別建立通用三維人臉模型庫。
在一實施例中,步驟1具體包括:
S11,采用三維掃描儀采集真實的三維人臉模型后進行規一化處理。
S12,對規一化人臉模型的形狀和紋理分別進行主成分分析(PCA),獲得人臉形變模型,目的在于增加模型樣本,豐富三維人臉模型數據庫,構建完備的通用三維人臉模型庫,構建三維人臉形變模型的具體方法包括:
設S和T分別為新的三維人臉模型的形狀和紋理,S0為人臉形變模型的平均形狀,T0為人臉形變模型的平均紋理,Sk(1≤k≤M)為人臉形變模型的第k個形狀分量,Tk(1≤k≤M)為人臉形變模型的第k個紋理分量,αk為重建人臉模型的第k個形狀參數,βk為重建人臉模型的第k個紋理參數,M為人臉形變模型的個數,k為1到M之間的整數。即根據主成分分析方法經驗均值理論得:
得到形變三維人臉模型后,最終由三維掃描儀采集到的原始三維人臉模型和經過形變的三維人臉模型組成完備的三維人臉模型庫。
S13,最后對完備三維人臉模型人工標注其對應的屬性(性別、年齡、臉型),并將通用人臉模型庫以人臉多屬性進行分類,具體過程如下:
S131,以性別分為男、女兩項;
S132,以年齡段為分類項,在男、女兩項下又分為兒童、少年、青年、中年、老年9個階段,其中兒童時期為0-3、4-6歲,少年時期為7-12、13-17歲,青年時期為18-25、26-40歲,中年時期為41-50、51-65歲,老年時期為66歲以上;
S133,以臉型為分類項,將每個年齡段分為7種臉型,分別是橢圓臉型、長臉型、四方臉型、倒三角型、菱形臉型、三角臉型、圓臉型,共有7個臉型項目。
在每種三維人臉模型的采集過程中,所述性別分為男女共126(男63、女63)種三維人臉模型。每種三維人臉模型采集10個人臉數據,整個三維人臉模型庫共需采集1260個人臉數據。
將每種三維人臉模型的10個人臉數據進行平均化處理,利用加權平均技術得到恰當的合成的平均臉,即是從1260個人臉數據中獲取126個平均臉的三維人臉模型,再利用主成分分析法得到形變人臉模型。最終由三維掃描儀采集到的原始三維人臉模型和經過形變處理的三維人臉模型構成完備的三維人臉模型庫。
需要說明的是,本發明的重點并不在于建立通用三維人臉模型庫,本步驟屬于人工離線完成,故該通用三維人臉模型庫屬離線包,可以下載存儲在本地硬盤中,無需重復建立模型庫,日后的使用都無需再次建庫。
步驟S2:采集實時視頻中的多幅正側面人臉圖像進行歸一化處理,通過預先訓練好的多任務學習深度神經網絡快速進行人臉檢測、人臉關鍵點定位和信息提取,并結合多個關鍵點數據對齊人臉。
為采集實時視頻中的多幅正側面人臉圖像,本實施例中采用多臺攝像頭,在紅外燈照射下從目標人臉的正面及左右面分別進行拍攝,當用戶進入圖像采集區域時,多臺攝像機從多方向不受環境因素影響對圖像采集區域內的用戶進行拍攝,有效地保證所采集圖像的完備性,同時也保證了圖像的質量和人臉的正面紋理信息及深度信息等。
本步驟S2中所述“預先訓練好的多任務學習深度神經網絡”通過對多個屬性任務進行聯合訓練,僅用一個深度網絡同時完成多個目標任務,包括進行人臉檢測、人臉關鍵點信息提取以及人臉屬性分析預測,所述人臉屬性包括但不限于性別、年齡、臉型。
本步驟所述的人臉檢測算法,采用任何一種現有的AdaBoost分類器或深度學習算法實現人臉及人臉關鍵點的檢測即可。
本步驟所述的的人臉關鍵點包括:臉部輪廓、眼角點、眉間點、鼻下點、頜下點、嘴角點等。
本實例中進行人臉檢測之后,根據關鍵點檢測技術,進行人臉特征點定位,精確對齊人臉。
步驟S3:經過預先訓練好的多任務學習深度神經網絡進行人臉屬性分析預測,同時結合多個人臉關鍵點數據和人臉屬性信息與所述的通用三維人臉模型庫進行粗配準,獲得最接近實時采集對象的通用三維人臉模型;需說明的是,所述人臉屬性包括但不限于性別、年齡、臉型,
所述“預先訓練好的多任務學習深度神經網絡”的訓練過程包括:
采集人臉圖像并標注其對應的多個屬性的類別,形成一個完備的訓練數據集合;
進行檢測人臉、人臉關鍵點定位及信息提取,同時結合多個關鍵點坐標信息對齊人臉;
對標注類別中的屬性進行編碼;
構造深度神經網絡;
利用步驟A1形成的訓練數據集合,訓練步驟A4中的深度神經網絡,最終通過大量訓練獲得多任務學習深度神經網絡模型。
圖2是本發明所述的多人臉屬性任務學習深度神經網絡示意圖。下面對深度神經網絡作詳細的說明。
所述深度神經網絡包括:輸入層,卷積層,非線性層,池化層,二次卷積層,混合卷積層,多屬性分類層、輸出層。
所述輸入層用于自動獲取實時視頻流中的原始人臉圖像,同時對人臉圖像進行預處理操作,輸出歸一化的標準人臉圖像,輸入層將經過預處理的人臉圖像輸出至卷積層。
