基于詞袋模型的全景圖像拼接方法與流程
本發明屬于計算機視覺和數字圖像處理領域。
背景技術:
圖像拼接技術是計算機視覺和數字圖像處理領域的一個重要分支,它是將兩幅以上的具有部分重疊的圖像進行無縫拼接從而得到較高分辨率或寬視角圖像的技術。圖像拼接中兩個最為關鍵環節為圖像配準和圖像融合。對于圖像融合技術,現階段方法在耗時和融合效果方面差別不大,已趨于成熟。但是對于圖像配準,由于其配準時間及效果直接影響到圖像拼接的速度和成功率,所以圖像配準一直是當前圖像拼接方面研究的熱點。常見的圖像配準方法都是基于sift或者是surf特征描述圖像的,這些特征描述子的優點在于旋轉不變性,尺度不變性以及不易受光照影響,現階段的研究開始關注brief,orb以及brisk等二進制特征,因為其需要更少的存儲空間以及計算的快速性。但是現階段的圖像拼接方法大都是基于幀對幀的比較方法,這種方法在圖像數目較少時可以收到很好的效果,但是,隨著圖像數目的增加,這種方法在實時性要求較高時就不適用。
技術實現要素:
本發明的目的是提出一種適用于實時性要求較高的基于詞袋模型的全景圖像拼接方法,技術方案如下。
一種基于詞袋模型的全景圖像拼接方法,包括下列步驟:
1)準備已經訓練好的orb詞袋樹;
2)對于待拼接圖像數據集里的圖像i,進行orb特征提取,將圖像i中提取的特征描述子按照漢明距離從orb詞袋樹的根節點開始逐級向下到達葉子節點,遍歷完所有的特征之后,在詞袋樹中存儲該圖像所有特征的正向索引,設k為上一插入到拼接結構圖的關鍵幀,通過正向索引對兩幅圖像進行特征搜索,建立特征之間的對應,從而得到兩幅圖像間特征的對應;
3)根據得到的兩幅圖像之間特征的對應,得到兩幅圖像之間的單應性矩陣khi;
4)利用隨機抽樣極大似然估計算法來最小化二次投影誤差和排除外點,進而得到對應圖像對的內點集;
5)根據得到的內點集計算圖像的邊界矩陣,通過邊界矩陣計算圖像的重疊百分比;
6)根據計算的重疊百分比,計算對應圖像對之間的重疊koi=min(ok,oi),如果內點的數目大于閾值τin并且重疊koi大于閾值τov,那么圖像i作為潛在的關鍵幀保存,如果待拼接數據集中下一幀圖像與關鍵幀k得到的內點數目和重疊不滿足上述兩個閾值,則將圖像i作為關鍵幀加入到拼接結構圖;
7)當圖像i作為關鍵幀加入到拼接結構圖中時,需要與之前的關鍵幀通過單應性矩陣建立聯系,即圖像i為拼接結構圖的第k+1關鍵幀,則khi就表示為khk+1,則第k+1關鍵幀的單應性矩陣mhk+1表示為:mhk+1=mhkkhk+1,其中,mhk表示第k關鍵幀的單應性矩陣,m是為保證關鍵幀之間的對齊而定義的一個通用關鍵幀;
8)檢測回環,新加入的關鍵幀圖像i,與拼接結構圖之前所有的關鍵幀圖像進行檢索匹配:新加入關鍵幀圖像的orb特征進入詞袋模型,按照漢明距離從詞袋樹的根節點開始逐級向下到達葉子節點,計算每個葉子節點也就是詞袋樹中每個詞在圖像i中出現的頻率tf,將新加入關鍵幀圖像的所有特征,在詞袋樹中做檢索,得到每個詞的值,將這些值構成圖像的描述向量;設新加入關鍵幀圖像和與其匹配的上一關鍵幀圖像的描述向量分別為ν1和ν2,兩幅關鍵幀圖像的相似度分數計算公式表示為:
得分越高表示這兩幅關鍵幀圖像的相似度越高,由此可以得到新加入關鍵幀圖像與之前關鍵幀圖像的相似程度,從而可以得到一個從高到低關鍵幀相似度列表,這些關鍵幀圖像即為有可能與新加入關鍵幀圖像形成回環的關鍵幀。
