項目推薦的方法及裝置與流程
本發明屬于信息技術領域,尤其涉及一種項目推薦的方法及裝置。
背景技術:
針對互聯網的個性化推薦技術通過挖掘用戶的歷史瀏覽信息、購買信息、消費頻率以及對商品的評價來建立用戶的興趣模型,然后根據該興趣模型向用戶推薦廣告、商品等項目信息。然而,對于首次加入推薦系統的用戶和項目,由于沒有歷史記錄,現有的個性化推薦計數無法向該用戶進行推薦,也無法將最新加入的該項目推薦給用戶。隨著用戶和項目的規模快速增加,沒有用戶評分的項目也越來越多,導致矩陣數值稀缺,進而嚴重影響了推薦結果的精準性。另一方面,現有的移動終端使得用戶可以在任何時間、地點發布社交網絡信息,用戶的興趣愛好也會隨著時間和環境等因素的改變而發生變化,現有的個性化推薦系統無法及時捕捉用戶的動態信息,進而無法實現精準的推送,推送效果不佳。
綜上所述,現有的個性化推薦技術存在數據稀疏、冷啟動以及信息過載的問題。
技術實現要素:
鑒于此,本發明實施例提供了一種項目推薦的方法及裝置,以解決現有的個性化推薦技術存在數據稀疏、冷啟動以及信息過載的問題。
第一方面,提供了一種項目推薦的方法,所述方法包括:
獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群;
計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度;
根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度;
選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集;
獲取所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。
進一步地,所述計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度包括:
對于所述候選用戶群中的每一個候選用戶,根據所述待推薦用戶與所述候選用戶之間的相互評論數目計算所述待推薦用戶與所述候選用戶之間的交互行為相似度;
根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
進一步地,所述根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度包括:
獲取所述待推薦用戶的項目評分矩陣和所述候選用戶的項目評分矩陣;
根據預設的時間加權函數分別對所述待推薦用戶和所述候選用戶的項目評分矩陣進行一次修正;
根據預設的距離加權函數對一次修正后的項目評分矩陣進行二次修正;
根據二次修正后的所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
進一步地,所述時間加權函數為基于時間的遺忘函數,所述距離加權函數為基于距離的遺忘函數。
進一步地,所述獲取所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶包括:
獲取所述近鄰集中每一個候選用戶v對已消費項目i的項目評分rv,i、所述候選用戶v的項目評分的均值所述待推薦用戶u的項目評分的均值以及所述待推薦用戶u與所述近鄰集中每一個候選用戶v之間的復合相似度sim'(u,v);
按照預設公式預測所述待推薦用戶對所述項目i的項目評分Pu,i;
選取所述項目評分Pu,i最高的M個項目推薦給所述待推薦用戶。。
第二方面,提供了一種項目推薦的裝置,所述裝置包括:
用戶群獲取模塊,用于獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群;
第一相似度計算模塊,用于計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度;
第二相似度計算模塊,用于根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度;
