抗病毒細胞及其用途的制作方法
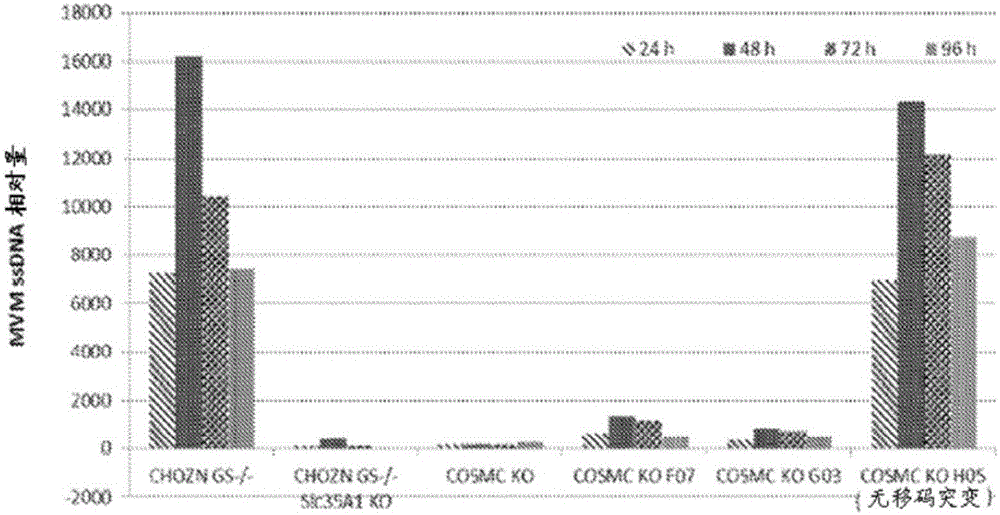
本發明涉及經工程改造而具有抗病毒性的哺乳動物細胞系和所述細胞系用于減少或防止生物生產系統的病毒污染的用途。背景重組產生的治療性蛋白質用于治療許多疾病或病狀(諸如癌癥和自身免疫性疾病)的用途不斷增加。然而,這些蛋白質治療劑的大規模生產仍然是一個挑戰。舉例來說,工業制造過程中必須實現可靠高收率,使得下游工藝產生極純的產物,只允許痕量污染物至優選地無污染物。使用無動物成分的培養基已經顯著地降低了外來病毒污染的發生率。另外,諸如超濾、高溫短時間處理和/或對散裝材料進行UVC照射之類的程序的實施進一步降低了污染的發生率。然而,病毒污染的風險仍然存在。就產品損失、暫時退出市場和昂貴的去污成本而言,污染事件對制造商將是災難性的。因此,需要對病毒感染具有增加的抗性的哺乳動物細胞系。附圖簡述圖1呈現了如通過Southern印跡分析所測定的MVM病毒感染的時間過程。利用在24、48、72和96小時針對野生型細胞(CHOZNGS-/-)、Slc35A1KO、COSMCKO、COSMCKO克隆F07、COSMCKO克隆G03和COSMCKO克隆H05所檢測的MVM病毒DNA的相對量進行作圖。克隆H05具有12bp的框內缺失(即,無移碼突變)。圖2示出了如通過空斑測定所檢測的MVM病毒感染的時間過程。作圖的是在24、48、72和96小時針對野生型細胞(CHOZN)、Slc.35A1KO、COSMCKO、COSMCKO克隆F07、COSMCKO克隆G03和COSMCKO克隆H05所檢測的pfu/mL。圖3示出了MMV感染對細胞生長的影響。作圖的是野生型(2E3)(A)和COSMCKO克隆F07(B)細胞在MVM病毒不存在(實線)和以MOI1或8存在(斷線)的情況下在120小時過程中的活細胞數目(細胞/ml)。圖4呈現了MMV感染后的細胞相關病毒的時間過程。作圖的是每個細胞的MVM病毒基因組拷貝數(vgc)(基于假定每一個已感染的細胞可以產生2x104vgc),如在MVM病毒以MOI1(A)或8(B)存在的情況下通過qPCR在120小時的過程中針對野生型(2E3)(實現)和COSMCKO克隆F07(斷線)細胞所檢測。圖5示出了在指示的細胞系中的MMV復制的時間過程。作圖的是用MVM病毒以MOI0.3(A)或0.03(B)感染后0和21小時的vgc/樣品。圖6呈現了所指示的細胞系中的呼腸孤病毒3復制的時間過程。作圖的是在感染Reo-3病毒后0和24小時與野生型細胞(2E3)相關的vgc/樣品。.圖7呈現了在MVM病毒不存在(UN)或存在(IN)的情況下針對細胞生長進行的生長測定。圖A呈現了野生型(GS)、Slc35A1KO、COSMCKO克隆F07和COSMCKO克隆G03在10天內的活細胞密度(VCD)。圖B呈現了野生型(GS)、來源于COSMCKO克隆F07的IgG產生克隆71H1和71C3在8天內的VCD。圖8呈現了在MVM病毒不存在(UN)或存在(IN)的情況下針對細胞生長進行的生長測定。作圖的是野生型(GS)、St3Gal4KO克隆7D10、St3Gal4KO克隆1B08和St3Gal4KO克隆1B10在9天內的VCD。概要在本公開的各種方面中,提供了經工程改造以阻礙或防止細胞中的病毒進入和/或病毒繁殖的哺乳動物細胞系。在一些實施方案中,所述哺乳動物細胞系經過基因修飾,使得與未經修飾的親本細胞系相比,至少一種病毒的進入和/或繁殖被減少或消除。在各種實施方案中,本文中所公開的哺乳動物細胞系包含至少一個經修飾的染色體序列。在其他實施方案中,所述經修飾的染色體序列是失活的,使得所述細胞系不產生或產生降低水平的編碼蛋白質產物。在一個實施方案中,所述細胞系包含至少一個編碼核心1酶伴侶(COSMC)的失活染色體序列。在另一個實施方案中,編碼COSMC的染色體序列的所有拷貝都是失活的且所述細胞系不產生COSMC。在一個替代實施方案中,所述細胞系包含至少一個編碼溶質載體家族35(CMP-唾液酸轉運體)成員A1(Slc35A1)的失活染色體序列。在另一個實施方案中,編碼Slc35A1的染色體序列的所有拷貝都是失活的且所述細胞系不產生Slc35A1。在又另一個實施方案中,所述細胞系包含至少一個編碼核心1伸長酶(C1GalT1)的失活染色體序列。在另一個實施方案中,編碼C1GalT1的染色體序列的所有拷貝都是失活的且所述細胞系不產生C1GalT1。在另一個實施方案中,所述細胞系包含至少一個編碼St3β-半乳糖苷α-2,3-唾液酸轉移酶1(St3Gal1)的失活染色體序列。在另一個實施方案中,編碼St3Gal1的染色體序列的所有拷貝都是失活的且所述細胞系不產生St3Gal1。在一個替代實施方案中,所述細胞系包含至少一個編碼St3β-半乳糖苷α-2,3-唾液酸轉移酶2(St3Gal2)的失活染色體序列。在另一個實施方案中,編碼St3Gal2的染色體序列的所有拷貝都是失活的且所述細胞系不產生St3Gal2。在又另一個實施方案中,所述細胞系包含至少一個編碼St3β-半乳糖苷α-2,3-唾液酸轉移酶3(St3Gal3)的失活染色體序列。在另一個實施方案中,編碼St3Gal3的染色體序列的所有拷貝都是失活的且所述細胞系不產生St3Gal3。在又另一個實施方案中,所述細胞系包含至少一個編碼St3β-半乳糖苷α-2,3-唾液酸轉移酶4(St3Gal4)的失活染色體序列。在另一個實施方案中,編碼St3Gal4的染色體序列的所有拷貝都是失活的且所述細胞系不產生St3Gal4。在一個替代實施方案中,所述細胞系包含至少一個編碼St3β-半乳糖苷α-2,3-唾液酸轉移酶5(St3Gal5)的失活染色體序列。在另一個實施方案中,編碼St3Gal5的染色體序列的所有拷貝都是失活的且所述細胞系不產生St3Gal5。在又另一個實施方案中,所述細胞系包含至少一個編碼St3β-半乳糖苷α-2,3-唾液酸轉移酶6(St3Gal6)的失活染色體序列。在另一個實施方案中,編碼St3Gal6的染色體序列的所有拷貝都是失活的且所述細胞系不產生St3Gal6。在一個替代實施方案中,所述細胞系包含編碼St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和St3Gal6中的任兩者的失活染色體序列。在又一個替代實施方案中,所述細胞系包含編碼St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和St3Gal6中的任兩者的失活染色體序列。在其他實施方案中,包含編碼COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色體序列的細胞系還包含編碼甘露糖基(α-1,3-)-糖蛋白β-1,2-N-乙酰葡糖胺基轉移酶1(Mgat1)、甘露糖基(α-1,6-)-糖蛋白β-1,2-N-乙酰葡糖胺基轉移酶2(Mgat2)、甘露糖基(α-1,4-)-糖蛋白β-1,4-N-乙酰葡糖胺基轉移酶3(Mgat3)、甘露糖基(α-1,3-)-糖蛋白β-1,4-N-乙酰葡糖胺基轉移酶4(Mgat4)和/或甘露糖基(α-1,6-)-糖蛋白β-1,6-N-乙酰葡糖胺基轉移酶5(Mgat5)的失活染色體序列。本文中所公開的包含經修飾的染色體序列的哺乳動物細胞系與未經修飾的親本細胞系相比對病毒進入和/或病毒繁殖具有增加的抗性。在又其他實施方案中,包含編碼St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色體序列的細胞系經過進一步工程改造以過度表達至少一種負責產生2,6-鍵聯的唾液酸轉移酶(例如,St6β-半乳糖酰胺α-2,6-唾液酸轉移酶1(St6Gal1)、St6β-半乳糖酰胺α-2,6-唾液酸轉移酶2(St6Gal2)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺1(St6GalNac1)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺2(St6GalNac2)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺3(St6GalNac3)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺4(ST6GalNac4)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺5(St6GalNac5)和/或St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺6(St6GalNac6)。在一些實施方案中,所述哺乳動物細胞系是非人細胞系。在其他實施方案中,所述哺乳動物細胞系是中國倉鼠卵巢(CHO)細胞系。在諸多具體實施方案中,所述細胞系是包含編碼COSMC、Slc35A1、C1GalT1、St3Gall、St3Gal2、St3Gal3、St3Gal4、St3Gal5、St3Gal6或其組合的滅活染色體序列的CHO細胞系。在某些實施方案中,本文中所公開的哺乳動物細胞系對選自細小病毒、呼腸孤病毒、輪狀病毒、流感病毒、腺相關病毒、杯狀病毒、副流感病毒、風疹病毒、冠狀病毒、諾羅病毒、腦心肌炎病毒、多瘤病毒或其組合的病毒的進入和/或繁殖表現出抗性。在一些實施方案中,所述細小病毒是小鼠微小病毒(MVM)、1型小鼠細小病毒、2型小鼠細小病毒、3型小鼠細小病毒、豬細小病毒1、牛細小病毒1、人細小病毒B19、人細小病毒4、人細小病毒5或其組合。在另外的實施方案中,所述呼腸孤病毒是哺乳動物呼腸孤病毒3、哺乳動物正呼腸孤病毒、禽正呼腸孤病毒或其組合。在各種實施方案中,本文中所公開的哺乳動物細胞系是通過使用靶向核酸內切酶介導的基因組修飾技術來修飾至少一個染色體序列而制得。所述靶向核酸內切酶可以是鋅指核酸酶、CRISPR/Cas核酸內切酶、轉錄活化因子樣效應因子(TALE)核酸酶、大范圍核酸酶、位點特異性核酸內切酶或人工靶向DNA雙鏈斷裂誘導劑。在諸多具體實施方案中,所述靶向核酸內切酶是一對鋅指核酸酶。在一些實施方案中,本文中所公開的哺乳動物細胞系還包含至少一種編碼選自抗體、抗體片段、疫苗、生長因子、細胞因子、激素、凝血因子或另一種治療蛋白質的重組蛋白的核酸。本公開的另一個方面涵蓋一種減少或防止重組蛋白產物的病毒污染的方法,所述方法包括:獲得如本文中所公開的抗病毒哺乳動物細胞系,并且在所述細胞系中表達重組蛋白產物。本公開的另一個方面提供一種減小生物生產系統的病毒污染的風險的方法,其中所述方法包括提供如本文中所公開的抗病毒哺乳動物細胞系以用于所述生物生產系統中。本公開的又另一個方面涵蓋一種組合物,其包含如本文中所公開的抗病毒哺乳動物細胞系和至少一種病毒,其中所述細胞系表現出了對由所述至少一種病毒所致的感染的抗性。以下更詳細地描述本公開的其他方面和迭代。詳細說明本公開提供了經工程改造以阻礙或防止細胞系中的病毒進入和/或病毒繁殖的哺乳動物細胞系。具有抗病毒性的經工程改造的細胞系可以經過基因修飾以含有經修飾的(例如,滅活的)染色體序列。還提供了使用本文中所公開的細胞系產生重組蛋白的方法,其中該重組蛋白產物基本上沒受到病毒污染。因此,使用對病毒感染具有抗性的細胞系能減小或消除生物生產系統和所得蛋白質產物的病毒污染的風險。(I)抗病毒細胞系本公開的一個方面涵蓋經工程改造以具有病毒抗性的哺乳動物細胞系。換句話說,與未經修飾的親本細胞系相比,本文中所公開的細胞系對由至少一種病毒所致的感染具有增加的抗性。更具體來說,與未經修飾的親本細胞系相比,在本文中所公開的經工程改造的細胞系中,病毒進入和/或病毒繁殖被減少或消除。在一些實施方案中,該哺乳動物細胞系經過基因修飾并且含有至少一個經修飾的染色體序列。一般來說,該經修飾的序列包含突變。在諸多具體實施方案中,該經修飾的染色體序列是失活的(或被敲除),使得該細胞系不產生編碼蛋白產物。一般來說,對病毒感染的抗性(或敏感性)可以通過比較經工程改造的哺乳動物細胞系對暴露于病毒的反應與未經修飾的(未經工程改造的)親本細胞對相同病毒攻擊的反應來確定。細胞系的病毒感染和/或細胞系中的病毒繁殖可以通過多種技術加以分析。合適的技術的非限制性實例包括核酸檢測法(例如,用于檢測具體病毒核酸的存在的南方核酸印跡測定、用于檢測病毒核酸的PCR或RT-PCR、測序法等等)、基于抗體的技術(例如,使用抗病毒蛋白質抗體的西方免疫印跡技術、ELISA法,諸如此類)、生物測定(例如,斑點測定、細胞病變效應測定等等)和顯微鏡技術(例如,用于檢測病毒顆粒的電子顯微鏡檢查等)。在一些實施方案中,相對于未經修飾的親本細胞,經工程改造的哺乳動物細胞系內的病毒感染和/或繁殖可以減少至少約10%、至少約20%、至少約40%、至少約60%、至少約80%、至少約90%、至少約99%或超過約99%。在諸多具體實施方案中,經工程改造的哺乳動物細胞系對病毒感染具有抗性,即,病毒不能進入和/或在該經工程改造的哺乳動物細胞系中繁殖。