9)根據關鍵幀相似度列表順序,計算這些關鍵幀與新加入關鍵幀的單應性矩陣,如果通過單應性矩陣得到的內點數目大于一個固定的閾值,那么相應的連接關系就成為拼接結構圖的一部分,即為形成回環;
10)優化單應性矩陣,采用光束法平差減小由單應性矩陣所造成的誤差,誤差函數ε為:
其中
11)圖像拼接結構圖的融合。
本發明主要優點及特色體現在如下幾個方面:
1、目前圖像拼接算法中圖像配準都是基于sift或者是surf特征描述圖像的,得益于這些特征的尺度、旋轉不變性以及不易受光照影響,但是這些特征的提取需要的時間過多,造成算法的實時性達不到要求,此外圖像配準為基于幀對幀的匹配,也會增加配準時間。本發明提出的基于詞袋模型的檢索結構,采用orb特征描述子。實驗表明,基于詞袋模型的圖像配準方法在同樣得到配準效果的同時,可以顯著減少算法時間。
2、目前圖像拼接算法大都基于單線程的算法,算法各個部分之間有著明顯的順序性和耦合性,本發明的算法可以采用多線程架構,實現算法不同部分的同時執行,實現在保證拼接效果的基礎上,可以有效的縮短算法時間。
附圖說明
圖1是本發明基于詞袋模型的多線程圖像拼接算法的流程圖;
圖2是valldemossa數據集的圖像拼接圖;
圖3是valldemossa數據集的拓撲結構圖;
圖4是odemar數據集的圖像拼接圖;
圖5是odemar數據集的拓撲結構圖。
具體實施方式
本發明提出基于詞袋模型的多線程全景圖像拼接技術,結合實例及附圖詳細說明如下:
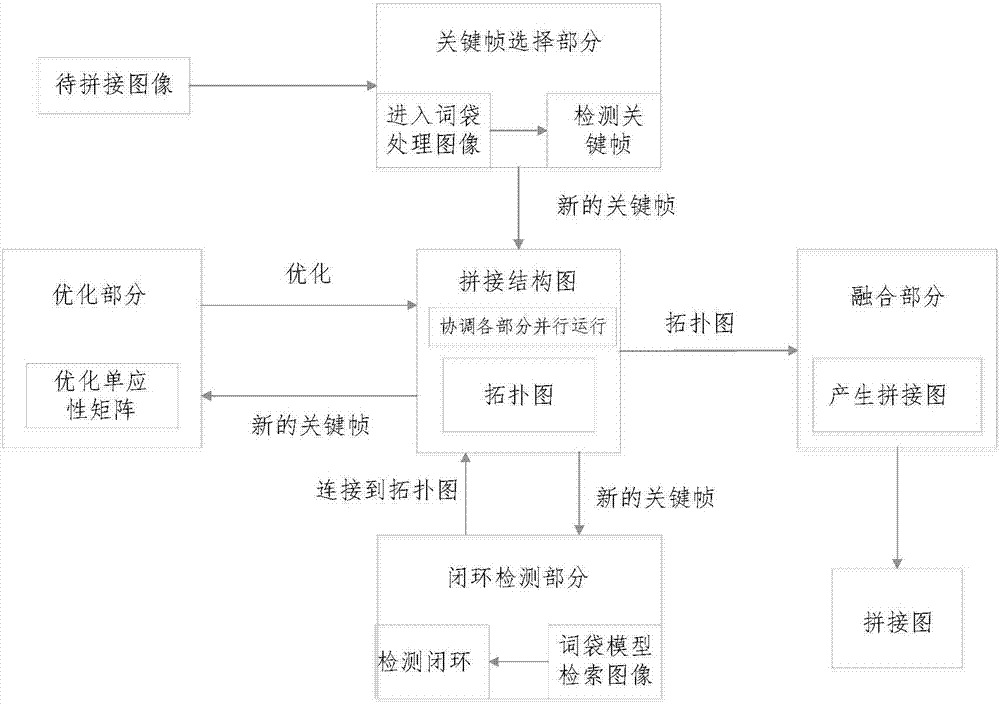
本發明算法的整體框架如圖1所示,系統分為四部分且這四部分可并行運行,這種并行的設計可以減少各個部分之間的耦合性,從而減少算法運行的時間。這四個部分通過一個稱為拼接結構圖的結構相連接,這個結構用來估計拼接環境的拓撲結構,同時用于協調各個部分之間的關系,保證實時性。
拼接結構圖部分是本發明方法的一個重要組成部分,其中的拓撲圖代表著拼接環境的拓撲結構,以及統一不同部分之間運行的機制。環境的拓撲結構表示參與圖像拼接的圖像及其之間的聯系。在本發明中,拓撲結構的數學模型是無向圖的形式,其中節點代表著最終拼接中所選擇的圖像,連接線代表著它們之間的重疊部分,在本發明中,被選擇的圖像稱為關鍵幀。為了產生最終的拼接圖,需要選取關鍵幀,即為拼接圖像幀。
系統其他部分和拼接結構圖的建立是同步進行的,關鍵幀部分描述輸入圖像,進入詞袋檢索結構處理圖像以及決定圖像為關鍵幀,是否為最終拼接結構圖像的組成部分;閉環檢測部分在檢測匹配圖像對后可以建立當前幀與所匹配關鍵幀的聯系,形成回環;優化部分通過光束法平差調整單應性矩陣,來減少誤匹配造成的誤差;優化之后的拼接結構圖進入融合部分產生最后的拼接圖。具體實施方案如下:
7)構建詞袋樹,dbow2庫利用一個大的圖像數據庫,離線訓練好了orb庫和sift庫,供大家使用。在本發明中,使用的是dbow2庫中已經訓練好的orb詞袋樹。
8)對于待拼接圖像數據集里的圖像i,進行orb特征提取,將圖像i中提取的特征描述子按照漢明距離從orb詞袋樹的根節點開始逐級向下到達葉子節點,遍歷完所有的特征之后,在詞袋樹中存儲該圖像所有特征的正向索引。k為上一插入到拼接結構圖的關鍵幀,通過正向索引對兩幅圖像進行特征搜索,建立特征之間的對應,從而得到兩幅圖像間特征的對應;
9)根據得到的兩幅圖像之間特征的對應,得到兩幅圖像之間的單應性矩陣khi;
10)利用隨機抽樣極大似然估計算法來最小化二次投影誤差和排除外點,進而得到對應圖像對的內點集;