鄰近集獲取模塊,用于選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集;
預測推薦模塊,用于獲取所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。
進一步地,所述第一相似度計算模塊包括:
交互行為相似度計算單元,用于對于所述候選用戶群中的每一個候選用戶,根據所述待推薦用戶與所述候選用戶之間的相互評論數目計算所述待推薦用戶與所述候選用戶之間的交互行為相似度;
項目評分相似度計算單元,用于根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
進一步地,所述項目評分相似度計算單元包括:
獲取子單元,用于獲取所述待推薦用戶的項目評分矩陣和所述候選用戶的項目評分矩陣;
第一修正子單元,用于根據預設的時間加權函數分別對所述待推薦用戶和所述候選用戶的項目評分矩陣進行一次修正;
第二修正子單元,用于根據預設的距離加權函數對一次修正后的項目評分矩陣進行二次修正;
計算子單元,用于根據二次修正后的所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
進一步地,所述時間加權函數為基于時間的遺忘函數,所述距離加權函數為基于距離的遺忘函數。
進一步地,所述預測推薦模塊包括:
獲取單元,用于獲取所述近鄰集中每一個候選用戶v對已消費項目i的項目評分rv,i、所述候選用戶v的項目評分的均值所述待推薦用戶u的項目評分的均值以及所述待推薦用戶u與所述近鄰集中每一個候選用戶v之間的復合相似度sim'(u,v);
預測單元,用于按照預設公式預測所述待推薦用戶對所述項目i的項目評分Pu,i;
推薦單元,用于選取所述項目評分Pu,i最高的M個項目推薦給所述待推薦用戶。
與現有技術相比,本發明實施例在進行推薦時,獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群;然后計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度;根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度;選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集;最后根據所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。從而將待推薦用戶在社交網絡的交互信息和移動軌跡信息融合到用戶相似度的計算過程中,將用戶的未消費項目也納入到推薦范圍內,有效地解決了現有的個性化推薦技術存在數據稀疏、冷啟動的問題。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他附圖。
圖1是本發明實施例提供的項目推薦的方法的實現流程圖;
圖2是本發明實施例提供的根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣計算兩者之間的項目評分相似度的具體實現流程圖;
圖3是本發明實施例提供的項目推薦的方法中步驟S105的具體實現流程圖;
圖4是本發明實施例提供的項目推薦的裝置的組成結構圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
