基于模糊分類技術的邊坡可靠性參數獲取方法及裝置與流程
本發明涉及數據處理領域,具體而言,涉及一種基于模糊分類技術的邊坡可靠性參數獲取方法及裝置。
背景技術:
邊坡的穩定性問題是工農業生產和地質災害研究中常見的問題。邊坡穩定性的研究經歷了兩次飛躍,即從定性判斷到定量分析的飛躍,從確定性理論到不確定性理論的飛躍。
數學上,對不確定性問題最終都是轉換為若干確定性問題進行處理,總的解決模式是:以確定性分析方法為內核,外部嵌套可靠性分析方法。目前邊坡可靠性研究中,所采用的確定性分析方法內核以傳統的極限平衡法占據主導地位,近年來數值方法有上升的勢頭。前者以bishop法、morgenstern-price法、spencer法等為代表,后者以有限元法為代表。但無論以哪一種方法為內核,無法回避的一個重要的環節,就是要對“邊坡失穩”(或稱之為“邊坡破壞”)這一狀態進行判別,并且這一狀態判別會透過外部嵌套的可靠性分析方法,顯著影響最終的邊坡可靠性評價結果。
當前,巖土工程界對于“邊坡失穩”(或稱之為“邊坡破壞”)這一狀態的界定,是根據常規的巖土工程認識,即由穩定系數的值來判斷邊坡是否失穩:當穩定系數>1,邊坡處于穩定狀態;當穩定系數=1,邊坡處于極限平衡狀態;穩定系數<1,邊坡失穩。但上述判別方法也存在明顯的弊端,當穩定系數在1附近上下徘徊時,邊坡的穩定程度并無本質不同,但狀態劃分結果會完全相反。這種簡單、粗暴的“一刀切”方式顯然不夠合理,并且已經影響到邊坡可靠性評價結果的準確度。
技術實現要素:
有鑒于此,本發明實施例的目的在于提供一種基于模糊分類技術的邊坡可靠性參數獲取方法及裝置,以解決上述問題。
為了實現上述目的,本發明實施例采用的技術方案如下:
第一方面,本發明實施例提供了一種基于模糊分類技術的邊坡可靠性參數獲取方法,所述方法包括:根據m個不確定性參數各自對應的均值與標準差,通過正交設計法,生成k個訓練樣本向量,每個所述訓練樣本向量由所述m個不確定性參數各自對應的試驗數據構成,其中,m與k為非零自然數,k的最大取值與m呈指數關系;根據所述k個訓練樣本向量及一個或多個確定性參數,通過邊坡穩定性分析方法,獲取所述k個訓練樣本向量各自對應的邊坡穩定系數;以所述k個訓練樣本向量為自變量,以其各自對應的邊坡穩定系數為因變量,構成映射關系,通過支持向量機算法,獲取所述映射關系表達式;根據隨機生成的n個服從于聯合概率分布的待測樣本向量、所述映射關系表達式以及預設的失穩狀態模糊判別函數,獲取邊坡可靠性參數,所述邊坡可靠性參數包括n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差、邊坡失效概率以及可靠度指標,其中,每個所述待測樣本向量由所述m個不確定性參數各自對應的隨機數據構成。
第二方面,本發明實施例提供了一種基于模糊分類技術的邊坡可靠性參數獲取裝置,所述裝置包括:訓練樣本生成模塊,用于根據m個不確定性參數各自對應的均值與標準差,通過正交設計法,生成k個訓練樣本向量,每個所述訓練樣本向量由所述m個不確定性參數各自對應的試驗數據構成,其中m與k為非零自然數,k的最大取值與m呈指數關系;穩定系數獲取模塊,用于根據所述k個訓練樣本向量及一個或多個確定性參數,通過邊坡穩定性分析方法,獲取所述k個訓練樣本向量各自對應的邊坡穩定系數;表達式獲取模塊,用于以所述k個訓練樣本向量為自變量,以其各自對應的邊坡穩定系數為因變量,構成映射關系,通過支持向量機算法,獲取所述映射關系表達式;可靠性參數獲取模塊,用于根據隨機生成的n個服從于聯合概率分布的待測樣本向量、所述映射關系表達式以及預設的失穩狀態模糊判別函數,獲取邊坡可靠性參數,所述邊坡可靠性參數包括n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差、邊坡失效概率以及可靠度指標,其中,每個所述待測樣本向量由所述m個不確定性參數各自對應的隨機數據構成。
與現有技術相比,本發明實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法及裝置,根據m個不確定性參數各自對應的均值與標準差,通過正交技術獲取少量訓練樣本向量,再根據這些訓練樣本向量及一個或多個確定性參數的值,通過相關邊坡穩定性分析方法獲取對應的邊坡穩定系數,然后根據隨機生成的n個服從于聯合概率分布的待測樣本向量、所述映射關系表達式以及預設的失穩狀態模糊判別函數,獲取邊坡可靠性參數。所述方法通過失穩狀態模糊判別函數對邊坡的穩定性進行模糊量化,進而提高了邊坡可靠性參數的準確度。
