一種語音識別的方法、終端及存儲介質與流程
本發明涉及終端領域,尤其涉及一種語音識別的方法、終端及存儲介質。
背景技術:
目前,隨著科學技術的發展,也帶動人類的物質生活極大豐富,智能終端也變得普及。
人們可以通過智能終端進行工作、娛樂以及游戲。具體的,目前存在一個場景,當兒童獨自一人時,容易發生突發狀況,而此時兒童又很難應對;此時,如何通過終端確定兒童的狀態并向家長進行告警顯得尤為重要。
技術實現要素:
本發明實施例公開了一種語音識別的方法及終端,將從兒童哭聲中提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否為目標兒童的聲紋;當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。通過本發明提供的技術方案,能夠及時確定兒童的狀態并向家長進行告警。
本發明實施例第一方面公開一種語音識別的方法,所述方法包括:
當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
本發明第二方面公開了一種終端,所述終端包括:
提取單元,用于當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
匹配單元,用于將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
告警單元,用于當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
本發明第三方面公開了一種終端,所述終端包括:
存儲有可執行程序代碼的存儲器;
與所述存儲器耦合的處理器;
所述處理器調用所述存儲器中存儲的所述可執行程序代碼,執行本發明第一方面中任一項所述的方法。
本發明第四方面公開了一種計算機可讀存儲介質,其存儲用于電子數據交換的計算機程序,其中,所述計算機程序使得計算機執行如本發明第一方面任一項所述的方法。
本發明第五方面公開了一種移動終端,所述移動終端包括通用處理器,所述通用處理器用于:
當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
與現有技術相比,本發明實施例具有以下有益效果:
本發明實施例中,將從兒童哭聲中提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。通過本發明提供的技術方案,能夠及時確定兒童的狀態并向家長進行告警。
附圖說明
為了更清楚地說明本發明實施例中的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明實施例公開的一種語音識別的方法的流程示意圖;
圖2是本發明實施例公開的另一種語音識別的方法的流程示意圖;
圖3是本發明實施例公開的另一種語音識別的方法的流程示意圖;
圖4是本發明實施例公開的一種用戶終端的結構示意圖;
圖5是本發明實施例公開的另一種用戶終端的結構示意圖;
圖6是本發明實施例公開的另一種用戶終端的結構示意圖;
圖7是本發明實施例公開的一種用戶終端的物理結構示意圖;
圖8是本發明實施例公開的另一種用戶終端的物理結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
本發明實施例公開了一種語音識別的方法及終端,能夠通過兒童的哭聲和聲紋模型及時確定兒童的狀態并向家長進行告警。
以下分別進行詳細說明。
請參閱圖1,圖1是本發明實施例公開的一種語音識別的方法的流程示意圖。該語音識別的方法可以包括以下步驟。
s101、當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
本發明實施例中,方法的執行主體是終端,該終端可以包括移動手機、平板電腦、個人數字助理(personaldigitalassistant,pda)、移動互聯網設備(mobileinternetdevice,mid)等各類終端,本發明實施例不作限定。
需要指出的是,可選的,終端對周圍環境中的聲音進行周期性檢測;對檢測到的聲音進行去噪;對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲。
具體的,對周圍環境中的聲音進行周期性檢測,其中,檢測的周期可以是終端默認的,也可以是用戶輸入的,還可以時根據終端電池的剩余電量確定的。
舉例來說,當終端剩余電量大于80%時,可以每個30s檢測一次,當終端剩余電量大于30%且小于80%時,每個兩分鐘檢測一次;當終端剩余電量小于30%時,可以每個10分鐘檢測一次。當終端電池的剩余電量小于10%時,可以停止該周期性檢測功能。
需要指出的是,該終端包括聲音傳感器,通過聲音傳感器獲取周圍的聲音。可選的,終端還可以通過麥克風進行聲音的收集。
s102、將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
具體的,所述將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋之前,所述方法還包括:獲取錄制的所述目標兒童的聲音;對所述獲取的聲音進行聲紋提取;利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型。其中,常見的預設機器學習算法包括分類算法、貝葉斯算法、監督學習算法等等。