本發明實施例在進行推薦時,獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群;然后計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度;根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度;選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集;最后根據所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。從而將待推薦用戶在社交網絡的交互信息和移動軌跡信息融合到用戶相似度的計算過程中,將用戶的未消費項目也納入到推薦范圍內,有效地解決了現有的個性化推薦技術存在數據稀疏、冷啟動的問題。本發明實施例還提供了相應的裝置,以下分別進行詳細的說明。
圖1示出了本發明實施例提供的項目推薦的方法的實現流程。
在本發明實施例中,所述項目推薦的方法應用于計算機、服務器等設備。
參閱圖1,所述項目推薦的方法包括:
在步驟S101中,獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群。
在進行推薦時,本發明實施例首先獲取待推薦用戶的當前位置,然后根據所述位置篩選出預設距離范圍內的項目信息。所述項目包括但不限于商品、服務等,為了便于說明,假設所述預設距離范圍內包括K個項目。然后以消費過這些項目的用戶組成所述待推薦用戶對應的候選用戶群,為了便于敘述,每一個候選用戶分別表示為Ui,i=1、…、I,所述用戶群供包括I個用戶。
在步驟S102中,計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度。
在日常生活中,交互越頻繁的兩個人,其關系越親密,生活習慣越接近,比如經常一起做某件事,或者經常做同一件事。在本發明實施例中,所述交互行為相似度反應了所述待推薦用戶與候選用戶之間在行為上的相似程度。所述項目評分相似度則反應了所述待推薦用戶與候選用戶之間在同一項目上的評分相似程度,所述評分相似程度是指所述待推薦用戶與所述候選用戶在對同一項目的態度上的相似程度,比如喜歡、厭惡等。
作為本發明的一個優選示例,對于所述候選用戶群中的每一個候選用戶Ui,可以根據所述待推薦用戶與所述候選用戶之間的相互評論數目計算所述待推薦用戶與所述候選用戶之間的交互行為相似度,以及,根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
可選地,當根據所述待推薦用戶與所述候選用戶之間的相互評論數目計算所述待推薦用戶與所述候選用戶之間的交互行為相似度時,其計算公式可以為:
其中,所述u表示待推薦用戶,所述Ui表示候選用戶群中的第i個候選用戶,所述sim(u,Ui)表示待推薦用戶u與候選用戶Ui之間的交互行為相似度,所述表示待推薦用戶u與候選用戶Ui之間的相互評論數目,所述maxH表示以所述待推薦用戶u與候選用戶Ui組成的集群中兩兩之間的相互評論數目的最大值。
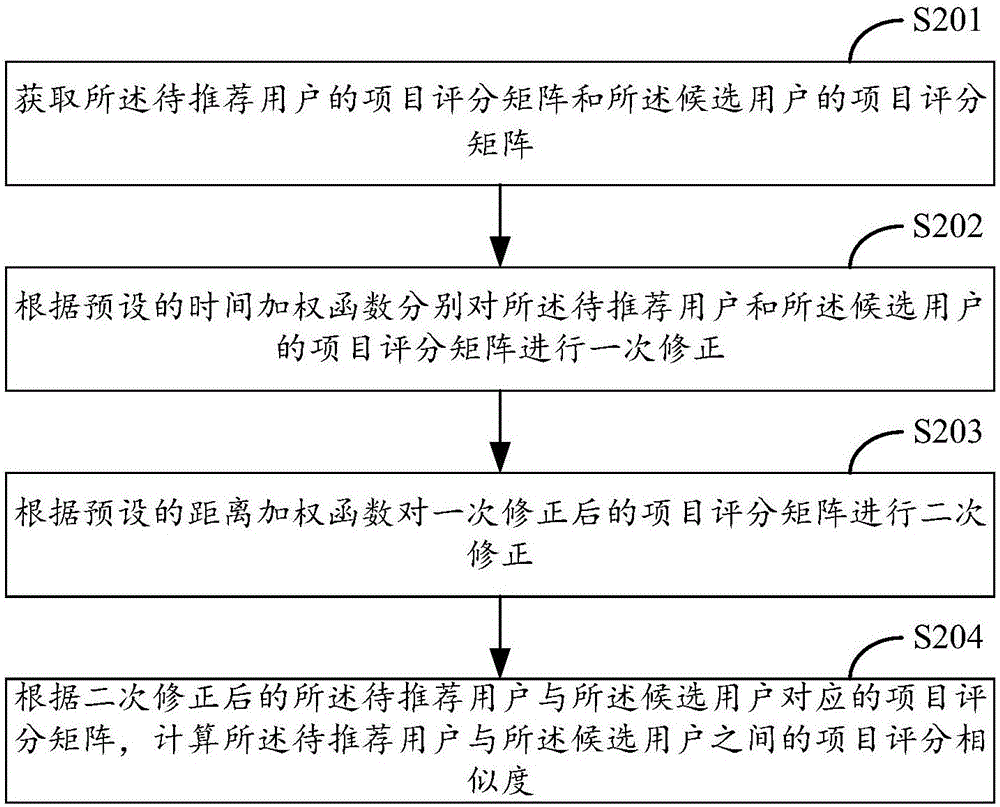
可選地,圖2示出了本發明實施例提供的根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣計算兩者之間的項目評分相似度的具體實現流程。參閱圖2,所述項目評分相似度的計算過程包括:
在步驟S201中,獲取所述待推薦用戶的項目評分矩陣和所述候選用戶的項目評分矩陣。
在這里,所述待推薦用戶u的項目評分矩陣表示為Ru,其中,Ru內包括所述待推薦用戶u對所述K個項目的評分,即ru,k,k=1、…、K。所述候選用戶Ui的項目評分矩陣表示為其中,內包括所述候選用戶Ui對所述K個項目的評分
在步驟S202中,根據預設的時間加權函數分別對所述待推薦用戶和所述候選用戶的項目評分矩陣進行一次修正。
由于隨著時間的推移,待推薦用戶和候選用戶對項目都會產生遺忘。本發明實施例中的所述時間加權函數可以為基于時間的遺忘函數。將所述待推薦用戶和所述候選用戶的項目評分矩陣中的每一個項目評分分別與所述時間加權函數進行相乘,從而完成對項目評分矩陣的修正,其中,離當前時間越近的項目評分分配的影響權重越大,離當前時間越遠的項目評分則分配的影響權重越小。通過所述基于時間的遺忘函數來修正修所述項目評分矩陣,可以有效地削弱很久以前的項目評分的影響。