本文中所公開的哺乳動物細胞系可以用多種不同的方式加以工程改造以賦予病毒抗性。在一些實施方案中,該細胞系可以經過修飾,以使得通過細胞表面受體的病毒進入被減少或消除。在其他實施方案中,該細胞系可以經過工程改造以表達能抑制或阻斷涉及復制和/或感染性的特定病毒蛋白的分子。在又其他實施方案中,該細胞系可以經過工程改造以過度表達特定細胞抗病毒蛋白。在一些實施方案中,該工程改造可以是基因工程改造,其中基因組或染色體序列經過修飾。換句話說,該細胞系經過基因修飾。在其他實施方案中,該工程改造可以是表觀基因工程改造或染色體外工程改造。(a)抗病毒機制(i)擾亂細胞表面受體在某些實施方案中,該哺乳動物細胞系經過工程改造以含有經改變的細胞表面受體。病毒可以通過特異性附著于細胞表面上的互補受體而進入細胞。對于許多病毒來說,這些細胞表面受體包含與蛋白質(或脂質)連接的聚糖結構。唾液酸或其衍生物中的封端聚糖充當許多病毒的受體(Matrosovich等,2013,TopCurrChem,DOI:10.1007/128_2013_466)。因此,包含具有末端唾液酸殘基的O連接型或N連接型聚糖的糖蛋白可以充當許多病毒的細胞表面受體。唾液酸是指神經氨酸的衍生物,并且包括例如N-乙酰基神經氨酸(Neu5Ac或NANA)和N-羥乙酰基神經氨酸(Neu5Gc或NGNA)。在一些實施方案中,該細胞系經過工程改造以包含缺乏末端唾液酸殘基的糖蛋白。末端唾液酸殘基可以通過缺失(即,敲除)或改變涉及聚糖鏈合成的酶和/或蛋白質而得以消除。合適的靶標包括涉及O連接型聚糖的合成的酶或蛋白質、涉及N連接型聚糖的合成的酶或蛋白質和/或涉及唾液酸的合成或轉運的酶或蛋白質。在某些實施方案中,該細胞系可能缺乏以上提到的靶向酶或蛋白質中的至少一種(或以上提到的靶標的任何組合)。如本文中所使用,“缺乏”是指靶向酶或蛋白質的水平有所降低或不可檢測,或者靶向酶或蛋白質的活性有所降低或不可檢測。靶向酶或蛋白質的量或活性可以通過修飾至少一個編碼靶向蛋白質或酶的染色體序列而被減少或消除。舉例來說,染色體序列可以經過修飾以含有至少一個核苷酸的缺失、至少一個核苷酸的插入、至少一個核苷酸的取代或其組合。因此,缺失、插入和/或取代可以移動染色體序列的閱讀框,以致不產生蛋白質產物(即,染色體序列是失活的)。或者,經修飾的染色體序列中的缺失、插入和/或取代可能導致產生改變的蛋白質產物。對感興趣的染色體序列的修飾可以使用以下部分(III)(a)中詳述的靶向核酸內切酶介導的基因組編輯技術來實現。在編碼靶向酶或蛋白質的一個染色體序列失活的情況下,經工程改造的細胞系產生較低水平的靶向酶或蛋白質。在編碼靶向酶或蛋白質的染色體序列的所有拷貝都失活的其他情況下,經工程改造的細胞系不產生靶向酶或蛋白質(即,該細胞系是敲除或KO)。在又其他實施方案中,靶向酶或蛋白質的水平可以使用以下部分(III)(b)中詳述的RNA干擾介導的機制來減少或消除。在一些實施方案中,靶向酶或蛋白質的水平可以降低至少約5%、約5%至10%、約10%至20%、約20%至30%、約30%至40%、約40%至50%、約50%至60%、約60%至70%、約70%至80%、約80%至90%或約90%至約100%。在其他實施方案中,靶向酶或蛋白質的水平可以降至使用本領域中的標準技術(例如,西方免疫印跡測定、ELISA酶測定等等)不可檢測的水平。在一些實施方案中,該細胞系可能缺乏涉及O連接型糖基化的酶或蛋白質。舉例來說,該細胞系可能缺乏核心1伸長酶(也稱為核心1合成酶糖蛋白-N-乙酰基半乳糖酰胺3-β-半乳糖苷轉移酶1或C1GalT1)、核心1酶侶伴蛋白(也稱為C1GalT1特異性侶伴蛋白或COSMC)或兩者。COSMC促進C1GalT1的折疊、穩定性和活性,由此催化半乳糖殘基轉移至O-連接于蛋白質的絲氨酸或蘇氨酸的N-乙酰基半乳糖酰胺(GalNAc)殘基。在諸多具體實施方案中,該細胞系缺乏C1GalT1、COSMC或兩者。該缺乏可能是由于編碼C1GalT1和/或COSMC的失活染色體序列所致,從而產生了較低水平的C1GalT1和/或COSMC蛋白質或不產生C1GalT1和/或COSMC蛋白質。在一些情況下,至少一個編碼C1GalT1和/或COSMC的染色體序列是失活的。在其他情況下,編碼C1GalT1和/或COSMC的染色體序列的所有拷貝都是失活,導致該細胞系缺乏C1GalT1蛋白和/或COSMC蛋白。在其他實施方案中,該細胞系可能缺乏至少一種唾液酸轉移酶(ST)。該唾液酸轉移酶可以是將唾液酸添加至呈α-2,3鍵聯構象的半乳糖的唾液酸轉移酶、將唾液酸添加至呈α-2,6鍵聯構象的半乳糖或N-乙酰半乳糖酰胺的唾液酸轉移酶或將唾液酸添加至呈α-2,8鍵聯構象的其他唾液酸單元的唾液酸轉移酶。合適的唾液酸轉移酶的非限制性實例包括St3β-半乳糖苷α-2,3-唾液酸轉移酶1(St3Gal1)、St3β-半乳糖苷α-2,3-唾液酸轉移酶2(St3Gal2)、St3β-半乳糖苷α-2,3-唾液酸轉移酶3(St3Gal3)、St3β-半乳糖苷α-2,3-唾液酸轉移酶4(St3Gal4)、St3β-半乳糖苷α-2,3-唾液酸轉移酶5(St3Gal5)、St3β-半乳糖苷α-2,3-唾液酸轉移酶6(St3Gal6)、St6β-半乳糖苷α-2,6-唾液酸轉移酶1(St6Gal1)、St6β-半乳糖苷α-2,6-唾液酸轉移酶2(St6Gal2)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺1(St6GalNac1)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺2(St6GalNac2)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺3(St6GalNac3)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺4(ST6GalNac4)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺5(St6GalNac5)、St6(α-N-乙酰基-神經氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺6(St6GalNac6)、St8α-N-乙酰基-神經氨酸苷α-2,8-唾液酸轉移酶1(St8Sia1)、St8α-N-乙酰基-神經氨酸苷α-2,8-唾液酸轉移酶2(St8Sia2)、St8α-N-乙酰基-神經氨酸苷α-2,8-唾液酸轉移酶3(St8Sia3)、St8α-N-乙酰基-神經氨酸苷α-2,8-唾液酸轉移酶4(St8Sia4)、St8α-N-乙酰基-神經氨酸苷α-2,8-唾液酸轉移酶5(St8Sia5)或St8α-N-乙酰基-神經氨酸苷α-2,8-唾液酸轉移酶6(St8Sia6)。在諸多具體實施方案中,該細胞系可能缺乏至少一種α-2,3-唾液酸轉移酶(例如,St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6)。該缺乏可能是由于編碼至少一種α-2,3-唾液酸轉移酶的失活染色體序列所致,從而產生了較低水平的該至少一種α-2,3-唾液酸轉移酶或不產生該α-2,3-唾液酸轉移酶。在一些情況下,編碼該至少一種α-2,3-唾液酸轉移酶的至少一個染色體序列可以是失活的。在其他情況下,編碼該至少一種α-2,3-唾液酸轉移酶的染色體序列的所有拷貝都可以是失活的,使得該細胞系缺乏該至少一種α-2,3-唾液酸轉移酶。換句話說,編碼St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的染色體序列可能被敲除。在該細胞系包含編碼至少一種α-2,3-唾液酸轉移酶(例如,St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6)的至少一個失活染色體序列的一些情況下,該細胞系可以經過進一步工程改造以過度表達至少一種負責產生2,6-鍵聯的唾液酸轉移酶(例如,St6Gal1、St6Gal2、St6GalNac1、St6GalNac2、St6GalNac3、ST6GalNac4、St6GalNac5和/或St6GalNac6)。因此,這類細胞系可以包含具有減少數目的(或沒有)末端2,3連接型唾液酸殘基和增加數目的末端2,6連接型唾液酸殘基的糖蛋白。在其他實施方案中,該細胞系可能缺乏至少一種涉及唾液酸合成或轉運的酶或蛋白質。涉及唾液酸合成或轉運的酶或蛋白質的實例包括但不限于葡糖胺(UDP-N-乙酰基)-2-表異構酶/N-乙酰甘露糖胺激酶(GNE)、N-乙酰神經氨酸合成酶(NANS)、N-乙酰神經氨酸磷酸酶(NANP)、單磷酸胞苷N-乙酰神經氨酸合成酶(CMAS)和單磷酸胞苷N-乙酰神經氨酸羥化酶(CMAH)、溶質載體家族35(CMP-唾液酸轉運體)成員A1(Slc35A1)。在某些實施方案中,該細胞系可能缺乏將CMP-唾液酸轉運至高爾基體中的Slc35A1。在一些情況下,編碼Slc35A1的至少一個染色體序列可以是失活的。在其他情況下,編碼Slc35A1的染色體序列的所有拷貝都可以是失活的,使得該細胞是缺乏Slc35A1蛋白。在另外的實施方案中,該細胞系可能缺乏涉及N-糖基化的至少一種酶或蛋白質。在一些情況下,涉及N-糖基化的酶或蛋白質可以是N-乙酰葡糖胺基轉移酶,其給N連接型聚糖的β-連接型甘露糖殘基增加了GlcNAc殘基。實例包括甘露糖基(α-1,3-)-糖蛋白β-1,2-N-乙酰葡糖胺基轉移酶1(Mgat-1)、甘露糖基(α-1,6-)-糖蛋白β-1,2-N-乙酰葡糖胺基轉移酶2(Mgat-2)、甘露糖基(α-1,4-)-糖蛋白β-1,4-N-乙酰葡糖胺基轉移酶3(Mgat-3)、甘露糖基(α-1,3-)-糖蛋白β-1,4-N-乙酰葡糖胺基轉移酶4(Mgat-4)和甘露糖基(α-1,6-)-糖蛋白β-1,6-N-乙酰葡糖胺基轉移酶5(Mgat-5)。在其他情況下,涉及N-糖基化的酶或蛋白質可以是半乳糖轉移酶,其給N連接型聚糖的GlcNAc殘基增加了處于β-1,4鍵聯中的半乳糖殘基。半乳糖轉移酶可以是UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽1(B4GalT1)、UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽2(B4GalT2)、UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽3(B4GalT3)、UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽4(B4GalT4)、UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽5(B4GalT5)、UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽6(B4GalT6)或UDP-Gal:βGlcNAcβ1,4-半乳糖轉移酶多肽7(B4GalT7)。在某些情況下,該細胞系可能缺乏至少一種N-乙酰葡糖胺基轉移酶和/或半乳糖轉移酶。在一些迭代中,編碼至少一種N-乙酰葡糖胺基轉移酶和/或半乳糖轉移酶的至少一個染色體序列可以是失活的。在其他情況下,編碼該至少一種N-乙酰葡糖胺基轉移酶和/或半乳糖轉移酶的染色體序列的所有拷貝都可以是失活的,使得該細胞系缺乏該至少一種N-乙酰葡糖胺基轉移酶和/或半乳糖轉移酶。(ii)干擾病毒蛋白質在其他實施方案中,該哺乳動物細胞系可以經過工程改造以表達能抑制或阻斷病毒復制和/或感染性的分子。舉例來說,該細胞系可以經過工程改造以穩定地表達至少一種針對涉及復制和/或感染性的特定病毒蛋白質的RNA干擾(RNAi)劑。合適的病毒蛋白質的非限制性實例包括非結構蛋白質,諸如NS1或NS2,和殼體蛋白質,諸如VP1或VP2。RNAi劑結合靶轉錄物且通過介導轉錄物裂解的裂解或破壞轉錄物的翻譯而防止蛋白質表達。在一些實施方案中,RNAi劑可以是短干擾RNA(siRNA)。一般來說,siRNA包含介于約15至約29個核苷酸長,或更一般來說,約19至約23個核苷酸長的范圍內的雙鏈RNA分子。在諸多具體實施方案中,該siRNA可以是約21個核苷酸長。該siRNA可以任選地進一步包含一個或兩個單鏈懸突,例如在一端或兩端上的3′懸突。該siRNA可以由雜交在一起的兩個RNA分子形成,或替代地,可以由短發夾RNA(shRNA)生成(見下文)。在一些實施方案中,該siRNA的兩個鏈可以是完全互補的,使得兩個序列之間所形成的雙鏈體中不存在錯配或隆凸。在其他實施方案中,該siRNA的兩個鏈可以是基本上互補的,使得兩個序列之間所形成的雙鏈體中存在一個或多個錯配和/或隆凸。