可以理解的是,終端可以錄制兒童平時說話的聲音,然后從錄制的聲音中提取聲紋,利用機器學習算法對提取的聲紋進行訓練以獲取聲紋模型。
s103、當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
其中,需要指出的是,預設通信方式可以是語音、震動、文字提示等。
另外,可選的,所述通過預設通信方式向家長進行告警之后,所述方法還包括:
通過預設聲音對所述目標兒童進行原因問詢;接收所述目標兒童反饋的信息;對所述反饋的信息進行分析以確定事件類型;當所述事件類型為身體受傷時,根據所述目標兒童的位置確定預設范圍內救治中心的聯系方式,并通過所述聯系方式向所述救治中心進行告警。
具體的,預設聲音可以是模仿媽媽的聲音。比如提前錄制媽媽的聲音,然后模仿媽媽的音色確定詢問的語句,并將詢問的語句進行存儲。
兒童可以通過語音的方式進行信息反饋,還可以通過終端上的快捷鍵進行信息反饋。比如1快捷鍵表示摔倒了,2快捷鍵表示迷路了,3快捷鍵標識餓了,4快捷鍵標識受傷了等等。
可以理解的是,當事件類型為緊急類型時,通過衛星定位系統確定兒童當前的位置,并向監護人的終端發送該位置信息。常見的緊急類型是受傷、迷路等。
可選的,當所述事件類型為人事糾紛時,通過攝像頭對周圍環境進行拍攝;向安保服務器發送拍攝的圖片以及所述目標兒童的位置信息。
需要指出的是,常見的人事糾紛包括打架、辱罵等等。
可以理解的是,當所述事件類型為人事糾紛時,終端會主動啟動攝像頭以對周圍環境進行拍攝;并向安保服務器發送拍攝的圖片以及所述目標兒童的位置信息。其中,安保服務器可以是公安局的服務器。
從上可知,本發明實施例提供了一種技術方案,將從兒童哭聲中提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。通過本發明提供的技術方案,能夠及時確定兒童的狀態并向家長進行告警。
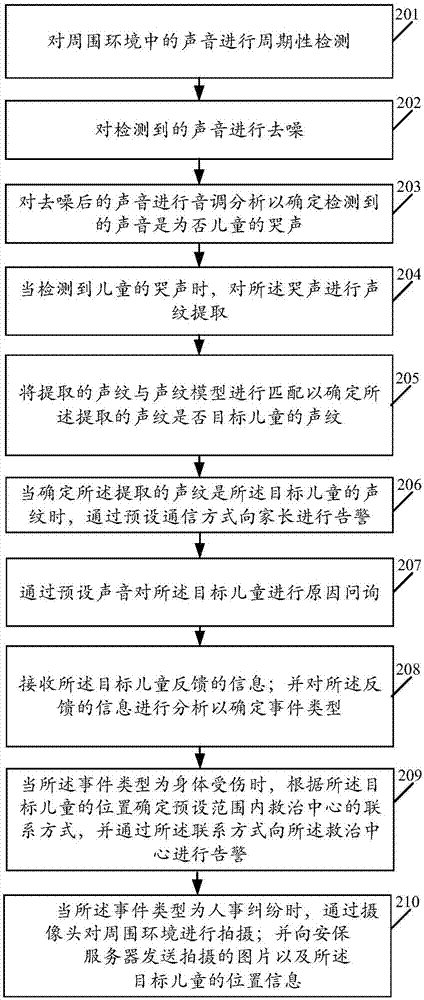
請參閱圖2,圖2是本發明實施例公開的一種語音識別的方法的流程示意圖。如圖2所示,該語音識別的方法可以包括以下步驟。
s201、對周圍環境中的聲音進行周期性檢測;
本發明實施例中,執行的主體可以是終端。終端可以包括移動手機、平板電腦、個人數字助理(personaldigitalassistant,pda)、移動互聯網設備(mobileinternetdevice,mid)等各類終端,本發明實施例不作限定。
s202、對檢測到的聲音進行去噪;
s203、對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲;
s204、當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
s205、將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
s206、當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警;
s207、通過預設聲音對所述目標兒童進行原因問詢;
s208、接收所述目標兒童反饋的信息;并對所述反饋的信息進行分析以確定事件類型;
s209、當所述事件類型為身體受傷時,根據所述目標兒童的位置確定預設范圍內救治中心的聯系方式,并通過所述聯系方式向所述救治中心進行告警。
s210、當所述事件類型為人事糾紛時,通過攝像頭對周圍環境進行拍攝;并向安保服務器發送拍攝的圖片以及所述目標兒童的位置信息。
在圖2所描述的方法中,通過預設聲音對所述目標兒童進行原因問詢;接收所述目標兒童反饋的信息;并對所述反饋的信息進行分析以確定事件類型;當所述事件類型為身體受傷時,根據所述目標兒童的位置確定預設范圍內救治中心的聯系方式,并通過所述聯系方式向所述救治中心進行告警。通過上述技術方案,能夠針對身體受傷的事件類型向救治中心進行告警,從而使得兒童能夠及時得到救治。
請參閱圖3,圖3是本發明實施例公開的一種語音識別的方法的流程示意圖。如圖3所示,該語音識別的方法可以包括以下步驟。
s301、獲取錄制的目標兒童的聲音;并對所述獲取的聲音進行聲紋提取;
本發明實施例中,執行的主體可以是終端。終端可以包括移動手機、平板電腦、個人數字助理(personaldigitalassistant,pda)、移動互聯網設備(mobileinternetdevice,mid)等各類終端,本發明實施例不作限定。
s302、利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型;
s303、對周圍環境中的聲音進行周期性檢測;
s304、對檢測到的聲音進行去噪;
s305、對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲;
s306、當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
s307、將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
s308、當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