示例性地,對于待推薦用戶u,所述時間加權函數可以為:
其中,所述a、b表示常數,所述tu,k表示待推薦用戶u對第k個項目的評分距離當前時間的間隔,k=1、…、K。對于待推薦用戶u的項目評分矩陣Ru中的每一個項目評分ru,k,k=1、…、K,均有r'u,k=ru,k*h(u,t),所述r'u,k表示經時間加權函數修正后的項目評分,所有的r'u,k共同組成了經一次修正后的項目評分矩陣R'u。
對于每一個候選用戶Ui,i=1、…、I,所述時間加權函數可以為:
所述a、b表示常數,所述表示候選用戶Ui對第k個項目的評分距離當前時間的間隔,k=1、…、K。對于候選用戶Ui的項目評分矩陣中的每一個項目評分均有所述表示經時間加權函數的修正后的項目評分,所有的共同組成了經一次修正后的項目評分矩陣
在步驟S203中,根據預設的距離加權函數對一次修正后的項目評分矩陣進行二次修正。
參考時間加權函數,考慮到在同等條件下,商戶的位置越遠,其出售的項目對用戶的吸引力越小,商戶的位置越近,其出售的項目對用戶的吸引力越大。因此,所述距離加權函數可以為基于距離的遺忘函數,將經一次修正后的項目評分矩陣中的每一個項目評分分別與所述距離加權函數進行相乘,以對不同距離的項目加上距離權重來進行修正,可以有效地削弱距離較遠的項目評分的影響。
示例性地,對于待推薦用戶u,所述距離加權函數可以為:
其中,所述a、b表示常數,所述du,k表示待推薦用戶u當前位置與第k個項目之間的距離,k=1、…、K。對于經過一次修正后的待推薦用戶u的項目評分矩陣R'u中的每一個項目評分r'u,k,k=1、…、K,均有r”u,k=r'u,k*w(u,d),所述r”u,k表示經距離加權函數修正后的項目評分,所有的r”u,k共同組成了經二次修正后的項目評分矩陣R”u。
對于每一個候選用戶Ui,i=1、…、I,所述距離加權函數可以為:
所述a、b表示常數,所述表示候選用戶Ui當前位置與第k個項目之間的距離,k=1、…、K。對于經過一次修正后的候選用戶Ui的項目評分矩陣中的每一個項目評分均有所述表示經過距離加權函數的修正后的項目評分,所有的共同組成了經二次修正后的項目評分矩陣
在這里,由于用戶的偏好隨時間的推移不斷改變,且位置變化后用戶也會受到周邊環境的影響,本發明實施例通過融入時間權重和距離權重,基于時間加權和距離加權來優化用戶的項目評分矩陣,使得所述項目評分矩陣更貼近用戶當前的偏好情況,也避免了信息過載的問題。需要說明的是,上述時間加權函數和距離加權函數中的常數a、b的值可根據具體情況確定,此處不做限定。
在步驟S204中,根據二次修正后的所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
在這里,所述項目評分相似度的計算公式為:
其中,所述simr(u,Ui)表示所述待推薦用戶u與所述候選用戶Ui之間的項目評分相似度,所述表示待推薦用戶u的項目評分的均值;所述表示第i個候選用戶Ui的項目評分的均值。
在步驟S103中,根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度。
在通過步驟S102得到所述待推薦用戶u與每一個候選用戶Ui之間的交互行為相似度sim(u,Ui)和項目評分相似度simr(u,Ui)之后,采用以下公式計算所述待推薦用戶u與每一個候選用戶Ui的復合相似度sim'(u,Ui),供得到I個復合相似度:
sim'(u,Ui)=λsim(u,Ui)+(1-λ)simr(u,Ui)
其中,所述λ表示調節參數,取值范圍為[0,1]。
在這里,所述復合相似度sim'(u,Ui)是由交互行為相似度和項目評分性相似度組成的,且本發明實施例預先對所述交互行為相似度和項目評分相似度進行了時間和距離上的修正,從而使得所述復合相似度準確地反映了當前狀態下待推薦用戶與候選用戶之間的相似性。