在某些實施方案中,該siRNA的5′端中的一個或兩個可以具有磷酸酯基,而在其他實施方案中,該5′端中的一個或兩個可以缺乏磷酸酯基。該siRNA中被稱為“反義鏈”或“引導鏈”的一個鏈包括能與靶轉錄物雜交的部分。在一些實施方案中,該siRNA的反義股可以與靶轉錄物的一個區域完全互補,即,其在整個siRNA長度上不存在單個錯配或隆凸的情況下與靶轉錄物雜交。在其他實施方案中,該反義股可以與靶區域基本上互補,即,由該反義股和該靶轉錄物形成的雙鏈體中可以存在一個或多個錯配和/或隆凸。典型地,使siRNA靶向靶轉錄物的外顯子序列。本領域技術人員應熟悉設計針對靶轉錄物的siRNA的程序、算法和/或商業服務。在其他實施方案中,RNAi劑可以是短發夾RNA(shRNA)。一般來說,shRNA是包含可雜交或能夠雜交以形成長度足以介導RNA干擾(如以上所描述)的雙鏈結構的至少兩個互補部分和形成了連接形成該雙鏈體的shRNA區域的環的至少一個單鏈部分的RNA分子。該結構還可以稱為莖-環結構,其中該莖是雙鏈體部分。在一些實施方案中,該結構的雙鏈體部分可以是完全互補的,使得shRNA的雙鏈體區域中不存在錯配或隆凸。在其他實施方案中,該結構的雙鏈體部分可以是基本上互補的,使得shRNA的雙鏈體部分中可以存在一個或多個錯配和/或隆凸。該結構的環可以是約1至約20個核苷酸長,具體來說是約6至約9個核苷酸長。該環可以位于與靶轉錄物互補的區域(即,shRNA的反義部分)的5′或3′端。該shRNA可以進一步包含處于5′或3′端上的懸突。該可選懸突可以是約1至約20個核苷酸長,或更具體來說是約2至約15個核苷酸長。在一些實施方案中,該懸突可以包含一個或多個U殘基,例如介于約1個與約5個之間的U殘基。在一些實施方案中,該shRNA的5′端可以具有磷酸酯基。一般來說,通過保守細胞RNAi機制將shRNA處理成siRNA。因此,shRNA是siRNA的前驅物,并且類似地能夠抑制與shRNA的一部分(即,shRNA的反義部分)互補的靶轉錄物的表達。本領域技術人員應熟悉用于設計和合成shRNA的可用資源。一個示例性實例是shRNA(Sigma-Aldrich)。可以在活體內由RNAi表達構建體表達siRNA或shRNA。合適的構建體包括質粒載體、噬菌粒、粘粒、人工/微型染色體、轉座子和病毒載體(例如,慢病毒載體、腺相關病毒載體等)。在一個實施方案中,該RNAi表達構建體可以是質粒載體(例如,pUC、pBR322、pET、pBluescript及其變體)。該RNAi表達構建體可以包含兩個啟動子控制序列,其中每一個可操作地連接適當的編碼序列,使得兩個獨立的互補siRNA鏈可以被轉錄。該兩個啟動子控制序列可以呈相同的取向或相反的取向。在另一個實施方案中,該RNAi表達載體可以含有驅動包含兩個互補區域的單個RNA分子的轉錄,從而使得轉錄物形成shRNA的啟動子控制序列。一般來說,啟動子控制序列將是RNA聚合酶III(PolIII)啟動子,諸如U6或H1啟動子。在其他實施方案中,可以使用RNA聚合酶II(PolII)啟動子控制序列(以下給出了一些實例)。RNAi表達構建體可以含有額外的序列元件,諸如轉錄終止序列、可選標記序列等。可以使用標準程序將RNAi表達構建體引入感興趣的細胞系中。可以將RNAi表達構建體染色體整合在該細胞系中以便穩定表達。或者,在該細胞系中,RNAi表達構建體可以在染色體外(例如,附加型)以便穩定表達。在又其他實施方案中,該細胞系可以經過工程改造以穩定地表達涉及復制和/或感染性的病毒蛋白質的顯性陰性形式。使蛋白質的顯性陰性形式發生改變或突變,以使其勝過或抑制野生型蛋白質。合適的蛋白質的非限制性實例包括病毒非結構蛋白質,諸如NS1或NS2,和病毒殼體蛋白,諸如VP1或VP2。在諸多具體實施方案中,該細胞系可以經過工程改造以表達一種或多種NS1蛋白的顯性陰性形式。相對于野生型蛋白質,顯性陰性蛋白質可以具有缺失、插入和/或取代(Lagna等,1998,Curr.TopicsDev.Biol,36:75-98)。缺失、插入和/或取代可以在蛋白質的N末端、C末端或內部位置。用于生成突變蛋白質的手段(通過定點誘變、基于PCR的誘變、隨機誘變等)在本領域中是眾所周知的,如同用于鑒定具有顯性負面作用的那些的手段。可用包含編碼顯性陰性蛋白質的序列的表達構建體(見上文)來轉染細胞系,其中該編碼序列可操作地連接于PolII啟動子控制序列以便表達。啟動子控制序列可以是組成性的、調節型的或組織特異性的。合適的組成性啟動子控制序列包括但不限于巨細胞病毒立即早期啟動子(CMV)、猿猴病毒(SV40)啟動子、腺病毒主要晚期啟動子、勞斯肉瘤病毒(RSV)啟動子、小鼠乳腺腫瘤病毒(MMTV)啟動子、磷酸甘油酸激酶(PGK)啟動子、伸長因子(ED1)-α啟動子、泛素啟動子、肌動蛋白啟動子、微管蛋白啟動子、免疫球蛋白啟動子、其片段或上述任一者的組合。合適的調節型啟動子控制序列的實例包括但不限于通過熱激、金屬、類固醇、抗生素或醇加以調節的那些。組織特異性啟動子的非限制性實例包括B29啟動子、CD14啟動子、CD43啟動子、CD45啟動子、CD68啟動子、結蛋白啟動子、彈性蛋白酶1啟動子、內皮糖蛋白啟動子、纖連蛋白啟動子、Flt-1啟動子、GFAP啟動子、GPIIb啟動子、ICAM-2啟動子、INF-β啟動子、Mb啟動子、NphsI啟動子、OG-2啟動子、SP-B啟動子、SYN1啟動子和WASP啟動子。該啟動子序列可以是野生型的,或其可以經過修飾以實現更高效或有效的表達。該表達構建體可以包含額外的表達控制序列(例如,增強子序列、Kozak序列、聚腺苷酸化序列、轉錄終止序列等)、可選標記序列(例如,抗生素抗性基因)、復制起點等等。額外信息可見于“CurrentProtocolsinMolecularBiology″Ausubel等,JohnWiley&Sons,NewYork,2003;或″MolecularCloning:ALaboratoryManual″Sambrook&Russell,ColdSpringHarborPress,ColdSpringHarbor,NY,第3版,2001。(iii)涉及抗病毒反應的細胞蛋白質的過度表現在諸多替代實施方案中,該哺乳動物細胞系可以經過工程改造以過度表達涉及宿主細胞抗病毒反應的細胞蛋白質。涉及抗病毒反應的蛋白質的非限制性實例包括雙鏈RNA激活蛋白激酶R(PKR,其也被稱為真核翻譯起始因子2-α激酶2或Eif2ak2)、受體相互作用蛋白激酶2(RIPK2)、干擾素(例如,I型和II型)、白介素(例如,IL-1和IL-6)、腫瘤壞死因子α、干擾素調節因子1、STAT、p53、激活轉錄因子3、NF-κB、真核起始因子2(eIF2)、細胞凋亡蛋白抑制劑(IAP)和鋅指抗病毒蛋白(ZAP)。在諸多具體實施方案中,該細胞系可以經過工程改造以過度表達PKR。過度表達可以通過引入編碼感興趣的蛋白質的核酸序列的一個或多個外源拷貝來實現。編碼感興趣的細胞蛋白質的序列一般被可操作地連接于PolII啟動子控制序列(見上文)。可以將該編碼序列的多個拷貝串聯連接并且置于單個啟動子控制序列的控制之下。可以將編碼感興趣的蛋白質的序列引入該細胞系中作為表達構建體的一部分(見上文)。因此,可以將該表達構建體插入染色體位置中,或替代地,該表達構建體可以在染色體外(例如,附加型),以便進行穩定表達。過度表達還可以通過修飾編碼感興趣的蛋白質的內源性染色體序列的啟動子控制序列來實現。舉例來說,內源啟動子控制序列可以通過插入至少一個外源“強”啟動子控制序列(即,對RNA聚合酶和/或相關因子具有高親和力)(其實例呈現在上文中)而加以修飾。或者,內源啟動子控制序列的序列可以經過修飾以模擬“強”啟動子控制序列。內源染色體序列可以使用以下部分(III)中詳述的靶向核酸內切酶介導的基因組修飾技術加以修飾。(b)細胞類型本文中所公開的抗病毒細胞系是哺乳動物細胞系。在一些實施方案中,對病毒感染具有抗性的細胞系可以來源于中國倉鼠卵巢(CHO)細胞;小鼠骨髓瘤NS0細胞;幼倉鼠腎(BHK)細胞;小鼠胚胎成纖維細胞3T3細胞(NIH3T3);鼠標B細胞淋巴瘤A20細胞;小鼠黑色素瘤B16細胞;小鼠成肌細胞C2C12細胞;小鼠骨髓瘤SP2/0細胞;小鼠胚胎間充質C3H-10T1/2細胞;小鼠癌瘤CT26細胞、小鼠前列腺DuCuP細胞;小鼠乳房EMT6細胞;小鼠肝癌Hepalc1c7細胞;小鼠骨髓瘤J5582細胞;小鼠上皮MTD-1A細胞;小鼠心肌MyEnd細胞;小鼠腎RenCa細胞;小鼠胰腺RIN-5F細胞;小鼠黑色素瘤X64細胞;小鼠淋巴瘤YAC-1細胞;大鼠成膠質細胞瘤9L細胞;大鼠B淋巴瘤RBL細胞;大鼠成神經細胞瘤B35細胞;大鼠肝癌細胞(HTC);水牛大鼠肝BRL3A細胞;犬腎細胞(MDCK);犬乳腺(CMT)細胞;大鼠骨肉瘤D17細胞;大鼠單核細胞/巨噬細胞DH82細胞;猴腎SV-40轉化成纖維細胞(COS7)細胞;猴腎CVI-76細胞;非洲綠猴腎(VERO-76)細胞;人胚腎細胞(HEK293、HEK293T);人宮頸癌細胞(HELA);人肺細胞(W138);人肝細胞(HepG2);人U2-OS骨肉瘤細胞、人A549細胞、人A-431細胞或人K562細胞。哺乳動物細胞系的詳盡列表可見于美國典型培養物保藏中心目錄(ATCC,Manassas,VA)。在其他實施方案中,具有病毒抗性的細胞系是非人哺乳動物細胞系。在其他實施方案中,具有病毒抗性的細胞系是非人非小鼠哺乳動物細胞系。在某些實施方案中,具有病毒抗性的細胞系是CHO細胞系。眾多CHO細胞系可購自ATCC。合適的CHO細胞系包括但不限于CHO-K1細胞和其衍生物。在各種實施方案中,該細胞系可能缺乏谷氨酰胺合成酶(GS)、二氫葉酸還原酶(DHFR)、次黃嘌呤-鳥嘌呤磷酸核糖基轉移酶(HPRT)或其組合。舉例來說,編碼GS、DHFR和/或HPRT的染色體序列可以是失活的。在諸多具體實施方案中,編碼GS的所有染色體序列在該細胞系中都是失活的。(c)病毒具有病毒抗性的經工程改造的哺乳動物細胞系可以抵抗多種哺乳動物病毒。該病毒可以是DNA病毒或RNA病毒,且該病毒可以有包膜或無包膜(“裸”)。可以通過唾液酸受體結合并進入哺乳動物細胞的病毒的非限制性實例包括細小病毒、呼腸孤病毒、輪狀病毒、流感病毒、腺相關病毒、杯狀病毒、副流感病毒、風疹病毒、冠狀病毒、諾羅病毒、腦心肌炎病毒和多瘤病毒。在一些實施方案中,經工程改造的哺乳動物細胞系對由至少一種細小病毒所致的感染具有抗性。合適的細小病毒的非限制性實例包括小鼠的微小病毒(MVM)(其還被稱為小鼠微小病毒(MMV)或嚙齒類原細小病毒1)、1型小鼠細小病毒(MPV-1)、2型小鼠細小病毒(MPV-2)、3型小鼠細小病毒(MPV-3)、豬細小病毒1、牛細小病毒1和人細小病毒(例如,人細小病毒B19、人細小病毒4、人細小病毒5等)。在諸多具體實施方案中,該細小病毒可以是MVM。在其他實施方案中,該病毒可以是呼腸孤病毒,諸如哺乳動物呼腸孤病毒3、哺乳動物正呼腸孤病毒、禽正呼腸孤病毒等等)。在一些實施方案中,對病毒感染性具有抗性的經工程改造的哺乳動物細胞系還可以對由柔膜細菌目中的生物體所致的感染具有抗性。具體來說,本文中所公開的細胞系可以對由支原體屬或螺原體屬所致的感染具有抗性。(d)編碼重組蛋白的可選核酸在一些實施方案中,對病毒感染具有抗性的哺乳動物細胞系可以進一步包含至少一種編碼重組蛋白的核酸。一般來說,重組蛋白是異源的,這意味著該蛋白質對細胞來說不是天然的。該重組蛋白可以是但不限于選自以下的治療性蛋白質:抗體、抗體片段、單克隆抗體、人源化抗體、人源化單克隆抗體、嵌合抗體、IgG分子、IgG重鏈、IgG輕鏈、IgA分子、IgD分子、IgE分子、IgM分子、疫苗、生長因子、細胞因子、干擾素、白介素、激素、凝血(或凝結)因子、血液組分、酶、治療性蛋白質、營養性蛋白質、上述任一者的功能片段或功能變體、或包含上述蛋白質和/或其功能片段或變體中的任一者的融合蛋白。在一些實施方案中,編碼重組蛋白的核酸可以被連接到編碼次黃嘌呤-鳥嘌呤磷酸核糖基轉移酶(HPRT)、二氫葉酸還原酶(DHFR)和/或谷氨酰胺合酶(GS)的序列,使得HPRT、DHFR和/或GS可以被用作可擴增的可選標記。編碼重組蛋白的核酸還可以連接到編碼至少一個抗生素抗性基因的序列和/或編碼諸如熒光蛋白之類的標記蛋白的序列。在一些實施方案中,編碼重組蛋白的核酸可以是表達構建體的一部分。如其他部分所詳述,表達構建體或載體可以包含額外的表達控制序列(例如,增強子序列、Kozak序列、聚腺苷酸化序列、轉錄終止序列等)、可選標記序列、復制起點等等。額外的信息可見于Ausubel等,2003,同上和Sambrook&Russell,2001,同上。在一些實施方案中,編碼重組蛋白的核酸可以位于染色體外。即,編碼重組蛋白的核酸可以由質粒、粘粒、人工染色體、微型染色體或另一個染色體外構建體瞬時表達。在其他實施方案中,編碼重組蛋白的核酸可以染色體整合到細胞的基因組中。該整合可以是隨機的或靶向的。因此,該重組蛋白可以被穩定地表達。