本發明的其他特征和優點將在隨后的說明書闡述,并且,部分地從說明書中變得顯而易見,或者通過實施本發明實施例了解。本發明的目的和其他優點可通過在所寫的說明書、權利要求書、以及附圖中所特別指出的結構來實現和獲得。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,應當理解,以下附圖僅示出了本發明的某些實施例,因此不應被看作是對范圍的限定,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他相關的附圖。
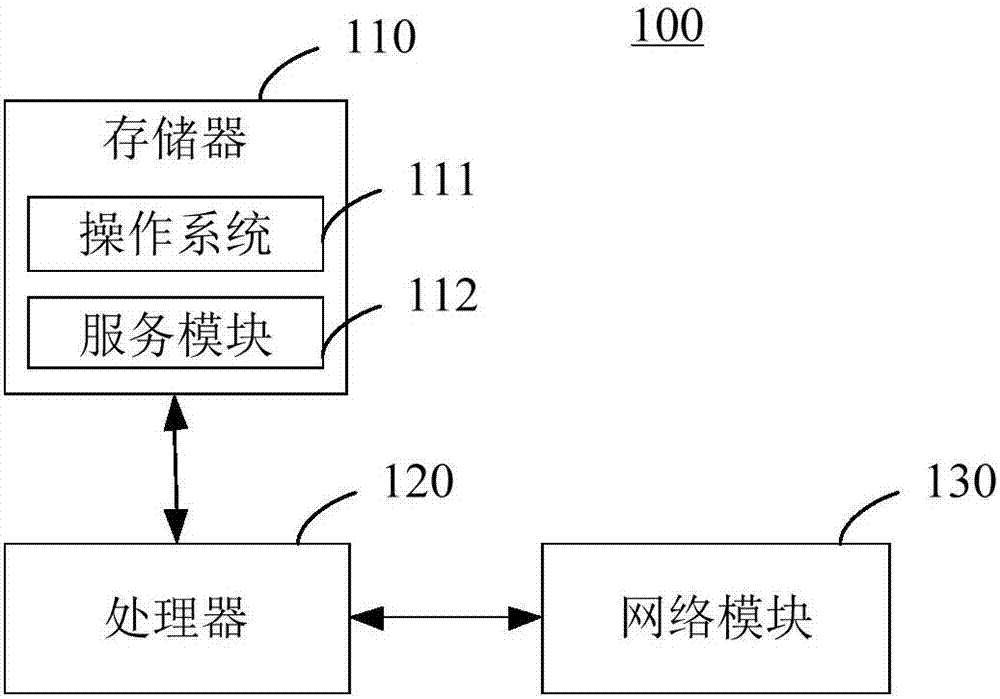
圖1是本發明實施例提供的服務器的結構示意圖。
圖2是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法的流程圖。
圖3是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法中步驟s310的一種詳細流程圖。
圖4是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法中步驟s330的一種詳細流程圖。
圖5是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法中步驟s340的一種詳細流程圖。
圖6是本發明第一實施例提供的一種基于模糊分類技術的失穩狀態模糊判別函數的示意圖。
圖7是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法中某尾礦壩壩坡的概化剖面圖。
圖8(a)是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法中在不同蒙特卡洛模擬次數下的某尾礦壩壩坡失效概率的效果示意圖。
圖8(b)是本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法中在不同蒙特卡洛模擬次數下的某尾礦壩壩坡可靠度指標的效果示意圖。
圖9是本發明第二實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取裝置的結構框圖。
圖10是本發明第二實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取裝置中訓練樣本生成模塊410的一種詳細結構框圖。
圖11是本發明第二實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取裝置中表達式獲取模塊430的一種詳細結構框圖。
圖12是本發明第二實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取裝置中可靠性參數獲取模塊440的一種詳細結構框圖。
具體實施方式
下面將結合本發明實施例中附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅是本發明一部分實施例,而不是全部的實施例。通常在此處附圖中描述和出示的本發明實施例的組件可以以各種不同的配置來布置和設計。因此,以下對在附圖中提供的本發明的實施例的詳細描述并非旨在限制要求保護的本發明的范圍,而是僅僅表示本發明的選定實施例。基于本發明的實施例,本領域技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
應注意到:相似的標號和字母在下面的附圖中表示類似項,因此,一旦某一項在一個附圖中被定義,則在隨后的附圖中不需要對其進行進一步定義和解釋。同時,在本發明的描述中,術語“第一”、“第二”等僅用于區分描述,而不能理解為指示或暗示相對重要性。
本發明實施例提供的基于支持模糊分類技術的邊坡可靠性參數獲取方法可以應用于服務器中。圖1示出了服務器100的結構示意圖,請參閱圖1,所述服務器100包括存儲器110、處理器120以及網絡模塊130。
存儲器110可用于存儲軟件程序以及模塊,如本發明實施例中的基于支持向量機的邊坡可靠性參數獲取方法及裝置對應的程序指令/模塊,處理器120通過運行存儲在存儲器110內的軟件程序以及模塊,從而執行各種功能應用以及數據處理,即實現本發明實施例中的基于支持向量機的邊坡可靠性參數獲取方法。存儲器110可包括高速隨機存儲器,還可包括非易失性存儲器,如一個或者多個磁性存儲裝置、閃存、或者其他非易失性固態存儲器。進一步地,上述存儲器110內的軟件程序以及模塊還可包括:操作系統111以及服務模塊112。其中操作系統111,例如可為linux、unix、windows,其可包括各種用于管理系統任務(例如內存管理、存儲設備控制、電源管理等)的軟件組件和/或驅動,并可與各種硬件或軟件組件相互通訊,從而提供其他軟件組件的運行環境。服務模塊112運行在操作系統111的基礎上,并通過操作系統111的網絡服務監聽來自網絡的請求,根據請求完成相應的數據處理,并返回處理結果給客戶端。也就是說,服務模塊112用于向客戶端提供網絡服務。網絡模塊130用于接收以及發送網絡信號。上述網絡信號可包括無線信號或者有線信號。