在步驟S104中,選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集。
在這里,本發明實施例使用TOP-N分析方法對所述I個復合相似度進行排序,然后從中選取值最大的前N個復合相似度對應的候選用戶作為所述待推薦用戶的近鄰集。為了便于敘述,所述近鄰集記為V,其包括復合相似度最大的前N個復合相似度對應的候選用戶vn,n=1、…、N。
在步驟S105中,獲取所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。
可選地,圖3示出了本發明實施例提供的項目推薦的方法中步驟S105的具體實現流程。參閱圖3,所述步驟S105包括:
在步驟S301中,獲取所述近鄰集中每一個候選用戶v對第k個項目的項目評分rv,k、所述候選用戶v的項目評分的均值所述待推薦用戶u的項目評分的均值以及所述待推薦用戶u與所述近鄰集中每一個候選用戶v之間的復合相似度sim'(u,v)。
在步驟S302中,按照預設公式預測所述待推薦用戶對所述第k個項目的項目評分Pu,k。
在這里,所述預設公式為:
其中,所述Pu,k表示待推薦用戶對第k個項目的評分。
在步驟S303中,選取所述項目評分Pu,k最高的M個項目推薦給所述待推薦用戶。
同樣地,本發明實施例使用TOP-N分析方法對所述所述項目評分Pu,k進行排序,從中選取值最大的前M個項目評分Pu,k對應的項目推薦給所述待推薦用戶,推薦的內容包括商戶及其商品、服務等。
在本發明實施例中,所述近鄰集是基于復合相似度最大的前N個值對應的候選用戶組成的,且本發明實施例中的復合相似度是基于時間和距離修正后的交互行為相似度和項目評分性相似度計算得到的,其提高了相似性的準確度,有效地反映了當前狀態下待推薦用戶與候選用戶之間的相似性,從而使得所述近鄰集更貼近待推薦用戶。基于所述近鄰集所關注的項目來估算所述待推薦用戶對項目的評分,不僅考慮到了首次加入的項目,也實現了對首次加入的用戶的推薦,將用戶的未消費項目也納入到推薦范圍內,有效地解決了現有的個性化推薦技術存在數據稀疏、冷啟動的問題,提高了推薦的準確度。
應理解,在上述實施例中,各步驟的序號的大小并不意味著執行順序的先后,各步驟的執行順序應以其功能和內在邏輯確定,而不應對本發明實施例的實施過程構成任何限定。
圖4示出了本發明實施例提供的項目推薦的裝置的組成結構,為了便于說明,僅示出了與本發明實施例相關的部分。
在本發明實施例中,所述裝置用于實現上述圖1至圖3任一實施例中所述的項目推薦的方法,可以是內置與計算機、服務器內的軟件單元、硬件單元或者軟硬件結合的單元。
參閱圖4,所述裝置包括:
用戶群獲取模塊41,用于獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群;
第一相似度計算模塊42,用于計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度;
第二相似度計算模塊43,用于根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度;
鄰近集獲取模塊44,用于選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集;
預測推薦模塊45,用于獲取所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。
本發明實施例在進行推薦時,首先通過所述用戶群獲取模塊41獲取待推薦用戶的當前位置,然后根據所述位置篩選出預設距離范圍內的項目信息,所述項目包括但不限于商品、服務等,以消費過這些項目的用戶組成所述待推薦用戶對應的候選用戶群。在這里,為了便于說明,假設所述預設距離范圍內包括K個項目,所述用戶群供包括I個用戶,每一個候選用戶分別表示為Ui,i=1、…、I。