在這個實施方案的一些迭代中,編碼重組蛋白的核酸序列可以可操作地連接到適當的異源表達控制序列(即,啟動子)。在其他迭代中,編碼重組蛋白的核酸序列可以被置于內源表達控制序列的控制之下。編碼重組蛋白的核酸序列可以使用同源重組、靶向核酸內切酶介導的基因組編輯、病毒載體、轉座子、質粒和其他眾所周知的手段而整合到細胞系的基因組中。額外的指導可見于Ausubel等,2003,同上和Sambrook&Russell,2001,同上。(e)組合物在某些實施方案中,經工程改造而表現出病毒抗性的哺乳動物細胞系可以是組合物的一部分,該組合物還包含至少一種病毒。該組合物因此包含本文中所公開的經工程改造的細胞系(任選地進一步包含編碼重組蛋白的核酸)和病毒,其中該至少一種病毒的進入和/或繁殖在該經工程改造的哺乳動物細胞系中被減少或消除。因此,該組合物中的細胞能夠繁殖,但該組合物中的病毒不能夠繁殖,因為其進入和/或復制在該細胞內被減少或消除。該組合物可以進一步包含至少一種細胞生長培養基以支持該經工程改造的哺乳動物細胞系細胞的生長。在一些情況下,該細胞生長培養基是無動物組分的培養基。(f)示例性實施方案在諸多具體實施方案中,具有病毒抗性的哺乳動物細胞系是CHO細胞系。該抗病毒CHO細胞系可以對由小鼠的微小病毒(MVM)(其還被稱為小鼠微小病毒(MMV)或嚙齒類原細小病毒1)和/或哺乳動物呼腸孤病毒3所致的感染具有抗性。具體來說,相對于未經修飾的親本CHO細胞系,經基因修飾的CHO細胞系對MVM或呼腸孤病毒3感染的抗性已經有所提高。在一些實施方案中,該未經修飾的親本細胞系是CHO(GS-/-)細胞系。該抗病毒CHO細胞系包含至少一個編碼COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色體序列。在一些實施方案中,在CHO細胞系中,編碼COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的染色體序列的所有拷貝都是失活的或被敲除。在其他實施方案中,包含編碼COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色體序列的CHO細胞進一步包含編碼Mgat1、Mgat2、Mgat3、Mgat4和/或Mgat5的失活染色體序列。在其他實施方案中,包含編碼St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色體序列的CHO細胞經過進一步工程改造以過度表達St6Gal1、St6Gal2、St6GalNac1、St6GalNac2、St6GalNac3、ST6GalNac4、St6GalNac5和/或St6GalNac6。(II)用于減少或防止病毒污染的方法本公開的另一個方面涵蓋用于減少或防止重組蛋白產物的病毒污染或減小生物生產系統的病毒污染的風險的方法。一般來說,該方法包括提供經工程改造的哺乳動物細胞系,其中至少一種病毒的進入和/或繁殖被減少或消除,和使用所述細胞系來產生該重組蛋白。該經工程改造的哺乳動物細胞系詳述于以上部分(I)中。與未經修飾的親本細胞系相比,該經工程改造的哺乳動物細胞系對病毒感染表現出抗性。該經工程改造的哺乳動物細胞系對部分(I)(c)中所描述的病毒表現出了抗性。合適的重組蛋白描述于部分(I)(d)中。用于產生或制造重組蛋白的手段在本領域中是眾所周知的(參見例如“BiopharmaceuticalProductionTechnology”,Subramanian(編),2012,Wiley-VCH;ISBN:978-3-527-33029-4)。在諸多具體實施方案中,該經工程改造的哺乳動物細胞系經過基因修飾而包含至少一個經修飾的染色體序列,使得該細胞系對病毒感染具有抗性。一般來說,使用本文中所公開的經工程改造的哺乳動物細胞系能降低病毒在發酵罐或其他生物生產容器中復制的能力,使得可復制病毒的水平處在痕量水平,或者,理想地,處在工業標準最佳做法檢測不到的水平。合適的方法包括核酸檢測法(例如,用于檢測病毒核酸的南方印跡、用于檢測病毒核酸的PCR或RT-PCR、測序法等等)、基于抗體的技術(例如,使用抗病毒蛋白質抗體的西方免疫印跡、ELISA法,諸如此類)和顯微鏡技術(例如,細胞病變效應測定法、用于檢測病毒顆粒的電子顯微鏡檢查等)。(III)用于制備抗病毒細胞系的方法本公開的又另一個方面提供了制備如以上部分(I)(a)(i)中詳述的具有改變的細胞表面受體的抗病毒細胞的方法。編碼涉及糖鏈合成的酶或蛋白質的染色體序列可以使用各種技術敲低或敲除,以便生成抗病毒細胞系。在一些實施方案中,該抗病毒細胞系可以通過靶向核酸內切酶介導的基因組修飾方法來制備。在其他實施方案中,該抗病毒細胞系可以通過RNA干擾介導的機制來制備。在又其他實施方案中,該抗病毒細胞系可以通過位點特異性重組系統、隨機誘變或本領域中已知的其他方法來制備。(a)靶向核酸內切酶介導的基因組編輯靶向核酸內切酶可以用于修飾(即,使失活或改變)感興趣的特定染色體序列。可以通過向細胞中引入靶向特定的染色體序列的靶向核酸內切酶或編碼該靶向核酸內切酶的核酸而使特定的染色體序列失活。在一個實施方案中,該靶向核酸內切酶識別并結合特定的染色體序列,并且引入了可由非同源端連接(NHEJ)修復過程修復的雙鏈斷裂。因為NHEJ容易出錯,所以可能發生至少一個核苷酸的缺失、插入和/或取代,從而破壞染色體序列的閱讀框,從而不產生蛋白質產物。在另一個實施方案中,該靶向核酸內切酶還可以被用于通過共引入與靶向染色體序列的一部分具有實質性序列同一性的多核苷酸經由同源重組反應來改變染色體序列。由該靶向核酸內切酶引入的雙鏈斷裂被同源定向修復過程修復,從而以使得染色體序列被改變或修改的方式使該染色體序列與該多核苷酸進行交換。多種靶向核酸內切酶可以用于修飾感興趣的染色體序列。該靶向核酸內切酶可以是天然存在的蛋白質或經工程改造的蛋白質。合適的靶向核酸內切酶包括但不限于鋅指核酸酶(ZFN)、CRISPR/Cas核酸內切酶、轉錄活化因子樣效應因子(TALE)核酸酶(TALEN)、大范圍核酸酶、位點特異性核酸內切酶和人工靶向DNA雙鏈斷裂誘導劑。(i)鋅指核酸酶在諸多具體實施方案中,該靶向核酸內切酶可以是鋅指核酸酶(ZFN)。ZFN結合特定靶向序列,并且將雙鏈斷裂引入該靶向序列中。典型地,ZFN包含DNA結合結構域(即,鋅指)和裂解結構域(即,核酸酶),各自描述如下。DNA結合結構域。DNA結合結構域或鋅指可以經過工程改造而識別并結合所選擇的任何核酸序列。參見例如Beerli等,(2002)Nat.Biotechnol.20:135-141;Pabo等,(2001)Ann.Rev.Biochem.70∶313-340;Isalan等,(2001)Nat.Biotechnol.19∶656-660;Segal等,(2001)Curr.Opin.Biotechnol.12:632-637;Choo等,(2000)Curr.Opin.Stmct.Biol.10:411-416;Zhang等,(2000)J.Biol.Chem.275(43):33850-33860;Doyon等,(2008)Nat.Biotechnol.26:702-708;和Santiago等,(2008)Proc.Natl.Acad.Sci.USA105:5809-5814。與天然存在的鋅指蛋白相比,經工程改造的鋅指結合結構域可以具有新穎的結合特異性。工程改造方法包括但不限于合理的設計和各種類型的選擇。合理的設計包括例如使用包括二聯、三聯和/或四聯核苷酸序列和個別鋅指氨基酸序列的數據庫,其中各二聯、三聯或四聯核苷酸序列與結合特定三聯或四聯序列的鋅指的一個或多個氨基酸序列締合。參見例如美國專利號6,453,242和6,534,261,其公開內容以全文引用的方式并入本文中。作為一個實例,可以使用美國專利6,453,242中所描述的算法來設計鋅指結合結構域,以靶向預先選定的序列。還可以使用替代方法,諸如使用非簡并識別密碼表的合理設計來設計鋅指結合結構域,以靶向特定序列(Sera等,(2002)Biochemistry41:7074-7081)。用于鑒別DNA序列中的潛在靶位點以及設計鋅指結合結構域的公開可用的基于網絡的工具在本領域中是公知的。舉例來說,用于識別DNA序列中的潛在靶位點的工具可見于http://www.zincfingertools.org。用于設計鋅指結合結構域的工具可見于http://zifit.partners.org/ZiFiT。(還參見Mandell等,(2006)Nuc.AcidRes.34:W516-W523;Sander等,(2007)Nuc.AcidRes.35:W599-W605。)鋅指結合結構域可以經過設計以識別并結合介于約3個核苷酸至約21個核苷酸長的DNA序列。在一個實施方案中,該鋅指結合結構域可以經過設計以識別并結合介于約9個至約18個核苷酸長的DNA序列。一般來說,本文中所使用的鋅指核酸酶的鋅指結合結構域包括至少三個鋅指識別區或鋅指,其中各鋅指結合3個核苷酸。在一個實施方案中,該鋅指結合結構域包括四個鋅指識別區。在另一個實施方案中,該鋅指結合結構域包括五個鋅指識別區。在又另一個實施方案中,該鋅指結合結構域包括六個鋅指識別區。鋅指結合結構域可以經過設計以結合任何合適的靶DNA序列。參見例如美國專利號6,607,882、6,534,261和6,453,242,其公開內容以全文引用的方式并入本文中。選擇鋅指識別區的示例性方法包括噬菌體呈現和雙雜交系統,該方法描述于美國專利號5,789,538、5,925,523、6,007,988、6,013,453、6,410,248、6,140,466、6,200,759和6,242,568;以及WO98/37186、WO98/53057、WO00/27878、WO01/88197和GB2,338,237中,各專利以全文引用的方式并入本文中。另外,鋅指結合結構域的結合特異性的增強已經描述于例如WO02/077227中,其全部公開內容以引用的方式并入本文中。用于設計和構建融合蛋白(和編碼其的多核苷酸)的鋅指結合結構域和方法對于本領域技術人員是已知的,并且詳述于例如美國專利號7,888,121中,該專利以全文引用的方式并入本文中。鋅指識別區和/或多指鋅指蛋白可以使用合適的接頭序列,包括例如五個或更多個氨基酸長的接頭連接在一起。參見美國專利號6,479,626、6,903,185和7,153,949,該專利的公開內容以全文引用的方式并入本文中,從而得到六個或更多個氨基酸長的接頭序列的非限制性實例。本文中所描述的鋅指結合結構域可以包括介于蛋白質的個別鋅指之間的合適的接頭的組合。在一些實施方案中,該鋅指核酸酶還包括核定位信號或序列(NLS)。NLS是氨基酸序列,其促進該鋅指核酸酶蛋白靶向細胞核,從而在染色體中的靶序列處引入雙鏈斷裂。核定位信號在本領域中是已知的。參見例如Makkerh等,(1996)CurrentBiology6:1025-1027。裂解結構域。鋅指核酸酶還包括裂解結構域。該鋅指核酸酶的裂解結構域部分可以獲自任何核酸內切酶或核酸外切酶。可以從中得到裂解結構域的內切核酸酶的非限制實例包括但不限于限制性核酸內切酶和歸巢核酸內切酶。參見例如NewEnglandBiolabsCatalog或Belfort等,(1997)NucleicAcidsRes.25:3379-3388。使DNA裂解的額外的酶是已知的(例如,S1核酸酶、綠豆核酸酶、胰DNA酶I、微球菌核酸酶、酵母HO核酸內切酶)。也參見Linn等(編)Nucleases,ColdSpringHarborLaboratoryPress,1993。這些酶(或其功能片段)中的一種或多種可以用作裂解結構域的來源。裂解結構域還可以來源于酶或其部分,如以上所描述,這需要裂解活性的二聚化。裂解可能需要兩個鋅指核酸酶,因為各核酸酶包含活性酶二聚體的單體。或者,單個鋅指核酸酶可以包含兩種單體以形成活性酶二聚體。如本文中所使用,“活性酶二聚體”是能夠使核酸分子裂解的酶二聚體。該兩個裂解單體可以來源于同一核酸內切酶(或其功能片段),或各單體可以來源于不同的核酸內切酶(或其功能片段)。當使用兩個裂解單體來形成活性酶二聚體時,兩個鋅指核酸酶的識別位點優選地經過布置以使得該兩個鋅指核酸酶與其相應的識別位點的結合將裂解單體相對于彼此置于允許裂解單體形成活性酶二聚體(例如,通過二聚化)的空間方向上。結果是,該識別位點的鄰近邊緣可以間隔約5個至約18個核苷酸。舉例來說,鄰近邊緣可以間隔約5個、6個、7個、8個、9個、10個、11個、12個、13個、14個、15個、16個、17個或18個核苷酸。然而,應理解,任何整數個核苷酸或核苷酸對可以介入兩個識別位點之間(例如,約2個至約50個核苷酸對或更多)。該鋅指核酸酶(諸如例如本文中詳細描述的那些)的識別位點的鄰近邊緣可以間隔6個核苷酸。一般來說,裂解位點位于識別位點之間。限制性核酸內切酶(限制性酶)存在于許多物種中,并且能夠序列特異性結合DNA(在識別位點處)且使結合位點處或附近的DNA裂解。