一種針對多路h.264視頻會議的GPU解碼方法與流程
本發明涉及視頻會議技術領域,特別涉及一種針對多路h.264視頻會議的gpu解碼方法。
背景技術:
由itu-t與ios/iec兩大國際標準化組織于2003年共同提出的h.264視頻編解碼標準是當今視頻壓縮領域中壓縮性能最優的實用視頻編解碼標準。與以前的國際標準如h.263和mpeg-4相比,最大的優勢體現在以下四個方面:1.將每個視頻幀分離成由像素組成的塊,因此視頻幀的編碼處理的過程可以達到塊的級別;2.采用空間冗余的方法,對視頻幀的一些原始塊進行空間預測、轉換、優化和熵編碼(可變長編碼);3.對連續幀的不同塊采用臨時存放的方法,這樣,只需對連續幀中有改變的部分進行編碼。該算法采用運動預測和運動補償來完成。對某些特定的塊,在一個或多個已經進行了編碼的幀執行搜索來決定塊的運動向量,并由此在后面的編碼和解碼中預測主塊;4.采用剩余空間冗余技術,對視頻幀里的殘留塊進行編碼。例如:對于源塊和相應預測塊的不同,再次采用轉換、優化和熵編碼。
h.264編解碼算法性能的改善是以算法復雜度的提高為代價的,如何在不影響解碼圖像質量的前提下提高解碼效率,是眾多學者共同的研究方向。
近年來,圖形處理器(graphicprocessunit,gpu)的快速發展使得其逐步用于通用計算。nvidia于2007年推出的統一計算設備架構(computedunifieddevicearchitecture,cuda)為通用計算提供了良好的軟硬件開發環境。
對高清視頻進行編解碼過程中運算量龐大,不符合眾多實時編解碼應用的需要。國內外學者們嘗試在不同的處理器上使用相應的多媒體擴展指令集來提高編解碼速度。如英特爾針對奔騰系列處理器提供的mmx/sse指令集,將具備simd處理機制的cpu用于視頻編解碼,取得了一定的加速效果,但是由于cpu超高負荷運轉的問題沒有解決,所以系統整理的利用率仍然不高。另有一些研宄人員使用dsp芯片、以及等硬件電路來實現視頻編解碼的加速,部分實驗取得了不錯的效果,但是由于硬件設備價格昂貴等原因,不能推廣使用。
有鑒于此,有必要提出一種新的方法來解決多路實時視頻流解碼速度提升的問題。
技術實現要素:
有鑒于此,本發明的目的是提供一種針對多路h.264視頻會議的gpu解碼方法。可有效地提高多路視頻流的解碼速度,達到實時的效果。
為實現上述發明目的,本發明提供了一種基于gpu的多路h.264視頻實時解碼方法,所述方法包括以下步驟:
s1:通過各分會場mcu輸入多路視頻會議流;
s2:依據視頻流中的ip信息區分每個會場;
s3:采用cpu和gpu主從線程的協作方式對每個會場分別進行解碼,并行的多路對視頻流進行解封包、解碼。
s4:將解碼之后的數據儲存在服務器上便于以后查看。
s5:針對客戶端的請求對解碼的數據重編碼,并通過網絡傳輸到客戶端。
s6:客戶端顯示服務器發送的統計信息以及視頻流。
進一步,所述步驟s3中,將cpu和gpu設計成主從線程的協作方式,取締cpu和gpu互相等待的狀態,實現cpu和gpu的同時并行工作。
進一步,所述步驟s3中,在傳統解碼器的基礎上采用主機端和設備端協同工作的并行解碼器架構,對h.264串行解碼器各模塊進行任務劃分,其中將解析出的供后續模塊使用的參數以及殘差數據經過pci-e總線傳輸給設備端,cpu負責從網絡提取層中獲取經壓縮的碼流,并對其進行碼流分析、熵解碼、重排序工作;gpu負責反變換、反量化、幀內預測、幀間預測以及環路濾波模塊的并行實現。