所述交互行為相似度反應了所述待推薦用戶與候選用戶之間在行為上的相似程度。所述項目評分相似度則反應了所述待推薦用戶與候選用戶之間在同一項目上的評分相似程度,所述評分相似程度是指所述待推薦用戶與所述候選用戶在對同一項目的態度上的相似程度,比如喜歡、厭惡等。
在這里,所述第一相似度計算模塊42包括:
交互行為相似度計算單元421,用于對于所述候選用戶群中的每一個候選用戶,根據所述待推薦用戶與所述候選用戶之間的相互評論數目計算所述待推薦用戶與所述候選用戶之間的交互行為相似度。
其中,所述交互行為相似度計算單元421根據所述待推薦用戶與所述候選用戶之間的相互評論數目計算所述待推薦用戶與所述候選用戶之間的交互行為相似度的計算公式可以為:
在上式中,所述u表示待推薦用戶,所述Ui表示候選用戶群中的第i個候選用戶,所述sim(u,Ui)表示待推薦用戶u與候選用戶Ui之間的交互行為相似度,所述表示待推薦用戶u與候選用戶Ui之間的相互評論數目,所述maxH表示以所述待推薦用戶u與候選用戶Ui組成的集群中兩兩之間的相互評論數目的最大值。
所述第一相似度計算模塊42還包括:
項目評分相似度計算單元422,用于根據所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
由于用戶的興趣愛好狀態會隨著時間以及環境的變化發生改變,因此,本發明實施例在根據項目評分矩陣計算待推薦用戶與候選用戶之間的項目評分相似度之前,先對所述項目評分矩陣進行基于時間和距離的修正,以使得修正之后的項目評分矩陣更貼近用戶的當前狀態。所述項目評分相似度計算單元422具體包括:
獲取子單元4221,用于獲取所述待推薦用戶的項目評分矩陣和所述候選用戶的項目評分矩陣。
第一修正子單元4222,用于根據預設的時間加權函數分別對所述待推薦用戶和所述候選用戶的項目評分矩陣進行一次修正。
進一步地,所述時間加權函數可以為遺忘函數。其中,對于待推薦用戶u,所述時間加權函數可以為:
在上式中,所述a、b表示常數,所述tu,k表示待推薦用戶u對第k個項目的評分距離當前時間的間隔,k=1、…、K。對于待推薦用戶u的項目評分矩陣Ru中的每一個項目評分ru,k,k=1、…、K,均有r'u,k=ru,k*h(u,t),所述r'u,k表示經時間加權函數修正后的項目評分,所有的r'u,k共同組成了經一次修正后的項目評分矩陣R'u。
對于每一個候選用戶Ui,i=1、…、I,所述時間加權函數可以為:
所述a、b表示常數,所述表示候選用戶Ui對第k個項目的評分距離當前時間的間隔,k=1、…、K。對于候選用戶Ui的項目評分矩陣中的每一個項目評分均有所述表示經時間加權函數的修正后的項目評分,所有的共同組成了經一次修正后的項目評分矩陣
通過所述基于時間的遺忘函數來修正修所述項目評分矩陣,可以有效地削弱很久以前的項目評分的影響。
第二修正子單元4223,用于根據預設的距離加權函數對一次修正后的項目評分矩陣進行二次修正。
參照時間加權函數,所述距離加權函數也可以為遺忘函數。對于待推薦用戶u,所述距離加權函數可以為:
其中,所述a、b表示常數,所述du,k表示待推薦用戶u當前位置與第k個項目之間的距離,k=1、…、K。對于經過一次修正后的待推薦用戶u的項目評分矩陣R'u中的每一個項目評分r'u,k,k=1、…、K,均有r”u,k=r'u,k*w(u,d),所述r”u,k表示經距離加權函數修正后的項目評分,所有的r”u,k共同組成了經二次修正后的項目評分矩陣R”u。
對于每一個候選用戶Ui,i=1、…、I,所述距離加權函數可以為:
在上式中,所述a、b表示常數,所述表示候選用戶Ui當前位置與第k個項目之間的距離,k=1、…、K。對于經過一次修正后的候選用戶Ui的項目評分矩陣中的每一個項目評分均有所述表示經過距離加權函數的修正后的項目評分,所有的共同組成了經二次修正后的項目評分矩陣
在這里,由于用戶的偏好隨時間的推移不斷改變,且位置變化后用戶也會受到周邊環境的影響,本發明實施例通過融入時間權重和距離權重,基于時間加權和距離加權來優化用戶的項目評分矩陣,使得所述項目評分矩陣更貼近用戶當前的偏好情況。需要說明的是,上述時間加權函數和距離加權函數中的常數a、b的值可根據具體情況確定,此處不做限定。