11)根據得到的內點集計算圖像的邊界矩陣,通過邊界矩陣計算圖像的重疊百分比;
12)根據計算的重疊百分比,計算對應圖像對之間的重疊koi=min(ok,oi),如果內點的數目大于閾值τin并且重疊koi大于閾值τov,那么圖像i作為潛在的關鍵幀保存,如果待拼接數據集中下一幀圖像與關鍵幀k得到的內點數目和重疊不滿足上述兩個閾值,則將圖像i作為關鍵幀加入到拼接結構圖;
7)當圖像i作為關鍵幀加入到拼接結構圖中時,需要與之前的關鍵幀通過單應性矩陣建立聯系,則第k+1關鍵幀的單應性矩陣mhk+1表示為:mhk+1=mhkkhk+1,其中m是為了保證關鍵幀之間的對齊而定義的一個通用關鍵幀,拼接結構圖中各個關鍵幀的單應性矩陣mhk+1,mhk都是與關鍵幀m建立的;
8)檢測回環,新加入的關鍵幀圖像i,與拼接結構圖之前所有的關鍵幀圖像進行檢索匹配:新加入關鍵幀圖像的orb特征進入詞袋模型,按照漢明距離從詞袋樹的根節點開始逐級向下到達葉子節點,計算每個葉子節點也就是詞袋樹中每個詞在圖像i中出現的頻率tf,在詞袋樹中每個葉子節點都存儲了反向索引,即為存儲了到達葉子節點的圖像id和詞在圖像描述向量中的值,將新加入關鍵幀圖像的所有特征,在詞袋樹中做檢索,得到每個詞的值,將這些值構成圖像的描述向量;設新加入關鍵幀圖像和與其匹配的上一關鍵幀圖像的描述向量分別為ν1和ν2,兩幅關鍵幀圖像的相似度分數計算公式表示為:
得分越高表示這兩幅關鍵幀圖像的相似度越高,由此可以得到新加入關鍵幀圖像與之前關鍵幀圖
像的相似程度,從而可以得到一個從高到低關鍵幀相似度列表,這些關鍵幀圖像即為有可能與新加入關
鍵幀圖像形成回環的關鍵幀。
9)根據關鍵幀相似度列表順序,計算這些關鍵幀與新加入關鍵幀的單應性矩陣,如果通過單應性矩陣得到的內點數目大于一個固定的閾值,那么相應的連接關系就成為拼接結構圖的一部分,即為形成回環;
10)優化單應性矩陣,關鍵幀圖像之間都是通過單應性矩陣進行聯系的,然而單應性矩陣存在著誤差,需要進行優化,采用光束法平差減小由單應性矩陣所造成的誤差,誤差函數ε為:
其中
11)圖像拼接結構圖的融合。
融合是拼接算法的最后一步,用于產生最后的無縫拼接圖,這一部分是opencv庫中stitching的應用,包括縫和線技術以及曝光補償,在本發明中,這一部分根據之前產生的拼接結構圖可以即時形成最終的無縫拼接圖,即最終的實驗效果圖。
為了驗證本發明方法的有效性和實時性,本發明選用兩組數據集。valldemossa數據集,此數據集采集于西班牙的港口城市valldemossa的水下環境,包含201張320×180的圖片,是由相機俯視拍攝的,此數據集包含有一個大的閉環;odemar數據集,此數據集為由miquelmassot-campos采集的水下環境,包含64張480×270的圖片,是由相機仰視拍攝的,此數據集沒有包含大的閉環。實驗結果如下:
1.得到的valldemossa數據集的拼接圖如圖2所示,環境的拓撲估計如圖3所示,拓撲圖含有76幀關鍵幀。得到odemar數據集的拼接圖如圖4所示,環境的拓撲結構圖如圖5所示,拓撲圖含有22幀關鍵幀。
2.此組實驗為對比試驗,由本發明的方法與采用orb特征的單線程拼接方法的比較,依然選用這兩組數據集,得到的實驗數據如表1所示,可以看到,在二次投影誤差差別不大的情況下,算法的時間得到了很大的改善。
表1是本發明的實驗數據與基于orb特征的單線程圖像拼接算法的數據對比;
表1。
- 還沒有人留言評論。精彩留言會獲得點贊!