可以理解,圖1所示的結構僅為示意,服務器100還可包括比圖1中所示更多或者更少的組件,或者具有與圖1所示不同的配置。圖1中所示的各組件可以采用硬件、軟件或其組合實現。另外,本發明實施例中的服務器還可以包括多個具體不同功能的服務器。
圖2示出了本發明第一實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法的流程圖,請參閱圖2,所述方法包括:
步驟s310,根據m個不確定性參數各自對應的均值與標準差,通過正交設計法,生成k個訓練樣本向量,每個所述訓練樣本向量由所述m個不確定性參數各自對應的試驗數據構成,其中,m與k為非零自然數,k的最大取值與m呈指數關系。
m與k為非零自然數,即m,k∈n+。其中,不確定性參數可以為巖土體的粘聚力、內摩擦角、容重等邊坡巖土體物理力學參數,可以理解的是,所述不確定性參數也可以是獲取邊坡可靠性參數時所需的其他參數,需根據具體的應用場景的不同進行相應的設置。
作為一種具體的實施方式,請參閱圖3,所述步驟s310可以包括:
步驟s311:根據m個不確定性參數的均值和標準差,通過正交設計法,至少生成一組第一訓練樣本向量,每個所述不確定性參數對應的均值為μi,標準差為σi,每個所述第一訓練樣本向量中的每個所述不確定性參數對應的試驗數據為μi-2σi、μi、μi+2σi,或者為μi-3σi、μi、μi+3σi,其中i=1,2,…,m,每一組所述第一訓練樣本向量的數量為nj,nj≤3m,j為組編號,j∈n+。
每個所述不確定性參數相當于一個隨機變量,其對應的均值與標準差是已知的,將所述不確定性參數對應的均值表示為μi,標準差表示為σi,其中i=1,2,…,m。
每個所述不確定性參數可以圍繞其對應的均值設置試驗數據的范圍,設每個所述不確定性參數對應的試驗數據的范圍包括μi-2σi、μi、μi+2σi,這種情況下,由于每個所述第一訓練樣本向量由所述m個不確定性參數各自對應的試驗數據構成,而每個所述不確定性參數對應的試驗數據可以是μi-2σi、μi、μi+2σi中的任意一種,因此總共可以生成3m個不同的第一訓練樣本向量。
類似的,還可以設每個所述不確定性參數對應的試驗數據的范圍包括μi-3σi、μi及μi+3σi。這種情況下,由于每個所述第一訓練樣本向量由所述m個不確定性參數各自對應的試驗數據構成,而每個所述不確定性參數對應的試驗數據可以是μi-3σi、μi及μi+3σi中的任意一種,因此總共可以生成3m個不同的第一訓練樣本向量。
正交設計法實際上就是從所述3m個不同的第一訓練樣本向量中選擇nj個具有代表性的第一訓練樣本向量用于后續獲取映射關系表達式,因此nj≤3m。所述正交設計法可以通過spss等現有成熟商業軟件、excel電子表格功能函數或自行編程實現,此處不再贅述。
生成的第一訓練樣本向量至少為一組,如j=1,可以為上述兩種情況的任意一種。如當j=2,可以將μi-2σi、μi、μi+2σi作為每個所述不確定性參數對應的試驗數據,生成一組第一訓練樣本向量,同時將μi-3σi、μi及μi+3σi作為每個所述不確定性參數對應的試驗數據,再生成一組第一訓練樣本向量。其中,后期生成的樣本組中如果含有與先期生成樣本組相重復的元素(即樣本向量),需刪除。
此外,可以理解的是,每個所述不確定性參數對應的試驗數據的范圍可以根據具體需求具體設置,其設置方式并不構成對本發明具體實施方式的限制。
步驟s312:合并所述第一訓練樣本向量為訓練樣本向量,所述訓練樣本向量的樣本數為k,
合并至少一組所述第一訓練樣本向量為訓練樣本向量。例如將步驟s312中當i=2時生成的兩組樣本合并,構造出k=n1+n2個樣本,為訓練樣本向量。由于正交設計表的非唯一性,在大多數情況下是生成的k=n1+n2個樣本,但并不一定包含m個因素全部取均值條件這一特殊樣本。由于均值樣本在統計學中的特殊意義,應予以特別關注。鑒于此,如若不含,應特別增補該樣本進入正交設計表。因此樣本數k滿足k=n1+n2+1或k=n1+n2。
進一步地,考慮到復雜邊坡問題的規模,以及后續映射關系表達式的回歸效果檢測不滿足精度要求的問題,需要生成更多的訓練樣本。當精度不滿足要求時,可以μi-2σi、μi、μi+2σi作為每個所述不確定性參數對應的試驗數據,添加一組第一訓練樣本向量,按后續步驟構成映射關系表達式,檢測回歸效果是否達標;若仍不達標,則再以μi-3σi、μi及μi+3σi作為每個所述不確定性參數對應的試驗數據,添加一組訓練樣本向量,按后續步驟再次構成映射關系表達式,再次檢測回歸效果是否達標。以此類推,直到滿足要求。因此,應根據實際需求,獲取一定組數的第一訓練樣本向量。其中,總樣本數k滿足