計算子單元4224,用于根據二次修正后的所述待推薦用戶與所述候選用戶對應的項目評分矩陣,計算所述待推薦用戶與所述候選用戶之間的項目評分相似度。
在這里,所述項目評分相似度的計算公式為:
其中,所述simr(u,Ui)表示所述待推薦用戶u與所述候選用戶Ui之間的項目評分相似度,所述表示待推薦用戶u的項目評分的均值;所述表示第i個候選用戶Ui的項目評分的均值。
進一步地,所述預測推薦模塊還45包括:
獲取單元451,用于獲取所述近鄰集中每一個候選用戶v對第k個項目的項目評分rv,k、所述候選用戶v的項目評分的均值所述待推薦用戶u的項目評分的均值以及所述待推薦用戶u與所述近鄰集中每一個候選用戶v之間的復合相似度sim'(u,v);
預測單元452,用于按照預設公式預測所述待推薦用戶對所述第k個項目的項目評分Pu,k;
推薦單元453,用于選取所述項目評分Pu,k最高的M個項目推薦給所述待推薦用戶。
在這里,所述預設公式為:
其中,所述Pu,k表示待推薦用戶對第k個項目的評分。
在通過上述預設公式得到所述待推薦用戶對所有項目的項目評分Pu,k之后,本發明實施例通過所述推薦單元453使用TOP-N分析方法從所述項目評分Pu,k中選取值最大的前M個項目評分Pu,k對應的項目推薦給所述待推薦用戶,推薦的內容包括商戶及其商品、服務等。
需要說明的是,本發明實施例中的裝置可以用于實現上述方法實施例中的全部技術方案,其各個功能模塊的功能可以根據上述方法實施例中的方法具體實現,其具體實現過程可參照上述實例中的相關描述,此處不再贅述。
綜上所述,本發明實施例在進行推薦時,獲取待推薦用戶當前位置的預設距離范圍內的項目信息,根據所述項目信息獲取候選用戶群;然后計算所述待推薦用戶與所述候選用戶群中每一個候選用戶的交互行為相似度和項目評分相似度;根據所述交互行為相似度和項目評分相似度計算所述待推薦用戶與每一個候選用戶之間的復合相似度;選取復合相似度最大的N個候選用戶組成所述待推薦用戶的近鄰集;最后根據所述近鄰集中每一個候選用戶所關注的項目,預測所述待推薦用戶對所述項目的評分,并將評分最高的M個項目推薦給所述待推薦用戶。從而將待推薦用戶在社交網絡的交互信息和移動軌跡信息融合到用戶相似度的計算過程中,將用戶的未消費項目也納入到推薦范圍內,有效地解決了現有的個性化推薦技術存在數據稀疏、冷啟動的問題。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬件、或者計算機軟件和電子硬件的結合來實現。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的范圍。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的方法及裝置,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述模塊、單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元、模塊可以集成在一個處理單元中,也可以是各個單元、模塊單獨物理存在,也可以兩個或兩個以上單元、模塊集成在一個單元中。
所述功能如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光盤等各種可以存儲程序代碼的介質。
以上所述,僅為本發明的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本發明揭露的技術范圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應所述以權利要求的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!