進一步,所述步驟s3中,采用整幀圖像并行的方法實現幀內編碼過程,將模式選擇過程與幀內預測編碼過程中計算過程分開。
進一步,所述步驟s3中,在h.264視頻編碼的預測編碼過程中,預測編碼是以宏塊為單位進行的,而宏塊之間預測過程中利用相鄰宏塊的信息,幀內預測過程中利用相鄰塊的重建圖像來預測當前塊。
進一步,所述步驟s3中,整幀圖像并行的幀內預測過程實現的步驟如下:(1)根據原始幀數據來計算預測幀的最佳4x4幀內預測模式,記錄每個子宏塊的最佳預測模式和代價cost_sub_4;(2)將每個宏塊的16個cost__sub_4求和得到cost_4;(3)計算所有宏塊的16x16宏內預測模式,并保存最佳預測模式及代價cost_16;(4)比較cost_4和cost_16的大小,保存宏塊的最佳預測模式,并在共享內存中讀取最佳的宏塊預測編碼值;(5)根據得到的最佳預測模式進行幀內預測編碼。
進一步,所述步驟s3中,因為同一時刻會有多路碼流同時到達解碼端,通過下述方法協調多路碼流的進入順序,以使解碼系統能夠正常工作,具體是通過gpu輪詢系統發出第i路碼流的請求,視頻網核心交換機進行應答,并發送相應的碼流數據,再由輪詢系統輸出碼流數據,并對碼流數據進行檢測。
進一步,所述步驟s5中,采用服務器與客戶端交互的方式來完成視頻的傳輸,根據客戶端請求的不同采用多路解碼之后對其中某一路單獨編碼的方式。
進一步,所述步驟s1中,通過攝像機獲取各個分會場的視頻會議的視頻流,攝像機所處位置位于會場斜上方。
進一步,所述步驟s3中,gpu視頻解碼利用direct3d、opengl和/或cuda實現解碼器中的運動補償和可視化顯示。
本發明的有益效果是:
本發明的多路h.264視頻會議的gpu解碼方法,能夠對同時開會的多個會場的多路視頻進行解碼,實現了視頻會議自動化,主要解決多個會場同時開會時,多路視頻碼流實時傳輸、解碼、播放的問題,本發明針對每一路的h.264視頻碼流將cpu和gpu設計成主從線程的協作方式,取締cpu和gpu互相等待的狀態,實現cpu和gpu的同時并行工作,并對解碼之后的圖像重新編碼,并且存儲,使之能夠在客戶端進行播放,從而拓展了易用性和功能性,本發明可節省人力資源成本,提升了效率,具有較高的推廣應用價值。
本發明的其他優點、目標和特征在某種程度上將在隨后的說明書中進行闡述,并且在某種程度上,基于對下文的考察研究對本領域技術人員而言將是顯而易見的,或者可以從本發明的實踐中得到教導。本發明的目標和其他優點可以通過下面的說明書和權利要求書來實現和獲得。
附圖說明
為了使本發明的目的、技術方案和優點更加清楚,下面將結合附圖對本發明作進一步的詳細描述,其中:
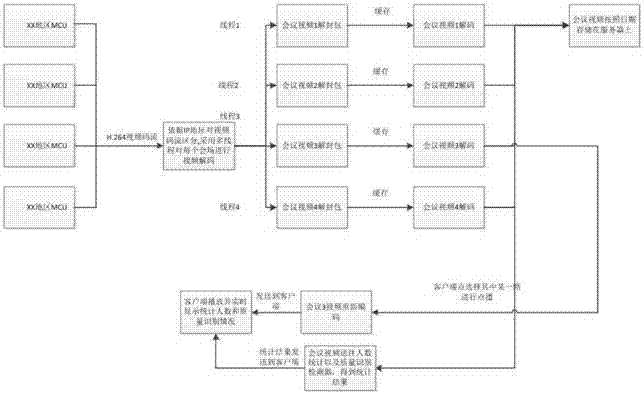
圖1為本發明一種針對多路h.264視頻會議的gpu解碼方法;
圖2為gpu輪詢工作系統運作流程示意圖;
圖3為本發明中cpu和gpu主從線程的協作方式示意圖;
圖4為gpu解碼流程示意圖;
圖5為整幀圖像并行的幀內預測編碼流程。
具體實施方式
以下將參照附圖,對本發明的優選實施例進行詳細的描述。應當理解,優選實施例僅為了說明本發明,而不是為了限制本發明的保護范圍。
下面結合附圖所示的各實施方式對本發明進行詳細說明。
請參圖1所示,圖1為本發明一種針對多路h.264視頻會議的gpu解碼方法的具體實施方式中的流程示意圖。該方法包括如下步驟:
步驟s1:通過各分會場mcu輸入多路視頻會議流;
具體采用對應的視頻會議的攝像機(一般位于視頻會議會場正前方偏上方45度),將采集到的視頻流通過h.264編碼通過ip鏡像的形式發送到服務器端。
步驟s2:依據視頻流中的ip信息區分每個會場;
對接受到的ip報文進行解包后,根據ip地址的不同確定具體正在開會的會場。考慮到實時輪詢系統的需求,同一時刻會有多路碼流同時到達解碼端,因此必須協調多路碼流的進入順序,以使解碼系統能夠正常工作。為此設計了如圖2所示的gpu實時輪詢系統。首先需要在gpu實時輪詢系統與視頻網核心交換機之間建立握手協議。完成三次握手,客戶端與服務器便建立了握手協議。之后gpu輪詢系統發出第i路碼流的請求,視頻網核心交換機進行應答,并發送相應的碼流數據。再由輪詢系統輸出碼流數據,并對碼流數據進行檢測。在實際的h264數據幀中,往往幀前面帶有00000001或000001分隔符,因此只需檢測startcode就能得到每一幀的網絡提取層(nal)單元。
步驟s3:采用cpu和gpu主從線程的協作方式對每個會場分別進行解碼,并行的多路對視頻流進行解封包、解碼;
gpu的優勢是利用最短的時間完成大量的并行運算,但是數據在主設端之間進行傳輸時,會花費許多額外的開銷。如果進行過多的數據交換,將會大大降低解碼所用的時間。另外,在原有的h.264的解碼標準中,許多過程都是針對串行cpu設計的。本發明考慮將cpu和gpu設計成主從線程的協作方式,取締cpu和gpu互相等待的狀態,實現cpu和gpu的同時并行工作。如圖3所示,gpu在處理第n幀的模塊時,cpu同時解析第n+1幀的數據,充分利用碎片時間,達到更高的處理效率。
作為進一步的改進,該解碼過程中,在傳統解碼器的基礎上采用主機端和設備端協同工作的并行解碼器架構,對h.264串行解碼器各模塊進行任務劃分。其中,將解析出的供后續模塊使用的參數以及殘差數據經過pci-e總線傳輸給設備端cpu主要負責從網絡提取層中獲取經壓縮的碼流,并對其進行碼流分析、熵解碼、重排序工作;gpu主要負責反變換、反量化、幀內預測、幀間預測以及環路濾波模塊的并行實現。在整個解碼過程中,cpu和gpu形成主從線程的并行執行,避免了主設端的任務等待,時間和空間資源得到了充分利用。cpu主要負貴邏輯控制復雜的部分,包括碼流讀取、碼流分析、熵解碼及重排序模塊;gpu主要負責數據密集度高且獨立性強的模塊,包括幀內預測、幀間預測、變換解碼和環路濾波,本發明采用模塊內并行執行、模塊間串行執行的設計,盡量減少主機端與設備端的數據傳輸,降低解碼總耗。解碼框架及主設端任務分配如圖4所示。
其中步驟s3采用整幀圖像并行的方法實現幀內編碼過程,將模式選擇過程與幀內預測編碼過程中計算過程分開。模式選擇過程根據原始幀的數據進行選擇,這樣可以所有宏塊同時并行執行,提高并行粒度,而后面的過程仍然是按照之前h.264視頻編碼標準中的過程進行。而大量的實驗表明,在量化參數qp不大的情況下,使用原始幀數據代替重構幀來進行模式選擇,計算過程中的并行粒度會大幅度提升,由于幀內預測模式的選擇使用的是原始數據,這種預測編碼方式可能會造成圖像質量的下降,這種圖像質量的損失在普通人可以接受的范圍之內,并不影響肉眼的感官。