在圖3所描述的方法中,能夠根據目標兒童的聲音和預設機器算法獲取聲紋模型,以使得終端根據檢測到的兒童聲音和聲紋模型確定是否是目標兒童在哭泣。通過本發明技術方案,能夠獲取聲紋模型以盡快識別檢測到的哭聲是否為目標兒童的哭聲。
請參閱圖4,圖4是本發明實施例公開的一種終端的結構示意圖。在圖4所描述的終端中,可以包括:
提取單元401,用于當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
匹配單元402,用于將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
告警單元403,用于當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
需要指出的是,圖4所示的結構可用于執行s101-s103所述的方法。
請一并參閱圖5,圖5是本發明實施例公開的另一種終端的結構示意圖。圖5所示的終端還可以包括:
檢測單元501,用于對周圍環境中的聲音進行周期性檢測;
去噪單元502,用于對檢測到的聲音進行去噪;
分析單元503,用于對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲;
提取單元504,用于當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
匹配單元505,用于將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
告警單元506,用于當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警;
詢問單元507,用于通過預設聲音對所述目標兒童進行原因問詢;
接收單元508,用于接收所述目標兒童反饋的信息;
分析單元503,用于對所述反饋的信息進行分析以確定事件類型;
確定單元509,用于當所述事件類型為身體受傷時,根據所述目標兒童的位置確定預設范圍內救治中心的聯系方式;
告警單元506,用于通過所述聯系方式向所述救治中心進行告警。
拍攝單元510,用于當所述事件類型為人事糾紛時,通過攝像頭對周圍環境進行拍攝;
發送單元511,用于向安保服務器發送拍攝的圖片以及所述目標兒童的位置信息。
可以理解的是,圖5所述的終端可用于執行s201-s210所示的方法。
請一并參閱圖6,圖6是本發明實施例公開的另一種用戶終端的結構示意圖。圖6所示的終端包括:
獲取單元601,用于獲取錄制的所述目標兒童的聲音;
提取單元602,用于對所述獲取的聲音進行聲紋提取;
訓練單元603,用于利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型;
檢測單元604,用于對周圍環境中的聲音進行周期性檢測;
去噪單元605,用于對檢測到的聲音進行去噪;
分析單元606,用于對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲;
提取單元602,用于當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
匹配單元607,用于將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
告警單元608,用于當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
可以理解的是,圖6所述的終端能夠執行s301-s308所述的方法。
請參閱圖7,圖7為本發明實施例公開的又一種終端的結構示意圖,如圖7所示,該終端可以包括:至少一個處理器710,例如cpu,存儲器720,至少一個通信總線730,輸入裝置740,輸出裝置750。其中,通信總線730用于實現這些組件之間的通信連接。存儲器720可以是高速ram存儲器,也可以是非不穩定的存儲器(non-volatilememory),例如至少一個磁盤存儲器。存儲器720可選的還可以是至少一個位于遠離前述處理器710的存儲裝置。其中,處理器710可以結合圖4至圖6所描述的終端,存儲器720中存儲一組程序代碼,且處理器710調用存儲器720中存儲的程序代碼,用于執行以下操作:
當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
可選的,所述操作還包括:
對周圍環境中的聲音進行周期性檢測;
對檢測到的聲音進行去噪;
對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲。
可選的,所述通過預設通信方式向家長進行告警之后,所述操作還包括:
通過預設聲音對所述目標兒童進行原因問詢;
接收所述目標兒童反饋的信息;
對所述反饋的信息進行分析以確定事件類型;
當所述事件類型為身體受傷時,根據所述目標兒童的位置確定預設范圍內救治中心的聯系方式,并通過所述聯系方式向所述救治中心進行告警。
可選的,所述操作還包括:
當所述事件類型為人事糾紛時,通過攝像頭對周圍環境進行拍攝;
向安保服務器發送拍攝的圖片以及所述目標兒童的位置信息。
可選的,所述將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋之前,所述操作還包括:
獲取錄制的所述目標兒童的聲音;
對所述獲取的聲音進行聲紋提取;