步驟s320,根據所述k個訓練樣本向量及一個或多個確定性參數的值,通過邊坡穩定性分析方法,獲取所述k個訓練樣本向量各自對應的邊坡穩定系數。
其中,確定性參數可以為巖土體的粘聚力、內摩擦角、容重等邊坡巖土體物理力學參數,可以為邊坡的長度、寬度等幾何參數,可以理解的是,所述確定性參數也可以是獲取邊坡可靠性參數時所需的其他參數,需根據具體的應用場景的不同進行相應的設置。
所述邊坡穩定性分析方法可以為極限平衡法、有限元法或有限差分法等。其中,極限平衡法可以包括瑞典條分(swedenslice)法、斯賓塞(spencer)法、畢肖普(bishop)法、摩根斯坦-普萊斯(morgenstern-price)法等。所述邊坡穩定性分析方法可以通過各種邊坡穩定性分析的商業軟件實現,如geostudio(包含極限平衡法和有限元法兩類方法可供選擇)、ansys(有限元法)、abaqus(有限元法)、adina(有限元法)、flac/flac3d(有限差分法)等。通過上述任意一種方法都可以得到相應的邊坡穩定系數,但是由于各種方法的理論構架不同,因此根據不同的方法獲取的邊坡穩定系數在數值存在一定的差異,針對不同的應用場景可以根據需求采用更恰當的方法。
步驟s330,以所述k個訓練樣本向量為自變量,以其各自對應的邊坡穩定系數為因變量,構成映射關系,通過支持向量機算法,獲取所述映射關系表達式。
作為一種具體的實施方式,請參閱圖4,所述步驟s330可以包括:
步驟s331,根據所述k個訓練樣本向量及其各自對應的邊坡穩定系數,以及預設規則,獲取最優偏移量以及所述k個訓練樣本向量各自對應的最優拉格朗日對偶。
優選的,在所述步驟s331之前,所述方法還可以包括:
對所述k個訓練樣本向量中的試驗數據進行歸一化處理。
由于如巖土體的粘聚力、內摩擦角、容重等各個不確定性參數的量綱不同、絕對值大小差異顯著,因此對所述k個訓練樣本向量中的試驗數據進行歸一化處理后再執行后續步驟,可以有效地提高后續獲取的各邊坡穩定系數的精度,其中,所述k個訓練樣本向量中的試驗數據經歸一化處理后可以位于[-1,1]區間。
步驟s332,根據所述最優偏移量、所述k個訓練樣本向量及其各自對應的最優拉格朗日對偶,獲取映射關系表達式。
下面對步驟s331及步驟s332進行詳細說明。
根據向量機算法,設有k組試驗數據,且每組有m個變量,構成數據對,即[(xi,yi)|i=i=1,2,…,k],其映射關系記為:
xi→yixi=[xi1,xi2,…xim]ti=1,2,…,k
xi∈rmyi∈r(1)
式中:向量xi代表第i組試驗的數據(一般為經過歸一化作預處理后的試驗數據),由m個變量組成,分別代表影響邊坡穩定性的m個隨機因素(例如巖土體的粘聚力、內摩擦角、容重等)。yi表示第i組試驗數據對應的邊坡穩定系數,也就是向量機的輸出。數學符號r表示實數空間,rm表示m維實數空間。
引入一個預測函數f(x),用以逼近所述訓練樣本向量與其各自對應的邊坡穩定系數之間的映射關系,該預測函數f(x)可以表示為:
式中,
w可通過在滿足式(4)的條件下使得式(3)最小的最優化問題來確定,其中式(3)與式(4)分別為:
式中,r(w,ξ,ξ*)為風險控制函數,ξ=[ξ1,ξ2,…,ξm]t和
進一步的,式(3)及式(4)所示的最優化問題可以通過引入拉格朗日乘子來轉化為求取在滿足式(6)的條件下使得式(5)最大的最優化問題,其中式(5)及式(6)分別為:
式中,αi和
k(x,y)=exp(-δ2||x-y||2)(7)
式中,δ為核函數參數。
將所述k個訓練樣本向量xi及其各自對應的邊坡穩定系數yi代入式(5)后,可以通過優化算法,如貫序最小二乘法,求解式(5)及式(6)構成的最優化問題,以獲取所述k個訓練樣本向量各自對應的最優拉格朗日對偶
式中,
將式(7)及式(8)代入式(2)后,式(2)可以表示為:
然后,構造一個函數η(b),用以表示所述k個訓練樣本向量各自對應的預測邊坡穩定系數與實際邊坡穩定系數誤差的平方和,所述函數η(b)可以表示為:
將所述k個訓練樣本向量xi及其各自對應的邊坡穩定系數yi代入式(10)后,可以通過優化算法,如最小二乘法,獲取使得式(10)的值最小的偏移量b,即為最優偏移量。
最后,將所述最優偏移量b、所述k個訓練樣本向量及其各自對應的最優拉格朗日對偶
以上是步驟s330的理論依據,在具體實踐中,為了達到更好的向量機回歸效果,還需要進行一些輔助操作。在此列出步驟s330的詳細分項步驟如下:
子步驟1,進行訓練樣本自變量的歸一化處理。考慮到巖土體的粘聚力、內摩擦角、容重等隨機變量的量綱不同、而且絕對值大小差異顯著,為提升向量機回歸效果,建議對步驟s310中的正交試驗數據,也就是訓練樣本自變量
式中μj和σj分別為第j個分量的均值和標準差。
