一種人聲音頻信號采樣處理方法與流程
本發明屬于智能家居技術領域,特別涉及一種人聲音頻信號采樣處理方法。
背景技術:
音頻的采集處理過程中,降噪是一個關鍵步驟。在日常生活中,降噪是指消除噪音,而對于擁有更高要求的音頻分類提取過程來說,噪聲指的是除目標音源外的所有其他音頻。通常對于音頻降噪除噪的處理方法,有采樣除噪法、噪聲門等。
采樣除噪法是一些專業音頻處理軟件比較有效除去持續穩定的背景噪音的一種方法,除噪的原理就是對噪音的波形樣本進行取樣,然后對爭端素材的波形和采樣噪音樣本分析,自動去除噪音;噪聲門則是設定一個電平的門限值,低于這個門限的信號電平全部過濾掉,高于門限值的信號電平全部通過。
使用音頻處理軟件雖然能夠在一定程度上實現噪音消除,提取出目標音頻,但也存在先錄音、再處理,需要人工判斷采樣的缺點,從實用角度來講極大限制了未來人工智能領域在語音解析方面的技術發展。
隨著人工智能技術的發展,人機語音對話、聲紋識別、語音與文字轉換、語音語義解析等需求越來越強烈,對于音頻的采樣、降噪要求也飛速提升,特別是對與音頻的實時分析處理,更是對產品起到至關重要的作用。
技術實現要素:
本發明提供一種人聲音頻信號采樣處理方法,目的是解決現有人聲語音采集分析中抑制噪聲的問題。
一種人聲音頻信號采樣處理方法,包括以下步驟:
由麥克風偵測并收集無人聲的環境噪音,該噪音的音頻信號的模擬信號以96KHz或以上的采樣頻率采樣,得到該噪音的數字信號序列;
計算獲得與所述數字信號序列頻譜相同、相位相差180°的抑噪信號數字序列,
將抑噪信號數字序列反向還原成模擬信號,將該抑噪模擬信號與麥克風采集的含有人聲的音頻信號混合,使得抑噪信號與噪音信號互相抵消,從而獲取到清晰、無干擾的人聲語音。
進一步的,
當環境在發出噪聲音頻時,麥克風采集該噪聲音頻,通過高采樣率芯片將音頻信號轉換成一個數值序列,對該數值序列進行運算,獲得與該音頻信號頻譜相同、相位相差180°的抑噪信號,
麥克風采集使用者的人聲語音指令,抑噪信號通過音響播放,會與噪音抵消,從而使麥克風捕捉到的音頻只有人聲。
本發明為音頻降噪和處理提供一種技術方案,通過對采集的音頻進行相位消除的方式來對目標音頻進行數字降噪,該技術方案能夠廣泛應用在智能家居領域,通過此技術手段,可以在復雜環境下將使用者的聲音(人聲)提取出來,進行進一步的語義分析,從而實現精準人機對話。
附圖說明
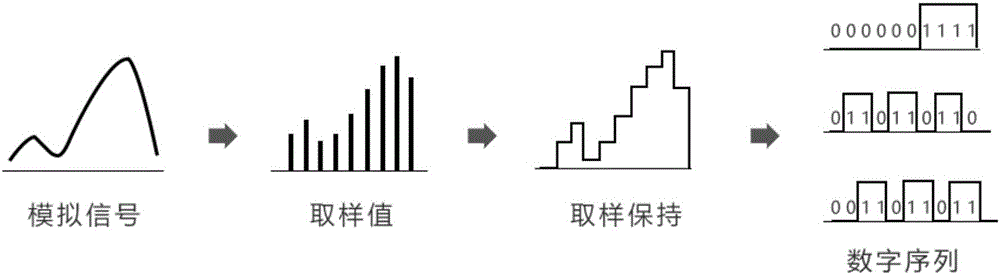
圖1本發明中模擬音頻信號轉換為數字序列示意圖。
圖2本發明中相位消除除噪示意圖。
圖3本發明實施例中音頻信號轉換為數值序列的示意圖。
具體實施方式
目前常用的數字音頻采樣率為48KHz,通常適用于miniDV、數字電視、DVD、DAT、電影和專業音頻領域,可滿足絕大部分需要。但對于音頻信號分析來說,還略有欠缺。當采集的音頻信號帶寬不到采樣頻率的一半(即奈奎斯特頻率),那么此時這些離散的采樣點能夠完全表示原信號。高于或處于奈奎斯特頻率的頻率分量會導致混疊現象,這將使不同聲音信號的分辨和處理工作變得非常困難。采樣頻率必須大于被采樣信號帶寬的兩倍,如果信號的帶寬是100Hz,那么為了避免混疊現象采樣頻率必須大于200Hz,也就是采樣頻率必須至少是信號中最大頻率分量頻率的兩倍,否則就不能從信號采樣中恢復原始信號。使用擁有96KHz或更高采樣率能力芯片能夠更好地將音頻信號進行還原,從而更好地還原采集到的音頻信號。
本發明通過使用超高采樣率的芯片,對音頻的采樣和處理,將抑噪音頻信號與源噪音信號進行相位消除,從而達到降噪效果,實現音源分離和提取的目的。
首先,由系統麥克風接收到噪音的模擬信號,通過采樣芯片(96KHz或更高)將模擬信號進行采樣,得出一系列在時間上離散的樣值,即樣值序列。對每個樣值進行離散化處理,將其轉換為有限個離散值,完成模擬信號到數字信號的轉變;噪音信號變為數字信號后,通過算法計算將數字信號轉換為數值序列,將該數值序列進行二次計算,獲得與該信號頻譜相同、相位相差180°的降噪信號的數字序列(抑噪信號),再使用算法將抑噪信號數字序列反向還原成模擬信號,將該抑噪信號與外置麥克風采集的音源的音頻信號混合,抑噪信號與噪音信號互相抵消,從而獲取到清晰、無干擾的語音指令。
- 還沒有人留言評論。精彩留言會獲得點贊!