某些限制性酶(例如,IIS型)在與識別位點相距較遠的位點處使DNA裂解,并且具有可分離的結合結構域和裂解結構域。舉例來說,IIS型酶FokI在與其一個鏈上的識別位點相距9個核苷酸且與其在另一個鏈上的識別位點相距13個核苷酸處催化DNA的雙鏈裂解。參見例如美國專利號5,356,802、5,436,150和5,487,994;以及Li等,(1992)Proc.Natl.Acad.Sci.USA89:4275-4279;Li等,(1993)Proc.Natl.Acad.Sci.USA90:2764-2768;Kim等,(1994a)Proc.Natl.Acad.Sci.USA91:883-887;Kim等,(1994b)J.Biol.Chem.269:31978-31982。因此,鋅指核酸酶可以包含來自至少一種IIS型限制性酶的裂解結構域和一個或多個鋅指結合結構域,其可能經過或可能沒經過工程改造。示例性IIS型限制性酶描述于例如國際公開WO07/014,275中,其公開內容以全文引用的方式并入本文中。額外的限制性酶還含有可分離的結合結構域和裂解結構域,并且這些也被本發明涵蓋。參見例如Roberts等,(2003)NucleicAcidsRes.31:418-420。裂解結構域與結合結構域可分離的示例性IIS型限制性酶是FokI。這種特別的酶是活性二聚體(Bitinaite等,(1998)Proc.Natl.Acad.Sci.USA95:10,570-10,575)。因此,出于本公開的目的,鋅指核酸酶中所使用的FokI酶部分被視為裂解單體。因此,對于使用FokI裂解結構域的靶向雙鏈裂解,兩個鋅指核酸酶(各自包含FokI裂解單體)可以用來重建活性酶二聚體。或者,還可以使用含有鋅指結合結構域和兩個FokI裂解單體的單個多肽分子。在某些實施方案中,該裂解結構域包含一個或多個能減少或防止同源二聚化的經工程改造的裂解單體。作為非限制性實例,在FokI的位置446、447、479、483、484、486、487、490、491、496、498、499、500、531、534、537和538上的氨基酸殘基是影響FokI裂解半結構域的二聚化的所有靶標。形成專性異源二聚體的示例性經工程改造的FokI裂解單體包括一對,其中第一裂解單體包括在FokI的氨基酸殘基位置490和538上的突變,且第二裂解單體包括在氨基酸殘基位置486和499上的突變。因此,在經工程改造的裂解單體的一個實施方案中,氨基酸位置490上的突變以Lys(K)置換Glu(E);氨基酸殘基538上的突變以Lys(K)置換Iso(I);氨基酸殘基486上的突變以Glu(E)置換Gln(Q);且499位上的突變以Lys(K)置換Iso(I)。具體來說,該經工程改造的裂解單體可以通過以下方式制得:在一個裂解單體中使490位從E突變至K且使538位從I突變至K,以產生經工程改造的裂解單體,命名為“E490K:I538K”,并且在另一個裂解單體中使486位從Q突變至E且使499位從I突變至K,以產生經工程改造的裂解單體,命名為“Q486E:I499K”。以上所描述的經工程改造的裂解單體是專性異源二聚體突變體,其中異常裂解被減至最少或被消除。可以使用合適的方法來制備經工程改造的裂解單體,例如通過如美國專利號7,888,121中所描述的野生型裂解單體(FokI)的定點誘變,該專利全文并入本文中。其他結構域。在一些實施方案中,該鋅指核酸酶還包含至少一個核定位序列(NLS)。NLS是氨基酸序列,其促進該鋅指核酸酶蛋白靶向細胞核,從而在染色體中的靶序列處引入雙鏈斷裂。核定位信號在本領域中是已知的(參見例如Lange等,J.Biol.Chem.,2007,282:5101-5105)。舉例來說,在一個實施方案中,該NLS可以是單份序列,諸如PKKKRKV(SEQIDNO:1)或PKKKRRV(SEQIDNO:2)。在另一個實施方案中,該NLS可以是二分序列。在又另一個實施方案中,該NLS可以是KRPAATKKAGQAKKKK(SEQIDNO:3)。該NLS可以位于蛋白質的N末端、C末端或內部位置。在另外的實施方案中,該鋅指核酸酶還可以包含至少一個細胞穿透結構域。在一個實施方案中,該細胞穿透結構域可以是來源于HIV-1TAT蛋白的細胞穿透肽序列。作為一個實例,該TAT細胞穿透序列可以是GRKKRRQRRRPPQPKKKRKV(SEQIDNO:4)。在另一個實施方案中,該細胞穿透結構域可以是來源于人乙型肝炎病毒的細胞穿透肽序列TLM(PLSSIFSRIGDPPKKKRKV,SEQIDNO:5)。在另一個實施方案中,該細胞穿透結構域可以是MPG(GALFLGWLGAAGSTMGAPKKKRKV,SEQIDNO:6;或GALFLGFLGAAGSTMGAWSQPKKKRKV,SEQIDNO:7)。在一個另外的實施方案中,該細胞穿透結構域可以是Pep-1(KETWWETWWTEWSQPKKKRKV,SEQIDNO:8)、VP22、來自單純皰疹病毒的細胞穿透肽、或聚精氨酸肽序列。該細胞穿透結構域可以位于鋅指核酸酶的N末端、C末端或內部位置。在又其他實施方案中,該鋅指核酸酶還可以包含至少一個標記結構域。標記結構域的非限制性實例包括熒光蛋白、純化標簽和表位標簽。在一個實施方案中,該標記結構域可以是熒光蛋白。合適的熒光蛋白的非限制性實例包括綠色熒光蛋白(例如,GFP、GFP-2、tagGFP、turboGFP、EGFP、Emerald、AzamiGreen、MonomericAzamiGreen、CopGFP、AceGFP、ZsGreen1)、黃色熒光蛋白(例如,YFP、EYFP、Citrine、Venus、YPet、PhiYFP、ZsYellow1)、藍色熒光蛋白(例如,EBFP、EBFP2、Azurite、mKalama1、GFPuv、Sapphire、T-sapphire)、青色熒光蛋白(例如ECFP、Cerulean、CyPet、AmCyan1、Midoriishi-Cyan)、紅色熒光蛋白(mKate、mKate2、mPlum、DsRed單體、mCherry、mRFP1、DsRed-Express、DsRed2、DsRed-Monomer、HcRed-Tandem、HcRed1、AsRed2、eqFP611、mRasberry、mStrawberry、Jred)和橙色熒光蛋白(mOrange、mKO、Kusabira-Orange、MonomericKusabira-Orange、mTangerine、tdTomato)或任何其他合適的熒光蛋白。在另一個實施方案中,該標記結構域可以是純化標簽和/或表位標簽。合適的標簽包括但不限于谷胱甘肽-S-轉移酶(GST)、甲殼素結合蛋白(CBP)、麥芽糖結合蛋白、硫氧還蛋白(TRX)、聚(NANP)、串聯親和純化(TAP)標簽、myc、AcV5、AU1、AU5、E、ECS、E2、FLAG、HA、nus、Softag1、Softag3、Strep、SBP、Glu-Glu、HSV、KT3、S、S1、T7、V5、VSV-G、6xHis、生物素羧基載體蛋白(BCCP)和鈣調蛋白。該標記結構域可以位于鋅指核酸酶的N末端、C末端或內部位置。該標記結構域可以通過2A肽連接到鋅指核酸酶(Szymczak等,2004,Nat.Biotechnol.,589(5):589-94)。該2A肽最初是在正鏈RNA病毒中被表征,該病毒產生在翻譯成成熟個別蛋白質期間被“裂解”的多蛋白。更具體來說,該2A肽區(~20個氨基酸)在其自身的C末端介導“裂解”,以使其自身從該多蛋白的下游區域釋放。一般來說,2A肽序列以甘氨酸和脯氨酸殘基封端。在2A肽的翻譯期間,核糖體在甘氨酸殘基之后暫停,從而釋放新生的多肽鏈。翻譯恢復,同時2A序列的脯氨酸殘基變成下游蛋白的第一個氨基酸。(ii)CRISPR/Cas核酸內切酶在其他實施方案中,該靶向核酸內切酶可以是CRISPR/Cas核酸內切酶。CRISPR/Cas核酸內切酶是來源于CRISPR/Cas系統的RNA引導型核酸內切酶。細菌和古細菌已經進化出使用CRISPR(成簇的規律間隔的短回文重復序列)和Cas(CRISPR相關)蛋白來檢測和消滅入侵的病毒或質粒的基于RNA的適應性免疫系統。CRISPR/Cas核酸內切酶可以經過編程,以便通過提供靶特異性合成引導RNA而引入靶向位點特異性雙鏈斷裂(Jinek等,2012,Science,337:816-821)。核酸內切酶。該CRISPR/Cas核酸內切酶可以來源于I型、II型或III型CRISPR/Cas系統。合適的CRISPR/Cas蛋白的非限制性實例包括Cas3、Cas4、Cas5、Cas5e(或CasD)、Cas6、Cas6e、Cas6f、Cas7、Cas8a1、Cas8a2、Cas8b、Cas8c、Cas9、Cas10、Cas10d、CasF、CasG、CasH、Csy1、Csy2、Csy3、Cse1(或CasA)、Cse2(或CasB)、Cse3(或CasE)、Cse4(或CasC)、Csc1、Csc2、Csa5、Csn2、Csm2、Csm3、Csm4、Csm5、Csm6、Cmr1、Cmr3、Cmr4、Cmr5、Cmr6、Csb1、Csb2、Csb3、Csx17、Csx14、Csx10、Csx16、CsaX、Csx3、Csz1、Csx15、Csf1、Csf2、Csf3、Csf4和Cu1966。在一個實施方案中,該CRISPR/Cas核酸內切酶來源于II型CRISPR/Cas系統。在示例性實施方案中,該CRISPR/Cas核酸內切酶來源于Cas9蛋白。該Cas9蛋白可以來自化膿性鏈球菌、嗜熱鏈球菌、鏈球菌屬、達松維爾類諾卡菌、始旋鏈霉菌、綠產色鏈霉菌、綠產色鏈霉菌、玫瑰鏈孢囊菌、玫瑰鏈孢囊菌、酸熱脂環酸桿菌、假真菌樣芽孢桿菌、枯草芽孢桿菌、西伯利亞微小桿菌、保加利亞乳桿菌、唾液乳桿菌、海洋微顫藍細菌、伯克霍爾德氏菌、萘降解極地單胞菌、極地單胞菌屬、瓦氏鱷球藻、藍桿藻屬、銅綠微囊藻、聚球藻屬、阿拉伯糖醋鹽桿菌、丹氏制氨菌、極端嗜熱纖維素降解厭氧菌、金礦菌、肉毒梭菌、難辨梭狀芽孢桿菌、大芬戈爾德菌、嗜熱鹽堿厭氧菌、喜溫丙酸互營菌、喜溫嗜酸硫桿菌、氧化亞鐵硫桿菌、紫色硫細菌、海桿菌屬、嗜鹽亞硝化球菌、瓦氏亞硝化球菌、游海假交替單胞菌、消旋纖線桿菌、極端嗜鹽甲烷鹽菌、多變魚腥藻、泡沫節球藻、念珠藻屬、極大節螺藻、節旋螺旋藻、節旋藻屬、鞘絲藻屬、原型微鞘藻、顫藻屬、運動石油神袍菌、非洲棲熱腔菌或海濱藍藻菌。在一個具體實施方案中,該Cas9蛋白來自化膿性鏈球菌。一般來說,CRISPR/Cas蛋白包含至少一個RNA識別結構域和/或RNA結合結構域。RNA識別結構域和/或RNA結合結構域與引導RNA相互作用,從而將CRISPR/Cas蛋白引向特定的染色體或染色體序列(即,靶位點)。該CRISPR/Cas蛋白還可以包含核酸酶結構域(即,DNA酶或RNA酶結構域)、DNA結合結構域、解螺旋酶結構域、蛋白-蛋白相互作用結構域、二聚結構域以及其他結構域。該CRISPR/Cas蛋白可以來源于野生型CRISPR/Cas蛋白、經修飾的CRISPR/Cas蛋白或者野生型或經修飾的CRISPR/Cas蛋白的片段。該CRISPR/Cas蛋白可以經修飾以增加核酸結合親和力和/或特異性,改變酶活性和/或改變該蛋白質的另一種性質。舉例來說,該CRISPR/Cas蛋白的核酸酶(即,DNA酶、RNA酶)結構域可以被修飾、缺失或失活。該CRISPR/Cas蛋白可以被截短以去除對于該蛋白質的功能來說并非必不可少的結構域。該CRISPR/Cas蛋白還可以被截短或經修飾以使該蛋白質或與該CRISPR/Cas蛋白融合的效應因子結構域的活性最優化。在一些實施方案中,該CRISPR/Cas核酸內切酶可以來源于野生型Cas9蛋白或其片段。在其他實施方案中,該CRISPR/Cas核酸內切酶可以來源于經修飾的Cas9蛋白。舉例來說,Cas9蛋白的氨基酸序列可以經修飾而改變該蛋白質的一種或多種性質(例如,核酸酶活性、親和力、穩定性等)。或者,不涉及RNA引導型裂解的Cas9蛋白的結構域可以被從該蛋白質中消除,使得經修飾的Cas9蛋白比野生型Cas9蛋白小。一般來說,Cas9蛋白包含至少兩個核酸酶(即,DNA酶)結構域。舉例來說,Cas9蛋白可以包含RuvC樣核酸酶結構域和HNH樣核酸酶結構域。RuvC和HNH結構域一起起作用以切開單鏈,從而在DNA中產生雙鏈斷裂(Jinek等,Science,337:816-821)。在一個實施方案中,該基于CRISPR的核酸內切酶來源于Cas9蛋白且包含兩個功能核酸酶結構域。由天然存在的CRISPR/Cas系統來識別典型地具有約14-15bp長度的靶位點(Cong等,Science,339:819-823)。該靶位點不具有序列限制,除了與引導RNA的5′端互補的序列(即,稱為原型間隔序列)緊隨(3′或下游)共有序列之后。這個共有序列也被稱為原型間隔序列相鄰基元(或PAM)。PAM的實例包括但不限于NGG、NGGNG和NNAGAAW(其中N被定義為任何核苷酸且W被定義為A或T)。