利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型。
本發明實施例中,將從兒童哭聲中提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。通過本發明提供的技術方案,能夠及時確定兒童的狀態并向家長進行告警。
請參閱圖8,圖8為本發明實施例公開的又一種移動終端的結構示意圖,如圖8所示,該移動終端可以包括:基帶處理大規模集成電路88(基帶處理lsi),通用處理器820,語音處理集成電路830(語音處理ic),觸摸控制器840,陀螺儀傳感器850,通信總線860,存儲器870。其中,通信總線860用于實現這些組件之間的通信連接。存儲器870可以是高速ram存儲器,也可以是非不穩定的存儲器(non-volatilememory),例如至少一個磁盤存儲器。其中,通用處理器820可以結合圖3至圖6所描述的終端,存儲器870中存儲一組程序代碼,且通用處理器820調用存儲器870中存儲的程序代碼,用于執行以下操作:
當檢測到兒童的哭聲時,對所述哭聲進行聲紋提取;
將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋;
當確定所述提取的聲紋是所述目標兒童的聲紋時,通過預設通信方式向家長進行告警。
可選的,所述操作還包括:
對周圍環境中的聲音進行周期性檢測;
對檢測到的聲音進行去噪;
對去噪后的聲音進行音調分析以確定檢測到的聲音是為否兒童的哭聲。
可選的,所述通過預設通信方式向家長進行告警之后,所述操作還包括:
通過預設聲音對所述目標兒童進行原因問詢;
接收所述目標兒童反饋的信息;
對所述反饋的信息進行分析以確定事件類型;
當所述事件類型為身體受傷時,根據所述目標兒童的位置確定預設范圍內救治中心的聯系方式,并通過所述聯系方式向所述救治中心進行告警。
可選的,所述操作還包括:
當所述事件類型為人事糾紛時,通過攝像頭對周圍環境進行拍攝;
向安保服務器發送拍攝的圖片以及所述目標兒童的位置信息。
可選的,所述將提取的聲紋與聲紋模型進行匹配以確定所述提取的聲紋是否目標兒童的聲紋之前,所述操作還包括:
獲取錄制的所述目標兒童的聲音;
對所述獲取的聲音進行聲紋提取;
利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型。
其中,可選的,所述通用處理器包括應用處理器和人工智能ai模塊,所述ai模塊集成于所述應用處理器設置,所述ai模塊用于:
獲取錄制的所述目標兒童的聲音;對所述獲取的聲音進行聲紋提取;利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型。
另外,可選的,所述通用處理器包括應用處理器和人工智能ai模塊,所述ai模塊獨立于所述處理器設置,所述ai模塊用于:
獲取錄制的所述目標兒童的聲音;對所述獲取的聲音進行聲紋提取;利用預設機器學習算法對提取的聲紋進行訓練以獲取所述目標兒童的聲紋模型。
進一步,需要指出的是,ai模塊的具體形式可以是硬件和/或軟件,ai模塊包括硬件形態時,處理器和ai模塊可以是集成設置,也可以是分離設置,此處不做限定。
在ai模塊集成與所述應用處理器集成設置時,若應用處理器為單核處理器,則ai模塊可以是應用處理器中的智能微處理電路,若應用處理器為多核處理器,則ai模塊可以是多核處理器中的單個智能微處理器內核或者某一個微處理器內核中的智能微處理電路。
在ai模塊集成與所述應用處理器分離設置時,ai模塊可以是應用處理器平臺架構中除所述應用處理器之外的任意一個協處理器(如基帶處理器等),或者,可以是應用處理器平臺架構中除所述應用處理器之外的一個新設置的智能微處理器,或者,可以是新設置的獨立于所述應用處理器平臺的智能處理平臺,且該智能處理平臺至少包括一個專用智能處理器,該智能處理平臺與應用處理器平臺通信連接,可選的,智能處理平臺還可以與存儲器、外設等直連通信連接。
本領域普通技術人員可以理解上述實施例的各種方法中的全部或部分步驟是可以通過程序來指令相關的硬件來完成,該程序可以存儲于一計算機可讀存儲介質中,存儲介質包括只讀存儲器(read-onlymemory,rom)、隨機存儲器(randomaccessmemory,ram)、可編程只讀存儲器(programmableread-onlymemory,prom)、可擦除可編程只讀存儲器(erasableprogrammablereadonlymemory,eprom)、一次可編程只讀存儲器(one-timeprogrammableread-onlymemory,otprom)、電子抹除式可復寫只讀存儲器(electrically-erasableprogrammableread-onlymemory,eeprom)、只讀光盤(compactdiscread-onlymemory,cd-rom)或其他光盤存儲器、磁盤存儲器、磁帶存儲器、或者能夠用于攜帶或存儲數據的計算機可讀的任何其他介質。
以上對本發明實施例公開的一種基于圖像的解鎖屏方法及用戶終端進行了詳細介紹,本文中應用了具體個例對本發明的原理及實施方式進行了闡述,以上實施例的說明只是用于幫助理解本發明的方法及其核心思想;同時,對于本領域的一般技術人員,依據本發明的思想,在具體實施方式及應用范圍上均會有改變之處,綜上所述,本說明書內容不應理解為對本發明的限制。
- 還沒有人留言評論。精彩留言會獲得點贊!