子步驟2,求解拉格朗日對偶和偏移量。按照(1)式映射關系,構造向量機的輸入和輸出,然后進行向量機訓練。即按照貫序最小二乘法求解(5)~(6)式所示的最優化問題,得到拉格朗日對偶
子步驟3,獲取映射關系表達式。將(2)式函數關系式作為邊坡穩定系數(或稱安全系數)fos(factorofsafety)求解的表達式如(12)式所示,也就是作為邊坡可靠性求解過程中的響應面函數,從而實現以簡潔的公式替代復雜的隱式過程,這是本實施例中關鍵的一步。
子步驟4,向量機回歸性能檢驗。采用三個指標:平均相對誤差(meanrelativeerror)、相關系數(correlationcoefficient),樣本數量冗余度來考核向量機對訓練樣本的回歸程度,以及訓練樣本數量是否充足。設k個樣本中,yj為穩定系數值實際值(通過步驟s320得到的邊坡穩定系數實際值)fosj為通過(12)式得到的向量機預測值。按下式定義平均相對誤差mre、相關系數r,樣本數量冗余度p。
(14)式中nv為支持向量的數量。平均相對誤差mre越小越好;相關系數r越大越好,其值介于–1與+1之間,即–1≤r≤+1。當r>0時,表示兩變量正相關,r<0時,兩變量為負相關。當|r|=1時,表示兩變量為完全線性相關,即為線性函數關系。當r=0時,表示兩變量間無線性相關關系。對于本實施例描述的問題,建議按三級考核:0<r<0.4為低度線性正相關;0.4≤r<0.7為顯著性正相關;0.7≤r≤1為高度線性正相關。r越逼近+1表示向量機回歸效果越好。樣本數量冗余度p反映了訓練樣本數量是否足夠多。當樣本冗余度高,傾向于認為樣本覆蓋是全面的;相反,當冗余度較低時,意味著較大比例的樣本入選為支持向量,傾向于認為樣本覆蓋面不夠,需要增補訓練樣本。
對本實施例描述的方法而言,建議平均相對誤差絕對值不超過10%,相關系數r不低于0.7,樣本數量冗余度p不低于50%。上述三項指標限值可根據實際情況決定。
子步驟5,樣本調整。當向量機的輸出,即(12)式,無法同時滿足上述要求時,應返回到步驟s310,重新生成新的訓練樣本,并繼續后續流程,直到向量機回歸性能檢測合格為止。具體可從如下兩種方式中選取其一:第一種方法,丟棄上述初始樣本,按步驟1重新生成一組新的正交樣本替代。第二種方法,保留上述初始樣本,按步驟1再增補一組正交樣本。
當滿足向量機回歸性能檢驗時,即(12)式完全確定,進入步驟s340。
步驟s340,根據隨機生成的n個服從于聯合概率分布的待測樣本向量及所述映射關系表達式,獲取邊坡可靠性參數,所述邊坡可靠性參數包括n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差、邊坡失效概率以及可靠度指標,其中,每個所述待測樣本向量由所述m個不確定性參數各自對應的隨機數據構成。
作為一種具體的實施方式,請參閱圖5,所述步驟s340可以包括:
步驟s341,根據隨機生成的n個服從于聯合概率分布的待測樣本向量、所述映射關系表達式以及預設的失穩狀態模糊判別函數,獲取n個待測樣本向量各自對應的邊坡穩定系數,計算所述n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差,其中,每個所述待測樣本向量由所述m個不確定性參數各自對應的隨機數據構成。
其中,所述聯合概率分布為與所述m個不確定性參數的概率分布對應的已知的分布。將隨機生成的n個服從于聯合概率分布的待測樣本向量分別代入所述映射關系表達式中,即可獲取n個待測樣本向量各自對應的邊坡穩定系數f(x)。
進一步的,若在所述步驟s331之前,對所述k個訓練樣本向量中的試驗數據進行了歸一化處理,則在所述步驟s341之前,需對所述隨機生成的n個服從于聯合概率分布的待測樣本向量進行相應的歸一化處理。
步驟s342,根據所述n個待測樣本向量各自對應的邊坡穩定系數以及預設的失穩狀態模糊判別函數,分別計算所述n個待測樣本向量各自對應的模糊隸屬度值。
其中,所述預設的失穩狀態模糊判別函數的表達式為:
其中,lowb<1.0<highb。
根據(16)式可知,預設的失穩狀態模糊判別函數為線性隸屬度函數。fos(x)為邊坡穩定系數,g(fos)為模糊隸屬度值。將所述n個待測樣本向量各自對應的邊坡穩定系數帶入所述預設的失穩狀態模糊判別函數即公式(16)中,即可以計算出所述n個待測樣本向量各自對應的模糊隸屬度值。
(16)式中,lowb和highb分別是在1.0附近函數的上下邊界,當lowb和highb分別取0.9和1.1時對應的函數示意圖如圖6所示,當邊坡穩定系數fos(x)小于或等于下邊界時,g(fos)取1值,表示邊坡失穩;當fos(x)大于上邊界時,g(fos)輸出值為0,表示邊坡穩定;fos(x)處于上下邊界之間時,g(fos)輸出在0~1之間。并且,越接近于1,表示越傾向于判別為失穩。特別地,當fos(x)邊坡穩定系數等于1時的臨界狀態,g(fos)輸出值為0.5,表示判別邊坡失效還是穩定的幾率各占一半,這與通常的認識是相符的。可見,上述模糊評價機制,很好地解決了傳統的邊坡失穩與否狀態判別方法“一刀切”的弊端。特別的,考慮一種極端情況,當lowb與highb趨近于1時(即limlowb=limhighb=1),式(16)退化為不考慮模糊分類的情況,實現了與常規“一刀切”方式相兼容。