在典型長度下,在靶基因組內只有約5-7%的靶位點將是唯一的,這表明脫靶效應可能是顯著的。靶位點的長度可以通過命令兩個結合事件而加以擴展。舉例來說,基于CRISPR的核酸內切酶可以經過修改,使得其只能裂解雙鏈序列的一個鏈(即,轉化至切口酶)。因此,與兩個不同的引導RNA組合使用基于CRISPR的切口酶將基本上使靶位點的長度翻倍,同時仍實現雙鏈斷裂。因此,在一些實施方案中,Cas9衍生核酸內切酶可以經修飾以含有一個功能核酸酶結構域(RuvC樣或HNH樣核酸酶結構域)。舉例來說,Cas9衍生蛋白可以經修飾以使核酸酶結構域之一缺失或突變,使其不再具有功能性(即,該結構域缺乏核酸酶活性)。在一些實施方案中,核酸酶結構域之一是無活性的,該Cas9衍生蛋白能夠向雙鏈核酸中引入缺口(這類蛋白質被稱為“切口酶”),但不能使雙鏈DNA裂解。舉例來說,RuvC樣結構域中的天冬氨酸至丙氨酸(D10A)轉化將Cas9衍生蛋白轉化成“HNH”切口酶。同樣,HNH結構域中的組氨酸至丙氨酸(H840A)轉化(在一些情況下,該組氨酸位于839位)將Cas9衍生蛋白質轉化成“RuvC”切口酶。因此,舉例來說,在一個實施方案中,該Cas9衍生切口酶在RuvC樣結構域中具有天冬氨酸至丙氨酸(D10A)轉化。在另一個實施方案中,該Cas9衍生切口酶在HNH結構域中具有組氨酸至丙氨酸(H840A或H839A)轉化。該Cas9衍生切口酶的RuvC樣或HNH樣核酸酶結構域可以使用眾所周知的方法,諸如定點誘變、PCR介導的誘變和全基因合成以及本領域中已知的其他方法加以修飾。其他結構域。該CRISPR/Cas核酸內切酶或切口酶一般包括至少一個核定位信號(NLS)。舉例來說,在一個實施方案中,該NLS可以是單份序列,諸如PKKKRKV(SEQIDNO:1)或PKKKRRV(SEQIDNO:2)。在另一個實施方案中,該NLS可以是二分序列。在又另一個實施方案中,該NLS可以是KRPAATKKAGQAKKKK(SEQIDNO:3)。該NLS可以位于蛋白質的N末端、C末端或內部位置。在一些實施方案中,該CRISPR/Cas核酸內切酶或切口酶可以進一步包括至少一個細胞穿透結構域。該細胞穿透結構域可以是來源于HIV-1TAT蛋白的細胞穿透肽序列。作為一個實例,該TAT細胞穿透序列可以是GRKKRRQRRRPPQPKKKRKV(SEQIDNO:4)。在另一個實施方案中,該細胞穿透結構域可以是來源于人乙型肝炎病毒的細胞穿透肽序列TLM(PLSSIFSRIGDPPKKKRKV,SEQIDNO:5)。在另一個實施方案中,該細胞穿透結構域可以是MPG(GALFLGWLGAAGSTMGAPKKKRKV,SEQIDNO:6;或GALFLGFLGAAGSTMGAWSQPKKKRKV,SEQIDNO:7)。在一個另外的實施方案中,該細胞穿透結構域可以是Pep-1(KETWWETWWTEWSQPKKKRKV,SEQIDNO:8)、VP22、來自單純皰疹病毒的細胞穿透肽、或聚精氨酸肽序列。該細胞穿透結構域可以位于該蛋白質的N末端、C末端或內部位置。在又其他實施方案中,該CRISPR/Cas核酸內切酶或切口酶可以進一步包括至少一個標記結構域。標記結構域的非限制性實例包括熒光蛋白、純化標簽和表位標簽。在一個實施方案中,該標記結構域可以是熒光蛋白。合適的熒光蛋白的非限制性實例包括綠色熒光蛋白(例如,GFP、GFP-2、tagGFP、turboGFP、EGFP、Emerald、AzamiGreen、MonomericAzamiGreen、CopGFP、AceGFP、ZsGreen1)、黃色熒光蛋白(例如,YFP、EYFP、Citrine、Venus、YPet、PhiYFP、ZsYellow1)、藍色熒光蛋白(例如,EBFP、EBFP2、Azurite、mKalama1、GFPuv、Sapphire、T-sapphire)、青色熒光蛋白(例如ECFP、Cerulean、CyPet、AmCyan1、Midoriishi-Cyan)、紅色熒光蛋白(mKate、mKate2、mPlum、DsRed單體、mCherry、mRFP1、DsRed-Express、DsRed2、DsRed-Monomer、HcRed-Tandem、HcRed1、AsRed2、eqFP611、mRasberry、mStrawberry、Jred)和橙色熒光蛋白(mOrange、mKO、Kusabira-Orange、MonomericKusabira-Orange、mTangerine、tdTomato)或任何其他合適的熒光蛋白。在另一個實施方案中,該標記結構域可以是純化標簽和/或表位標簽。合適的標簽包括但不限于谷胱甘肽-S-轉移酶(GST)、甲殼素結合蛋白(CBP)、麥芽糖結合蛋白、硫氧還蛋白(TRX)、聚(NANP)、串聯親和純化(TAP)標簽、myc、AcV5、AU1、AU5、E、ECS、E2、FLAG、HA、nus、Softag1、Softag3、Strep、SBP、Glu-Glu、HSV、KT3、S、S1、T7、V5、VSV-G、6xHis、生物素羧基載體蛋白(BCCP)和鈣調蛋白。該標記結構域可以位于該蛋白質的N末端、C末端或內部位置。該標記結構域可以通過2A肽連接到該CRISPR/Cas核酸內切酶或切口酶(Szymczak等,2004,Nat.Biotechnol.,589(5):589-94)。引導RNA。該CRISPR/Cas核酸內切酶由引導RNA引導至靶位點。引導RNA在染色體中與該CRISPR/Cas核酸內切酶和該靶位點相互作用,在該位點處,該CRISPR/Cas核酸內切酶或切口酶使該雙鏈序列的至少一個鏈裂解。可以將該引導RNA與CRISPR/Cas核酸內切酶或編碼該CRISPR/Cas核酸內切酶的核酸一起引入細胞中。或者,可以將編碼CRISPR/Cas核酸內切酶和引導RNA的DNA引入到細胞中。引導RNA包含三個區域:5′端上與靶位點上的序列互補的第一區域;形成莖環結構的第二內部區域;和基本上保持單鏈的第三3′區域。各引導RNA的第一區域是不同的,使得各引導RNA將CRISPR/Cas核酸內切酶或切口酶引導至特定的靶位點。各引導RNA的第二區域和第三區域(也稱為支架區域)在所有的引導RNA中可以相同。引導RNA的第一區域與靶位點上的序列(即,原型間隔序列)互補,使得引導RNA的第一區域可以與靶位點上的序列進行堿基配對。一般來說,引導RNA的第一區域的序列與靶位點上的序列之間沒有錯配(即,完全互補)。在各種實施方案中,引導RNA的第一區域可以包含約10個核苷酸至超過約25個核苷酸。舉例來說,引導RNA的第一區域與染色體序列中的靶位點之間進行堿基配對的區域的長度可以是約10、11、12、13、14、15、16、17、18、19、20、22、23、24、25或超過25個核苷酸。在示例性實施方案中,引導RNA的第一區域的長度是約19或20個核苷酸。引導RNA還包含形成二級結構的第二區域。在一些實施方案中,該二級結構包括莖(或發夾)和環。該環和該莖的長度可以變化。舉例來說,該環的長度可以介于約3至約10個核苷酸的范圍內,且該莖的長度可以介于約6至約20個堿基對的范圍內。該莖可以包括一個或多個具有1至約10個核苷酸的隆凸。因此,該第二區域的整個長度可以介于約16至約60個核苷酸的長度范圍內。在一個示例性實施方案中,該環的長度是約4個核苷酸,且該莖包括約12個堿基對。該引導RNA還包括處于3′端上的基本上保持單鏈的第三區域。因此,該第三區域與感興趣的細胞中的任何染色體序列都不具有互補性,而且與引導RNA的其余部分不具有互補性。該第三區域的長度可以變化。一般來說,該第三區域的長度超過約4個核苷酸。舉例來說,該第三區域的長度可以介于約5至約60個核苷酸的長度范圍內。該引導RNA的第二和第三區域(或支架)的組合長度可以介于約30至約120個核苷酸的長度范圍內。在一個方面,該引導RNA的第二和第三區域的組合長度在約70至約100個核苷酸的長度范圍內。在一些實施方案中,該引導RNA包含一個包括所有三個區域的分子。在其他實施方案中,該引導RNA可以包括兩個獨立的分子。該第一RNA分子可以包含該引導RNA的第一區域和該引導RNA的第二區域的“莖”的一半。該第二RNA分子可以包括該引導RNA的第二區域的“莖”的另一半和該引導RNA的第三區域。因此,在這個實施方案中,該第一RNA分子和該第二RNA分子各自含有彼此互補的核苷酸序列。舉例來說,在一個實施方案中,該第一RNA分子和該第二RNA各自包含與另一序列進行堿基配對以形成功能性引導RNA的序列(約6至約20個核苷酸)。(iii)其他靶向核酸內切酶在其他實施方案中,該靶向核酸內切酶可以是大范圍核酸酶。大范圍核酸酶是以長識別序列為特征的脫氧核糖核酸內切酶,即,該識別序列一般介于約12個堿基對至約40個堿基對的范圍內。作為這種要求的結果,該識別序列一般僅在任何給定的基因組中出現一次。在大范圍核酸酶中,被命名為LAGLIDADG的歸巢核酸內切酶家族已經成為用于基因組和基因組工程改造研究的有價值的工具(參見例如Amould等,2011,ProteinEngDesSel,24(1-2):27-31)。大范圍核酸酶可以通過使用本領域技術人員眾所周知的技術來修飾其識別序列而靶向特定的染色體序列。在另外的實施方案中,靶向核酸內切酶可以是轉錄活化因子樣效應因子(TALE)核酸酶。TALE是可以容易進行工程改造以結合新的DNA靶標的來自植物病原體黃單胞菌的轉錄因子。TALE或其截短版本可連接到核酸內切酶的催化結構域,諸如FokI,以建立被稱為TALE核酸酶或TALEN的靶向核酸內切酶(Sanjana等,2012,NatProtoc,7(1):171-192)。在又其他實施方案中,該靶向核酸內切酶可以是位點特異性核酸內切酶。具體來說,該位點特異性核酸內切酶可以是“稀有切割”核酸內切酶,其識別序列很少出現在基因組中。或者,該位點特異性核酸內切酶可以經工程改造以使感興趣的位點裂解(Friedhoff等,2007,MethodsMolBiol352:1110123)。一般來說,該位點特異性核酸內切酶的識別序列只在基因組中出現一次。在替代其他實施方案中,該靶向核酸內切酶可以是人工靶向DNA雙鏈斷裂誘導劑。(iv)可選多核苷酸靶向基因組修飾方法可以進一步包括向細胞中引入至少一種多核苷酸,該多核苷酸包含與靶向裂解位點的至少一側上的序列具有實質性序列同一性的序列,使得由該靶向核酸內切酶引入的雙股斷裂可以通過同源性定向修復方法加以修復;和使該多核苷酸的序列與內源染色體序列進行交換,從而修飾該內源染色體序列。舉例來說,該多核苷酸包含與該靶向裂解位點的一側上的序列具有實質性序列同一性的第一序列和與該靶向裂解位點的另一側上的序列具有實質性序列一致性的第二序列。或者,該多核苷酸包含與該靶向裂解位點的一側上的序列具有實質性序列同一性的第一序列和與位于遠離該靶向裂解位點處的序列具有實質性序列一致性的第二序列。該位于遠離該靶向裂解位點處的序列可以是該靶向裂解位點上游或下游的數十、數百或數千個核苷酸。該多核苷酸中與該靶向染色體序列中的序列具有實質性序列同一性的第一序列和第二序列的長度可以并且將會變化。一般來說,該多核苷酸中的第一序列和第二序列各自的長度是至少約10個核苷酸。在各種實施方案中,與染色體序列具有實質性序列同一性的多核苷酸序列的長度可以是約15個核苷酸、約20個核苷酸、約25個核苷酸、約30個核苷酸、約40個核苷酸、約50個核苷酸、約100個核苷酸或超過100個核苷酸。短語“實質性序列同一性”意指多核苷酸中的序列與感興趣的染色體序列具有至少約75%的序列同一性。在一些實施方案中,該聚核苷酸中的序列與感興趣的染色體序列具有75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性。該多核苷酸的長度可以并且將會變化。舉例來說,該多核苷酸可以介于約20個核苷酸的長度直至約200,000個核苷酸的長度的范圍內。在各種實施方案中,該多核苷酸介于約20個核苷酸至約100個核苷酸的長度、約100個核苷酸約1000個核苷酸的長度、約1000個核苷酸至約10,000個核苷酸的長度、約10,000個核苷酸至約100,000個核苷酸的長度或約100,000個核苷酸至約200,000個核苷酸的長度的范圍內。典型地,該多核苷酸是DNA。該DNA可以是單鏈或雙鏈的。該多核苷酸可以是DNA質粒、細菌人工染色體(BAC)、酵母人工染色體(YAC)、病毒載體、線性DNA片、PCR片段、裸核酸、或核酸與諸如脂質體或泊洛沙姆之類的遞送媒劑的復合物。在某些實施方案中,該多核苷酸是單鏈的。在諸多示例性實施方案中,該多核苷酸是包含少于約200個核苷酸的單鏈寡核苷酸。在一些實施方案中,該多核苷酸進一步包括標記。這種標記可以使得能夠篩選靶向整合。在一些實施方案中,該標記是限制性核酸內切酶位點。在其他實施方案中,該標記物是熒光蛋白、純化標簽或表位標簽。