所述卷積層其輸入是經過預處理的人臉圖片或者圖片的圖像特征,通過一線性變換輸出得到新特征。其輸出的新特征為非線性層的輸入、下一個卷積層、池化層或者二次卷積層的輸入。本實施例中,卷積層A輸出的降維新特征為非線性層B的輸入和二次卷積層H的輸入,卷積層C輸出的降維新特征為非線性層D的輸入,卷積層E輸出的降維新特征為二次卷積層I的輸入同時作為卷積層F的輸入,卷積層F輸出的新特征為卷積層E的輸入,卷積層E輸出的新特征為卷積層G的輸入,卷積層G的輸出的降維新特征作為池化層J的輸入。
所述非線性層,其通過神經元激活函數,對卷積層輸入的特征進行非線性變換,使得其輸出的特征有較強的表達能力。非線性層的輸出特征為下一個卷積層的輸入。本實施例中,非線性層B輸出的降維新特征為下一卷積層C的輸入。
所述池化層可以將多個數值映射到一個數值。該層不但可以進一步加強學習所得到的特征的非線性,而且可以使得輸出的特征的維數變小,確保提取的特征保持不變。池化層的輸出特征可以再次作為為卷積層的輸入或者混合卷積層的輸入。本實施例中,經過卷積層F、G后,卷積層G的輸出的降維新特征作為池化層J的輸入。
所述混合卷積層,它對二次卷積層以及池化層的輸出作一個線性變換,把學習得到的特征投影到一個更好的子空間以利于屬性預測。本實施例中,二次卷積層H、I以及池化層J的輸出作為混合卷積層L的輸入。混合卷積層的輸出特征作為多屬性分類層的輸入。
所述多屬性分類層用于對輸入目標任務進行計算分析預測,將分類結果至輸出層。本實施例中,混合卷積層L的輸出特征作為多屬性分類層M的輸入。
所述輸出層用于輸出建模結果。
所述卷積層、非線性層、池化層、二次卷積層分別設置有一個或者一個以上,卷積層、非線性層、池化層三層的多次組合,可以更好的處理輸入的圖像,使其特征具有最佳的表達能力。
步驟S4:采用關鍵點優化技術和紋理細化技術對粗配準的通用三維人臉模型進行微調修正,合成具有真實感的實時三維人臉視覺外觀。
本步驟S4中,所述的關鍵點優化技術主要采用凸優化方法,具體方法包括:
首先構造所述人臉關鍵點信息組合向量A={xc1,xc2,xc3…xcn},其中xci(i=1,2,3…n)表示所述的關鍵點信息的第i種信息子向量。
然后通過凸優化目標函數得到最優解使得所對齊的人臉關鍵點參數誤差最小。
其中,優化目標函數的約束條件為:θi≥0,∑θi=1;
表示所對齊的關鍵點和目標關鍵點之間的偏差,x為所述的關鍵點信息任意一種信息子向量,minθ表示關于求θ極小值,符號“||||”表示關于求范數。
最后根據最優解對粗配準的通用三維人臉模型進行人臉關鍵點精確對齊。
本步驟S4中,所述的紋理細化技術,具體包括:
首先計算人臉紋理的有效區域,在紋理圖像上,如果一個像素所對應的頂點在圖像上的投影坐標位于人臉輪廓之內,并且該頂點在投影角度下是可見的,則相應的像素就位于人臉紋理的有效區域內;
計算每個像素處的位置確定度p,將位置確定度作為代價函數中該像素處的權重,位置確定度定義為投影方向與頂點的法向量之間夾角的余弦;
為重建的三維人臉模型加入兩個光照,分別位于三維人臉模型的左前方和右前方各45度,光照的位置固定且強度可變;
以形狀無關紋理SIFT為擬合的目標圖像,以人臉形變模型的紋理分量合成人臉紋理S1;將代價函數Eξ設置為合成的紋理圖像與目標圖像之間的偏差,代價函數在紋理的有效區域內進行計算;
通過目標函數Eξ>0利用梯度下降法將求得代價函數最小值,然后得到合成的紋理圖像S;
選取一個紋理融合的優化系數I,將合成的人臉紋理圖像S與形狀無關紋理SIFT進行融合,取出形狀無關紋理的中心區域補充到合成的紋理圖像上,以補充人臉的細節,得到最終融合后的紋理R,其中R=I·SIFT+(1-I)·S。
通過關鍵點凸優化技術及紋理細化技術后,使得最終合成的三維人臉視覺外觀更具真實感和個性化。
如圖3所示,本發明還提供了一種基于視頻流與人臉多屬性匹配的三維人臉建模打印裝置,包括:
輸入單元,用于獲取實時視頻流中的原始人臉圖像,同時對人臉圖像進行預處理操作,輸出歸一化的標準人臉圖像;
特征點標記單元,用于在所述原始人像上標記特征點并記錄其坐標信息;
通用三維人臉模型庫單元,所述通用三維人臉模型庫單元屬于離線包,可以下載存儲在本地硬盤中,無需重復建立模型庫,以后的使用都無需再次建庫;
人臉多屬性分類單元,用于通過對多個人臉屬性任務進行聯合訓練,用一個深度網絡同時完成多個人臉屬性目標分類任務,包括進行人臉檢測、人臉關鍵點信息提取以及人臉多屬性分析預測;
人臉關鍵點優化單元,用于提取原始人像上標記特征點及坐標信息,采用凸優化方法進行人臉關鍵點優化和人臉精準對齊;
人臉紋理細化單元,對初步獲取的通用三維人臉模型進行紋理細化,使最終的建模結果更真實可靠、細膩其個性化;
打印輸出單元,用于輸出顯示并打印建模結果。
本發明實施方法中的步驟可以根據實際需要進行順序調整、合并和刪減。
以上所述,只是本發明的較佳實施例而已,本發明并不局限于上述實施方式,只要其以相同的手段達到本發明的技術效果,都應屬于本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!