在本實施例中,摒棄改變傳統的“按邊坡穩定系數是否大于1來評價穩定性”,這樣簡單粗暴的“一刀切”方式,而采用模糊評判的方法。引入表征失穩狀態的線性隸屬度函數對邊坡的穩定性進行模糊量化。依據線性隸屬度函數,將斜坡的狀態劃分為兩類:即不穩定狀態和穩定狀態(或稱為失穩區和穩定區),即“不穩定、穩定”兩類,這兩類之間不是非此即彼的關系,而是漸變關系。如此,所得到的數學模型更接近于對客觀實際的判斷,提高獲取可靠性參數的準確度。具體到本實施例算法流程而言,只需要給出如式(16)所示的“失穩狀態模糊判別函數”,而與之對應的“穩定狀態模糊判別函數”由于不參與后續運算流程,則無需給出。
步驟s343,計算所述n個待測樣本向量各自對應的模糊隸屬度值的累加和與n的比值,并將所述比值作為所述邊坡失效概率,即:
(17)式中pf為所述邊坡失效概率,nf為統計邊坡失效的次數,nf即為所述n個待測樣本向量各自對應的模糊隸屬度值的累加和。nf在大多數情況下并不是一個整數,這恰恰反映了模糊狀態劃分的成果,只有在lowb與highb趨近于1時(limlowb=limhighb=1),才恒為整數,此時退化為不考慮模糊分類的情況,實現了與常規“一刀切”方式相兼容。
步驟s344,根據所述邊坡失效概率和預設規則,計算所述可靠度指標。
具體地,基于s344,可以通過如下方法計算獲得所述可靠度指標。
由于一般認為邊坡失效概率pf與可靠度指標β滿足如下(18)式關系,所以在已知邊坡失效概率pf的條件下,可采用(19)式計算可靠度指標β。公式(19)為所述預設規則。
β=-φ-1(pf)(19)
(18)~(19)式中φ和φ-1分別為標準正態概率密度函數及其反函數。
其中,獲取的所述n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差、邊坡失效概率以及可靠度指標是邊坡可靠性評估中廣為接受的、核心的量化評估指標,可用于對邊坡的可靠性進行精確評估。
進一步的,為了說明本發明實施例的有益效果,將本發明實施例提供的基于支持向量機的邊坡可靠性參數獲取方法應用于某尾礦壩的邊坡可靠性分析中。
所述某尾礦壩壩坡的概化剖面圖如圖7所示,其巖土體的物理力學性質指標如表1所示,其17個不確定性參數如表2所示,各自服從獨立正態分布。利用正交設計法生成的163個正交訓練樣本向量編碼表如表3所示,求解得到的映射關系表達式參數如表4所示,拉格朗日對偶
表1某尾礦壩壩坡巖土體的物理力學性質指標
表217個不確定性參數
注:17個不確定性參數分別編號為var1-var17
表3163個正交訓練樣本的向量編碼表
注:1)編碼表中“0”、“1”、“2”、“3”、“4”分別代表“均值-3×標準差”、“均值-2×標準差”、“均值”、“均值+2×標準差”和“均值+3×標準差”
2)“sv”代表支持向量,即supportvector,“non-sv”代表非支持向量,即nonsupportvector
表4求解得到的映射關系表達式參數
注:每個輸入向量x包含如表所示的17個變量,分別編號為var1~var17
表5拉格朗日對偶
注:表中列出66組非零拉格朗日對偶取值及其對應的i序號,其余取零的未列出。
i=1,2,…163(共計163組訓練樣本)
表6映射關系表達式回歸效果檢驗
注:建議評價標準為:平均相對誤差絕對值|mre|≤10%,相關系數r≥0.7,樣本數量冗余度p≥50%。
由于所述某尾礦壩壩坡的巖土體由多層結構復雜的土體組成,使得最危險滑動面的位置難于確定,而以有限元法和有限差分法為基礎的強度折減法在用于邊坡穩定性分析時,能夠自動定位最危險滑動面,因此,利用fla3d配合強度折減法,獲取上述163個訓練樣本向量各自對應的邊坡穩定系數,然后根據這163個訓練樣本向量及其各自對應的邊坡穩定系數,通過支持向量機算法,獲取映射關系表達式,其參數如表4和表5所示;而后根據(11)式建立回歸方程;根據表6,支持向量機回歸效果檢驗達標,說明回歸方程滿足精度要求,能夠進入下一個環節;最后,將回歸方程作為可靠性分析中的響應面,即映射關系表達式,采用蒙特卡洛法求解邊坡的失效概率、可靠性指標、穩定系數均值等,結果見表7~8。
表7某尾礦壩壩坡在1百萬次蒙特卡洛模擬下的可靠性分析結果(不考慮模糊分類)
表8某尾礦壩壩坡在1百萬次蒙特卡洛模擬下的可靠性分析結果(考慮模糊分類)