合適的熒光蛋白的非限制性實例包括綠色熒光蛋白(例如,GFP、GFP-2、tagGFP、turboGFP、EGFP、Emerald、AzamiGreen、MonomericAzamiGreen、CopGFP、AceGFP、ZsGreen1)、黃色熒光蛋白(例如,YFP、EYFP、Citrine、Venus、YPet、PhiYFP、ZsYellow1)、藍色熒光蛋白(例如,EBFP、EBFP2、Azurite、mKalama1、GFPuv、Sapphire、T-sapphire)、青色熒光蛋白(例如ECFP、Cerulean、CyPet、AmCyan1、Midoriishi-Cyan)、紅色熒光蛋白(mKate、mKate2、mPlum、DsRed單體、mCherry、mRFP1、DsRed-Express、DsRed2、DsRed-Monomer、HcRed-Tandem、HcRed1、AsRed2、eqFP611、mRasberry、mStrawberry、Jred)和橙色熒光蛋白(mOrange、mKO、Kusabira-Orange、MonomericKusabira-Orange、mTangerine、tdTomato)或任何其他合適的熒光蛋白。在其他實施方案中,該標記可以是純化標簽和/或表位標簽。示例性標簽包括但不限于谷胱甘肽-S-轉移酶(GST)、甲殼素結合蛋白(CBP)、麥芽糖結合蛋白、硫氧還蛋白(TRX)、聚(NANP)、串聯親和純化(TAP)標簽、myc、AcV5、AU1、AU5、E、ECS、E2、FLAG、HA、nus、Softag1、Softag3、Strep、SBP、Glu-Glu、HSV、KT3、S、S1、T7、V5、VSV-G、6xHis、生物素羧基載體蛋白(BCCP)和鈣調蛋白。(v)遞送至細胞該方法包括該靶向核酸內切酶將引入感興趣的細胞中。可以將該靶向核酸內切酶作為已純化的分離蛋白質或編碼該靶向核酸內切酶的核酸引入細胞中。該核酸可以是DNA或RNA。在編碼核酸是mRNA的實施方案中,該mRNA可以是5′封端的和/或3′聚腺苷酸化的。在編碼核酸是DNA的實施方案中,該DNA可以是線性或環狀的。該DNA可以是載體的一部分,其中該編碼DNA可以可操作地連接到合適的啟動子。本領域技術人員應熟悉適當的載體、啟動子、其他控制元件和將該載體引入感興趣的細胞中的手段。該靶向核酸內切酶分子和上述可選多核苷酸可以通過多種手段引入到細胞中。合適的遞送手段包括顯微注射、電穿孔、超聲波穿孔、基因槍法、磷酸鈣介導的轉染、陽離子轉染、脂質體轉染、樹枝狀聚合物轉染、熱激轉染、核轉染轉染、磁轉染、脂質轉染、刺穿轉染、光學轉染、專有劑增強核酸吸收,和經由脂質體、免疫脂質體、病毒體或人工病毒體進行遞送。在一個具體實施方案中,通過核轉染將該靶向核酸內切酶分子和多核苷酸引入細胞中。在將多于一個靶向核酸內切酶分子和多于一個多核苷酸引入細胞中的實施方案中,可以同時或依次引入該分子。舉例來說,可以在同時引入諸多靶向核酸內切酶分子,各分子對靶向裂解位點(和可選多核苷酸)具有特異性。或者,可以依次引入各靶向核酸內切酶分子以及可選多核苷酸。該靶向核酸內切酶分子與可選多核苷酸的比率可以并且將會變化。一般來說,靶向核酸內切酶分子與多核苷酸的比率介于約1∶10至約10∶1的范圍內。在各種實施方案中,該靶向核酸內切酶分子與多核苷酸的比率可以是約1∶10、1∶9、1∶8、1∶7、1∶6、1∶5、1∶4、1∶3、1∶2、1∶1、2∶1、3∶1、4∶1、5∶1、6∶1、7∶1、8∶1、9∶1或10∶1。在一個實施方案中,該比率是約1∶1。(vi)培養細胞該方法還包括將細胞維持在適當的條件下,使得通過靶向核酸內切酶引入的雙鏈斷裂可以通過以下方式得以修復:(i)非同源末端連接修復方法,使得染色體序列通過至少一個核苷酸的缺失、插入和/或取代而被修飾,或者,任選地,(ii)同源定向修復方法,使得染色體序列與多核苷酸的序列交換,從而對染色體序列進行修飾。在將編碼靶向核酸內切酶的核酸引入細胞中的實施方案中,該方法包括將該細胞維持在適當的條件下,使得該細胞表達該靶向核酸內切酶。一般來說,將該細胞維持在適于細胞生長和/或維持的條件下。合適的細胞培養條件在本領域中是眾所周知的并且描述于例如以下文獻中:Santiago等,(2008)PNAS105:5809-5814;Moehle等,(2007)PNAS104:3055-3060;Umov等,(2005)Nature435:646-651;和Lombardo等,(2007)Nat.Biotechnology25:1298-1306。本領域技術人員應了解,用于培養細胞的方法在本領域中是已知的,而且可以并且將會取決于細胞類型而變化。在所有情況下,可以使用常規優化來確定用于特定細胞類型的最佳技術。在該方法的這個步驟期間,該靶向核酸內切酶在染色體序列中的靶向裂解位點上識別、結合并創建雙鏈斷裂,而在雙鏈斷裂修復期間,至少一個核苷酸的缺失、插入和/或取代被引入該靶向染色體序列中。在諸多具體實施方案中,該靶向染色體序列是失活的。在證實已經修飾了感興趣的染色體序列后,可以分離單個細胞克隆并且進行基因分型(通過DNA測序和/或蛋白質分析)。包含一個經修飾的染色體序列的細胞可以進行一輪或多輪額外的靶向基因組修飾以修飾其他染色體序列(例如,參見實施例1)。(b)RNA干擾在另一個實施方案中,可以使用能抑制靶mRNA或轉錄物的表達的RNA干擾(RNAi)劑來制備該抗病毒細胞系。該RNAi劑可能引起靶mRNA或轉錄物的裂解。或者,該RNAi劑可以防止或破壞靶mRNA翻譯成蛋白質。在一些實施方案中,RNAi劑可以是短干擾RNA(siRNA)。一般來說,siRNA包含長度介于約15至約29個核苷酸范圍內的雙鏈RNA分子。該siRNA的長度可以是約16-18、17-19、21-23、24-27或27-29個核苷酸。在一個具體實施方案中,該siRNA的長度是約21個核苷酸。該siRNA可以任選地進一步包含一個或兩個單鏈懸突,例如在一端或兩端上的3′懸突。該siRNA可以由雜交在一起的兩個RNA分子形成,或替代地,可以由短發夾RNA(shRNA)生成(見下文)。在一些實施方案中,該siRNA的兩個鏈是完全互補的,使得兩個序列之間所形成的雙鏈體中不存在錯配或隆凸。在其他實施方案中,該siRNA的兩個鏈是基本上互補的,使得兩個序列之間所形成的雙鏈體中存在一個或多個錯配和/或隆凸。在某些實施方案中,該siRNA的5′端中的一個或兩個具有磷酸酯基,而在其他實施方案中,該5′端中的一個或兩個缺乏磷酸酯基。在其他實施方案中,該siRNA的3′端中的一個或兩個具有羥基,而在其他實施方案中,該5′端中的一個或兩個缺乏羥基。該siRNA中被稱為“反義鏈”或“引導鏈”的一個鏈包括能與靶轉錄物雜交的部分。在某些實施方案中,該siRNA的反義鏈與靶轉錄物的一個區域完全互補,即,其在介于約15至約29個核苷酸之間長、優選地至少16個核苷酸長且更優選地約18-20個核苷酸長的靶區域上不具有單個錯配或隆凸的情況下與靶轉錄物雜交。在其他實施方案中,該反義股與靶區域基本上互補,即,由該反義股和該靶轉錄物形成的雙鏈體中可能存在一個或多個錯配和/或隆凸。典型地,使siRNA靶向靶轉錄物的外顯子序列。本領域技術人員應熟悉設計針對靶轉錄物的siRNA的程序、算法和/或商業服務。一個示例性實例是RosettasiRNADesignAlgorithm(RosettaInpharmatics,NorthSeattle,WA)和siRNA(Sigma-A1drich,St.Louis,MO)。可以使用本領域技術人員眾所周知的方法在活體外酶促合成該siRNA。或者,可以使用本領域中眾所周知的寡核苷酸合成技術化學合成該siRNA。在其他實施方案中,RNAi劑可以是短發夾RNA(shRNA)。一般來說,shRNA是包含可雜交或能夠雜交以形成長度足以介導RNA干擾(如以上所描述)的雙鏈結構的至少兩個互補部分和形成了連接形成該雙鏈體的shRNA區域的環的至少一個單鏈部分的RNA分子。該結構還被稱為莖-環結構,其中該莖是雙鏈體部分。在一些實施方案中,該結構的雙鏈體部分是完全互補的,使得shRNA的雙鏈體區域中不存在錯配或隆凸。在其他實施方案中,該結構的雙鏈體部分是基本上互補的,使得shRNA的雙鏈體部分中存在一個或多個錯配和/或隆凸。該結構的環可以是約1至約20個核苷酸長,優選地約4至約10個左右核苷酸長,且更優選地約6至約9個核苷酸長。該環可以位于與靶轉錄物互補的區域(即,shRNA的反義部分)的5′或3′端。該shRNA可以進一步包含處于5′或3′端上的懸突。該可選懸突可以是約1至約20個核苷酸長,且更優選地約2至約15個核苷酸長。在一些實施方案中,該懸突包含一個或多個U殘基,例如介于約1個與約5個之間的U殘基。在一些實施方案中,該shRNA的5′端具有磷酸酯基,而在其他實施方案中則不然。在其他實施方案中,該shRNA的3′端具有羥基,而在其他實施方案中則不然。一般來說,通過保守細胞RNAi機制將shRNA處理成siRNA。因此,shRNA是siRNA的前驅物,并且類似地能夠抑制與shRNA的一部分(即,shRNA的反義部分)互補的靶轉錄物的表達。本領域技術人員應熟悉用于設計和合成shRNA的可用資源(如以上所詳述)。在又其他實施方案中,該RNAi劑可以是RNAi表達載體。典型地,RNAi表達載體被用于細胞內(活體內)合成RNAi劑,諸如siRNA或shRNA。在一個實施方案中,使用含有兩個啟動子的單個載體來轉錄兩個獨立的互補siRNA鏈,各啟動子指導單個siRNA鏈的轉錄(即,各啟動子被可操作地連接到該siRNA的模板,使得可以發生轉錄)。該兩個啟動子可以呈相同取向,在這種情況下,各啟動子可操作地連接到互補siRNA鏈之一的模板。或者,該兩個啟動子可以呈相反的取向,從而側接單個模板,以便啟動子的轉錄可合成兩個互補siRNA鏈。在另一個實施方案中,該RNAi表達載體可以含有驅動包含兩個互補區域的單個RNA分子的轉錄,從而使得轉錄物形成shRNA的啟動子。本領域技術人員應了解,優選在活體內通過多于一個轉錄單元的轉錄來產生siRNA和shRNA劑。一般來講,用于指導一個或多個siRNA或shRNA轉錄單元的活體內表達的啟動子可能是針對RNA聚合酶III(PolIII)的啟動子。某些PolIII啟動子,諸如U6或H1啟動子,并不需要所轉錄區域內的順式作用調節元件,且因此,在某些實施方案中是優選的。在其他實施方案中,針對PolII的啟動子可以用于驅動一個或多個siRNA或shRNA轉錄單元的表達。在一些實施方案中,可以使用組織特異性、細胞特異性或可誘導性PolII啟動子。可以使用標準重組DNA方法來產生為合成siRNA或shRNA提供模板的構建體,并且插入到多種適于在真核細胞中表達的不同載體中的任一種中。重組DNA技術描述于以下文獻中:Ausubel等,2003,同上和Sambrook&Russell,2001,同上。本領域技術人員還應了解,載體可以包含額外的調節序列(例如,終止序列、翻譯控制序列等),以及可選標記序列。DNA質粒在本領域中是已知的,包括基于pBR322、PUC等等的那些。由于許多表達載體已經含有合適的啟動子,所以可能只需要將編碼感興趣的RNAi劑的核酸序列插入在相對于該啟動子而言適當的位置上。病毒載體還可以用于提供RNAi劑的細胞內表達。合適的病毒載體包括逆轉錄病毒載體、慢病毒載體、腺病毒載體、腺相關病毒載體、皰疹病毒載體等等。在一個具體實施方案中,該RNAi表達載體是shRNA慢病毒基載體或慢病毒顆粒,諸如TRCshRNA產品(Sigma-Aldrich)中所提供的那個。可以使用本領域技術人員眾所周知的方法將該RNAi劑或RNAi表達載體引入該細胞中。這類技術描述于例如以下文獻中:Ausubel等,2003,同上;或Sambrook&Russell,2001,同上。在某些實施方案中,將該RNAi表達載體(例如病毒載體)穩定地整合到該細胞的基因組中,以便在隨后的細胞世代中破壞Mgat1表達。(c)位點特異性重組在替代實施方案中,可以使用位點特異性重組技術來制備該病毒抗性細胞系。舉例來說,可以使用位點特異性重組技術來缺失所有或部分感興趣的染色體序列,或向感興趣的染色體序列中引入單核苷酸多態性(SNP)。在一個實施方案中,使用Cre-loxP位點特異性重組系統、Flp-FRT位點特異性重組系統或其變化形式來靶向感興趣的染色體序列。這類重組系統可購自市面,并且這些技術的額外教授內容見于例如Ausubel等,2003,同上。定義除非另外定義,否則本文中所使用的所有技術和科學術語都具有本發明所屬領域的技術人員通常所理解的含義。以下參考文獻給本領域技術人員提供了本發明中所使用的許多術語的一般定義:Singleton等,DictionaryofMicrobiologyandMolecularBiology(第2版,1994);TheCambridgeDictionaryofScienceandTechnology(Walker編,1988);TheGlossaryofGenetics,第5版,R.Rieger等(編),SpringerVerlag(1991);和Hale&Marham,TheHarperCollinsDictionaryofBiology(1991)。