步驟s3中,在h.264視頻編碼的預測編碼過程中,預測編碼是以宏塊為單位進行的,而宏塊之間預測過程中需要利用相鄰宏塊的信息,幀內預測過程中需要利用相鄰塊的重建圖像來預測當前塊。如果不釆取這種方式,會導致最后編解碼不一致的情形,從而產生編碼錯誤的問題,而gpu的優勢是高并發性,不相關數據之間的多線程并發,很顯然如果無法解決這些問題,就無法利用gpu的計算優勢,很難有加速的效果。
步驟s3中,整幀圖像并行的幀內預測過程實現的步驟如下:(1)根據原始幀數據來計算預測幀的最佳4x4幀內預測模式,記錄每個子宏塊的最佳預測模式和代價cost_sub_4,此過程中可以做到所有的子宏塊同時并行執行,并行粒度可以達到(width/4)*(height/4;);1080p高清視頻的并行粒度為30560;(2)將每個宏塊的16個cost__sub_4求和得到cost_4;(3)計算所有宏塊的16x16宏內預測模式,并保存最佳預測模式及代價cost_16,此過程是可以達到所有宏塊并行,并行粒度為(width/16)*(height/16),1080p高清視頻的并行粒度為8160;(4)比較cost_4和cost_16的大小,保存宏塊的最佳預測模式,并在共享內存中讀取最佳的宏塊預測編碼值;(5)根據得到的最佳預測模式進行幀內預測編碼,此編碼過程采用行波流水法進行幀內預測,之后是dct變換、量化與反量化、反dct變換過程,在此過中,1080p高清視頻最多可以設置68個block并行,通過120層循環完成對整幀數據的幀內預測編碼過程。具體的流程圖如圖5所示。
步驟s4:解碼之后的數據儲存在服務器上便于以后查看,本實施例中,會議視頻按照日期存儲于服務器上,數據的存儲采用h.264裸流文件進行存儲,這樣的存儲方式有兩個優點,一方面有效地節省了存儲空間,相對于解碼完成的yuv原始視頻數據而言,同一場會議的h.264裸流文件能夠節約大約70%的空間,另一方面,h.264裸流文件能夠在客戶端請求觀看的時候快速的通過網絡從服務器傳輸到客戶端,而不需要重新編碼,降低了服務器整體的消耗。
步驟s5:針對客戶端的請求對解碼的數據重編碼,由于實時的需求,h.264編碼的過程中不能出現b幀,防止由于b幀對后續視頻幀引用而造成的視頻解碼延遲,整個視頻流主要由i幀和p幀組成,通過編碼器按照固定的分辨率傳輸到客戶端。
步驟s6:客戶端對服務器發送的視頻流進行解碼并且實時顯示在桌面上。
本發明的方法主要包括:對多路來自下方地區局會場的mcu的視頻流數據經過濾篩選之后,通過gpu多線程對每一路視頻流進行解封包、解碼,將解碼之后數據按照日期儲存在視頻服務器上,并與客戶端發出的請求互動,在客戶端請求某一路的視頻數據之后,對該路視頻流重新編碼,以使視頻流數據能夠在客戶端進行播放。該方法主要解決多個會場同時開會時,多路視頻碼流實時傳輸、解碼、播放的問題,針對每一路的h.264視頻碼流將cpu和gpu設計成主從線程的協作方式,取締cpu和gpu互相等待的狀態,實現cpu和gpu的同時并行工作,并對解碼之后的圖像重新編碼,并且存儲,使之能夠在客戶端進行播放。本方法解決了多個會場同時開會時,多路視頻碼流實時傳輸、解碼、播放的問題,取締cpu和gpu互相等待的狀態,實現cpu和gpu的同時并行工作,提升了效率,具有較高的推廣應用價值。
最后說明的是,以上實施例僅用以說明本發明的技術方案而非限制,盡管參照較佳實施例對本發明進行了詳細說明,本領域的普通技術人員應當理解,可以對本發明的技術方案進行修改或者等同替換,而不脫離本技術方案的宗旨和范圍,其均應涵蓋在本發明的權利要求范圍當中。
- 還沒有人留言評論。精彩留言會獲得點贊!