圖8(a)示出了在不同蒙特卡洛模擬次數下的壩坡失效概率,圖中橫坐標為蒙特卡洛模擬次數,縱坐標為邊坡失效概率,對比了考慮模糊分類和不考慮模糊分類兩種情況;圖8(b)示出了在不同蒙特卡洛模擬次數下的邊坡可靠度指標,圖中橫坐標為蒙特卡洛模擬次數,縱坐標為邊坡可靠度指標,對比了考慮模糊分類和不考慮模糊分類兩種情況;表7示出了某尾礦壩在一百萬次蒙特卡洛模擬下的壩坡可靠性參數(不考慮模糊分類);表8示出了某尾礦壩在一百萬次蒙特卡洛模擬下的邊坡可靠性參數(考慮模糊分類)。
對比表7和表8可以發現:表8在考慮失穩狀態的模糊分類條件下,失效概率更高,相應地可靠度指標更小。與不考慮模糊分類相比,評價結果趨于危險。在本實施例中,依據(16)式,分別設置了兩種范圍的模糊區間,當模糊區間為[0.9,1.1]時,對應的可靠度指標和失效概率分別為1.671與0.0474,當模糊區為[0.8,1.2]時,對應的可靠度指標和失效概率分別為1.479與0.0695。可見,隨著模糊區間涵蓋范圍更加寬泛,失效概率進一步增大,可靠度指標進一步減小。
一般在工程上認為,邊坡的穩定系數若不能達到1.2,則安全儲備顯得不足。因此穩定系數即便落在1.0-1.2區間內,仍然不能使人放心。本發明實施例提供的基于模糊分類技術的邊坡可靠性參數獲取方法正是反映了上述考慮。對表7和表8的解讀,可以分兩個層次。第一個層次:常規穩定系數評價方法和基于概率論的可靠性評價方法的差別。以常規評價方法來看,永平尾礦壩穩定系數達到了1.32,這個數值遠大于1.2,說明穩定性較好。但在基于概率論的評價體系下,失效概率4%左右(見表7中pf=0.0396),并不容樂觀。該結果使得對其穩定性的認識更深入了一步。第二個層次:同為可靠性評價方法,是否考慮失效狀態模糊性的差別。在考慮模糊性的條件下,失效概率從4%降低到5%甚至7%,(見表8中pf=0.0474、pf=0.0695)。這說明,如果工程上不考慮模糊分類,則將會使平均結果盲目樂觀。相比之下,采用模糊技術,則是更接近了實際。
本發明實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取方法,根據m個不確定性參數各自對應的均值與標準差,通過正交技術獲取少量訓練樣本向量,再根據這些訓練樣本向量及一個或多個確定性參數的值,通過相關邊坡穩定性分析方法獲取對應的邊坡穩定系數,然后根據隨機生成的n個服從于聯合概率分布的待測樣本向量、所述映射關系表達式以及預設的失穩狀態模糊判別函數,獲取邊坡可靠性參數。通過失穩狀態模糊判別函數對邊坡的穩定性進行模糊量化,進而提高邊坡可靠性參數的準確度。
圖9是本發明第二實施例提供的一種基于模糊分類技術的邊坡可靠性參數獲取裝置400的結構框圖,請參閱圖9,所述基于支持向量機的邊坡可靠性參數獲取裝置400包括訓練樣本生成模塊410、穩定系數獲取模塊420、表達式獲取模塊430以及可靠性參數獲取模塊440。
所述訓練樣本生成模塊410,用于根據m個不確定性參數各自對應的均值與標準差,通過正交設計法,生成k個訓練樣本向量,每個所述訓練樣本向量由所述m個不確定性參數各自對應的試驗數據構成,其中m與k為非零自然數,k的最大取值與m呈指數關系。
作為一種具體的實施方式,請參閱圖10,所述訓練樣本生成模塊410包括第一訓練樣本生成模塊411和第二訓練樣本生成模塊412。
所述第一訓練樣本生成模塊411,用于根據m個不確定性參數的均值和標準差,通過正交設計法,至少生成一組第一訓練樣本向量,每個所述不確定性參數對應的均值為μi,標準差為σi,每個所述第一訓練樣本向量中的每個所述不確定性參數對應的試驗數據為μi-2σi、μi、μi+2σi,或者為μi-3σi、μi、μi+3σi,其中i=1,2,…,m,所述第一訓練樣本向量的數量為nj,nj≤3m,j∈n+。
所述第二訓練樣本生成模塊412,用于合并至少一組所述第一訓練樣本向量為訓練樣本向量,所述訓練樣本向量的樣本數為k,
所述穩定系數獲取模塊420,用于根據所述k個訓練樣本向量及一個或多個確定性參數的值,通過邊坡穩定性分析方法,獲取所述k個訓練樣本向量各自對應的邊坡穩定系數。
所述表達式獲取模塊430,用于以所述k個訓練樣本向量為自變量,以其各自對應的邊坡穩定系數為因變量,構成映射關系,通過支持向量機算法,獲取所述映射關系表達式。
作為一種具體的實施方式,請參閱圖11,所述表達式獲取模塊430可以包括第一獲取模塊431以及第二獲取模塊432。
所述第一獲取模塊431,用于根據所述k個訓練樣本向量及其各自對應的邊坡穩定系數,以及預設規則,獲取最優偏移量以及所述k個訓練樣本向量各自對應的最優拉格朗日對偶。
優選的,所述第一獲取模塊431還包括第一處理模塊431a,所述第一處理模塊431a,用于在根據所述k個訓練樣本向量及其各自對應的邊坡穩定系數,以及預設規則,獲取最優偏移量以及所述k個訓練樣本向量各自對應的最優拉格朗日對偶之前,對所述k個訓練樣本向量中的試驗數據進行歸一化處理。
所述第二獲取模塊432,用于根據所述最優偏移量、所述k個訓練樣本向量及其各自對應的最優拉格朗日對偶,獲取映射關系表達式。
所述可靠性參數獲取模塊440,用于根據隨機生成的n個服從于聯合概率分布的待測樣本向量、所述映射關系表達式以及預設的失穩狀態模糊判別函數,獲取邊坡可靠性參數,所述邊坡可靠性參數包括n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差、邊坡失效概率以及可靠度指標,其中,每個所述待測樣本向量由所述m個不確定性參數各自對應的隨機數據構成。
作為一種具體的實施方式,請參閱圖12,所述可靠性參數獲取模塊440可以包括第一計算模塊441、第二計算模塊442、第三計算模塊443及第四計算模塊444。
所述第一計算模塊441,用于根據隨機生成的n個服從于聯合概率分布的待測樣本向量及所述映射關系表達式,獲取n個待測樣本向量各自對應的邊坡穩定系數,計算所述n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差,其中,每個所述待測樣本向量由所述m個不確定性參數各自對應的隨機數據構成。
進一步的,若所述第一獲取模塊431包括第一處理模塊431a,則所述第一計算模塊441還包括第二處理模塊441a,所述第二處理模塊441a,用于在所述根據隨機生成的n個服從于聯合概率分布的待測樣本向量及所述映射關系表達式,獲取n個待測樣本向量各自對應的邊坡穩定系數之前,對所述隨機生成的n個服從于聯合概率分布的待測樣本向量進行歸一化處理。
所述第二計算模塊442,用于根據所述n個待測樣本向量各自對應的邊坡穩定系數以及所述預設的失穩狀態模糊判別函數,分別計算所述n個待測樣本向量各自對應的模糊隸屬度值。
所述第三計算模塊443,用于計算所述n個待測樣本向量各自對應的模糊隸屬度值的累加和與n的比值,并將所述比值作為所述邊坡失效概率。
所述第四計算模塊444,據所述邊坡失效概率和預設規則,計算所述可靠度指標。
其中,獲取的所述n個待測樣本向量各自對應的邊坡穩定系數的均值和標準差、邊坡失效概率以及可靠度指標是邊坡可靠性評估中廣為接受的、核心的量化評估指標,可用于對邊坡的可靠性進行精確評估。
以上各模塊可以是由軟件代碼實現,此時,上述的各模塊可存儲于服務器100的存儲器110內。以上各模塊同樣可以由硬件例如集成電路芯片實現。
本發明實施例所提供的基于模糊分類技術的邊坡可靠性參數獲取裝置400,其實現原理及產生的技術效果和前述方法實施例相同,為簡要描述,裝置實施例部分未提及之處,可參考前述方法實施例中相應內容。
在本申請所提供的幾個實施例中,應該理解到,所揭露的裝置和方法,也可以通過其它的方式實現。以上所描述的裝置實施例僅僅是示意性的,例如,附圖中的流程圖和框圖顯示了根據本發明的多個實施例的裝置、方法和計算機程序產品的可能實現的體系架構、功能和操作。在這點上,流程圖或框圖中的每個方框可以代表一個模塊、程序段或代碼的一部分,所述模塊、程序段或代碼的一部分包含一個或多個用于實現規定的邏輯功能的可執行指令。也應當注意,在有些作為替換的實現方式中,方框中所標注的功能也可以以不同于附圖中所標注的順序發生。例如,兩個連續的方框實際上可以基本并行地執行,它們有時也可以按相反的順序執行,這依所涉及的功能而定。也要注意的是,框圖和/或流程圖中的每個方框、以及框圖和/或流程圖中的方框的組合,可以用執行規定的功能或動作的專用的基于硬件的系統來實現,或者可以用專用硬件與計算機指令的組合來實現。
另外,在本發明各個實施例中的各功能模塊可以集成在一起形成一個獨立的部分,也可以是各個模塊單獨存在,也可以兩個或兩個以上模塊集成形成一個獨立的部分。
所述功能如果以軟件功能模塊的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:u盤、移動硬盤、只讀存儲器(rom,read-onlymemory)、隨機存取存儲器(ram,randomaccessmemory)、磁碟或者光盤等各種可以存儲程序代碼的介質。需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
以上所述僅為本發明的優選實施例而已,并不用于限制本發明,對于本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。因此,本發明的保護范圍應所述以權利要求的保護范圍為準。應注意到:相似的標號和字母在下面的附圖中表示類似項,因此,一旦某一項在一個附圖中被定義,則在隨后的附圖中不需要對其進行進一步定義和解釋。
- 還沒有人留言評論。精彩留言會獲得點贊!