如本文中所使用,除非另外規定,否則以下術語具有賦予它們的含義。當介紹本發明的要素或其優選實施方案時,冠詞“一個”、“一種”、“該”和“所述”意圖指存在一個或多個要素。術語“包含”、“包括”和“具有”意圖是包括性的,并且意指可能存在除了所列出的要素以外的額外要素。如本文中所使用,“缺乏”是指靶向酶或蛋白質的水平有所降低或不可檢測,或者靶向酶或蛋白質的活性有所降低或不可檢測。如本文中所使用,術語“內源序列”是指對細胞來說是天然的染色體序列。術語“外源序列”是指對細胞來說不是天然的染色體序列,或被移動到不同的染色體位置的染色體序列。“經基因修飾的”細胞是指基因組已經被修飾的細胞,即,該細胞至少含有已經過工程改造而含有至少一個核苷酸的插入、至少一個核苷酸的缺失和/或至少一個核苷酸的取代的染色體序列。術語“基因組修飾”和“基因組編輯”是指藉以改變特定染色體序列,使得該染色體序列被修飾的方法。該染色體序列可以經過修飾以包含至少一個核苷酸的插入、至少一個核苷酸的缺失和/或至少一個核苷酸的取代。經修飾的染色體序列是失活的,從而不產生產物。或者,該染色體序列可以經過修飾,從而產生經改變的產物。如本文中所使用的“基因”是指編碼基因產物的DNA區(包括外顯子和內含子),以及調節基因產物的產生的所有DNA區域,無論這類調節序列是否與編碼序列和/或所轉錄的序列相鄰。因此,基因包括但未必限于啟動子序列、終止子、翻譯調節序列(諸如核糖體結合位點和內部核糖體進入位點)、增強子、沉默子、隔離子、邊界元件、復制起點、基質附著位點和基因座控制區。術語“異源”是指對于感興趣的細胞或物種來說不是天然的實體。術語“核酸”和“多核苷酸”是指呈線性或環狀構象的脫氧核糖核苷酸或核糖核苷酸聚合物。出于本公開的目的,這些術語不應被視為對于聚合物的長度具有限制性。該術語可以涵蓋天然核苷酸的已知類似物,以及在堿基、糖和/或磷酸部分中經修飾的核苷酸。一般來說,特定核苷酸的類似物具有相同的堿基配對特異性;即,A的類似物將與T堿基配對。核酸或多核苷酸的核苷酸可以通過磷酸二酯、硫代磷酸酯、亞磷酰胺、二氨基磷酸酯鍵或其組合來連接。.術語“核苷酸”是指脫氧核糖核苷酸或核糖核苷酸。該核苷酸可以是標準核苷酸(即,腺苷、鳥苷、胞苷、胸苷和尿苷)或核苷酸類似物。核苷酸類似物是指具有經修飾的嘌呤或嘧啶堿基或者經修飾的核糖部分的核苷酸。核苷酸類似物可以是天然存在的核苷酸(例如,肌苷)或非天然存在的核苷酸。核苷酸的糖或堿基部分的修飾的非限制性實例包括乙酰基、氨基、羧基、羧甲基、羥基、甲基、磷酰基和巰基的添加(或去除),以及用其他原子對堿基的碳原子和氮原子的取代(例如,7-脫氮嘌呤)。核苷酸類似物還包括二脫氧核苷酸、2′-O-甲基核苷酸、鎖核酸(LNA)、肽核酸(PNA)和嗎啉基。術語“多肽”和“蛋白質”可以互換使用來指氨基酸殘基的聚合物。如本文中所使用,術語“靶位點”或“靶序列”是指定義欲修飾或編輯的且對靶向核酸內切酶進行工程改造以識別并結合其(條件是存在足以結合的條件)的染色體序列的一部分的核酸序列。術語“上游”和“下游”是指核酸序列中相對于固定位置的位置。上游是指相對于該位置是5′(即,靠近該鏈的5′端)的區域,而下游是指相對于該位置是3′(即,靠近該鏈的3′端)的區域。如本文中所使用,“病毒抗性”是指細胞抵抗病毒感染的能力。更具體來說,與未經修飾的親本細胞系相比,在本文中所公開的經工程改造的細胞系中,病毒進入和/或病毒繁殖有所減少或被消除。用于確定核酸和氨基酸序列同一性的技術在本領域中是已知的。典型地,這類技術包括確定基因的mRNA的核苷酸序列和/或確定由其編碼的氨基酸序列,并且將這些序列與第二核苷酸或氨基酸序列相比較。還可以用這種方式確定并且比較基因組序列。一般來說,同一性是指兩個多核苷酸或多肽序列分別的確切核苷酸與核苷酸或氨基酸與氨基酸對應性。兩個或更多個序列(多核苷酸或氨基酸)可以通過確定其同一性百分比來進行比較。兩個序列(不論是核酸序列還是氨基酸序列)的同一性百分比是兩個對齊的序列之間的確切匹配數除以較短序列的長度并乘以100。Smith和Waterman,AdvancesinAppliedMathematics2:482-489(1981)的局部同源性算法提供了核酸序列的近似比對法。這種算法可以通過使用評分矩陣而應用于氨基酸序列,該評分矩陣是由Dayhoff,AtlasofProteinSequencesandStructure,M.O.Dayhoff編,5增刊3∶353-358,NationalBiomedicalResearchFoundation,Washington,D.C.,USA開發,且由Gribskov,Nucl.AcidsRes.14(6):6745-6763(1986)正規化。用于確定序列同一性百分比的這種算法的一種示例性實現方式是由“BestFit”實用應用程序中的GeneticsComputerGroup(Madison,Wis.)提供。用于計算序列之間的同一性或相似性百分比的其他合適的程序在本領域中一般是已知的,例如,另一個比對程序是以缺省參數使用的BLAST。舉例來說,可以使用BLASTN和BLASTP,使用以下缺省參數:遺傳密碼=標準;過濾器=無;鏈=兩個;截止值=60;期望值=10;矩陣=BLOSUM62;描述=50個序列;分選=高評分;數據庫=非冗余,GenBank+EMBL+DDBJ+PDB+GenBankCDS翻譯+Swiss蛋白+Spupdate+PIR。這些程序的細節可以在GenBank網站上找到。相對于本文中所描述的序列,所期望的序列同一性程度的范圍是大約80%至100%和介于其之間的任何整數值。典型地,序列之間的同一性百分比是至少70-75%,優選地80-82%,更優選地85-90%,甚至更優選地92%,又更優選地95%,且最優選地98%序列同一性。由于可以在不偏離本發明的范圍的情況下在上述細胞和方法中進行各種改變,所以意圖以上描述中和以下給出的實施例中所含有的所有內容都應該被解釋為說明性的而不具有限制意義。實施例以下實施例說明了本發明的某些方面。實施例1:靶向基因經修飾的CHO細胞系的制備采用ZFN介導的基因修飾技術來使編碼涉及N連接型或O連接型糖基化反應的酶或蛋白質的基因失活(即,敲除)。一般來說,使用專有算法來設計靶向感興趣的基因的編碼區內的特定位點的數對ZFN。使用標準程序來制備ZFN表達構建體,并且使用活體外轉錄、mRNA聚腺苷酸化和封端方法,由如敲除鋅指核酸酶(ZFN)(Sigma-Aldrich)產品信息中所描述的ZFN質粒DNA產生ZFNmRNA。簡要地說,將質粒ZFNDNA線性化,并且使用苯酚/氯仿DNA提取進行純化。使用MessageMaxTMT7ARCA-CappedMessageTranscriptionKit(CellScriptInc.)對線性化DNA進行封端。使用Poly(A)PolymeraseTailingKit(EpiCentre)來添加聚(A)尾。使用MEGAclearTM試劑盒(Ambion)來純化ZFNmRNA。將親本細胞作為懸浮液培養物維持在CHOCD融合培養基(Sigma-Aldrich)中。在轉染前一天,將細胞以0.5×106個細胞/mL接種在生物反應器管中。典型地,各轉染含有處于150μL生長培養基中的1×106個細胞和5μgZFNDNA或mRNA。通過在0.2cm試管中在140V和950uF下電穿孔來進行轉染。將已電穿孔的細胞放在處于6孔板靜態培養中的2mL生長培養基中。在轉染后第3天和第10天,將細胞從培養中取出,并且使用GeneEluteTM哺乳動物基因組DNA微型制備試劑盒(Sigma-Aldrich)分離基因組DNA。如敲除ZFN產品信息中所描述,使用Cel-1核酸酶測定來驗證ZFN誘導的裂解。進行該測定以確定如先前所描述的ZFN介導的基因突變的效率(Miller等,Nat.Biotechnol.2007,25:778-785)。該測定法檢測由于對ZFN誘導的DNA雙鏈斷裂的非同源末端連接(NHEJ)介導的不完美修復而來源于野生型的靶向基因座的等位基因。對來自經ZFN處理的細胞池的靶向區域進行PCR擴增產生了野生型(WT)與突變擴增子的混合物。對該混合物進行的熔融和重退火導致了WT和突變等位基因的異源雙鏈體之間的錯配形成。通過Surveyor核酸酶Cel-1使錯配位點上所形成的DNA“泡”裂解,并且可以通過凝膠電泳來拆分裂解產物。在證實ZFN活性后,使用有限稀釋對經ZFN轉染的細胞進行單細胞克隆。為此,使用80%CHO無血清克隆培養基、20%條件培養基和4mML-谷氨酰胺的混合物將細胞以約0.5個細胞/孔的近似密度鋪板。分別在鋪板后第7天和第14天以顯微鏡驗證克隆度和生長。通過PCR和DNA測序對有生長的克隆進行擴增和基因分型。Mgat1KO細胞系。作為復雜N聚糖合成的一部分,Mgat1將GlnNac添加到Man5GlcNAc2N連接型多糖結構。設計一對ZFN以靶向CHOMgat1基因中的5′-AACAAGTTCAAGTTCccagcaGCTGTGGTAGTGGAGGAC-3′(SEQIDNO:9;ZFN結合位點以大寫字母表示且裂解位點以小寫字母表示)。親本細胞系是CHOK1(GS-/-)(SigmaAldrich),其中谷氨酸合成酶被敲除。該親本細胞系產生野生型N-聚糖和O-聚糖結構。基本上如以上所詳述,將CHOK1(GS-/-)細胞系用Mgat1ZFNDNA進行轉染。Cel-1測定證實轉染后第3天和第10天都存在兩個裂解片段,220和197bp,從而表明ZFN活性。經鑒定,單細胞克隆在一個等位基因中具有介于2bp至55bp范圍內的缺失(未檢測第二個等位基因)。該細胞系產生了以五個甘露糖殘基封端的截短型N連接型結構(即,Man5NeuAc2糖型)和野生型O聚糖結構。COSMCKO細胞系。O-糖基化中最常見的第二生物合成步驟是核心-1伸長。核心-1伸長是由需要專用伴侶COSMC以發揮功能的單一酶C1GalT1(akaT-synthase)催化。COSMC是看起來特異性結合T-合酶且確保其在高爾基體中具有充分活性的ER蛋白。為了破壞COSMC基因,將CHOK1(GS-/-)細胞用編碼經設計以靶向CHOCOSMC基因中的序列5′-GCCTTCTCAGTGTTCCGGAaaagtgTCCTGAACAAGGTGGGAT-3′(SEQIDNO:10)的ZFN的DNA或RNA加以轉染。Cel-1核酸酶測定證實經ZFN轉染的細胞中存在三個裂解片段(即,318bp、184bp、134bp)。分離在COSMC的一個等位基因中具有4bp缺失(未檢測第二個等位基因)的單細胞克隆。該細胞系產生了截短型(即,未成熟)O-聚糖結構和野生型N-聚糖。COSMC/Mgat3KO細胞系。設計一對ZFN以靶向Mgat3的編碼區中的5′-TTCCTGGACCACTTCCCAcccggtGGCCGGCAGGATGGC-3′(SEQIDNO:11)。將以上詳述的COSMCKO細胞系用如以上詳述的ZFNDNA進行轉染。在證實ZFN裂解之后,分離單細胞克隆。測序顯示,突變克隆在Mgat3基因中具有9、10、11或41bp缺失。該細胞系產生了野生型N-聚糖和截短型O-聚糖(即,類似于親本細胞系)。COSMC/Mgat3/Mgat5KO細胞系。將以上詳述的COSMC/Mgat3KO細胞系用編碼經設計以靶向Mgat5的編碼區中的5′-TTCTGCACTTCACCATCCAgcagcgGACTCAGCCTGAGAGCAGCT-3′(SEQIDNO:12)的ZFN的質粒DNA進行轉染。分離在Mgat5基因中具有129bp缺失的單細胞克隆。該細胞系產生了具有較少側分支的N-聚糖和截短型O-聚糖。實施例2:病毒感染和病毒抗性測試測定使上述CHO細胞系生長且測試其在用原型MVM病毒(病毒株MVMp)攻擊后支持或抵抗感染的能力。簡要地說,使細胞在適當的培養基中生長,且以1或10的感染復數(MOI)加入MVMp病毒,并且在測定之前將已感染的細胞再孵育24、48或72小時。作為對照,在無病毒的情況下使細胞生長且進行孵育。未感染的細胞也用酶神經氨酸酶加以處理,以去除來自表面聚糖(N連接型和O連接型)的末端唾液酸,且隨后以所指示的MOI進行感染。用肉眼觀察已感染的和未感染的細胞中細胞病變效應(CPE)的存在,并且在所指示的時間點,通過離心收集細胞。使用對總基因組DNA的南方印跡分析和使用抗病毒蛋白抗體的西方免疫印跡分析來篩檢病毒DNA感染性和產量。對于南方分析,收集來自24h時獲取的兩份樣品的細胞小球且分離總基因組DNA。通過Nanodrop光譜來定量DNA,并且將樣品正規化以確保瓊脂糖凝膠上具有相等負載,以便進行大小分級。將經過大小分級的DNA轉移到帶電膜上(南方印跡),并且使用32P標記的病毒DNA探針對該膜探測病毒DNA合成。對特定32P標記的病毒雙鏈DNA譜帶的定量是通過磷成像獲取且相對值報告在表1中。對于西方分析,將24h時收集的細胞小球溶解在SDS緩沖液中,并且使用SDS-PAGE來分離蛋白質。在電泳后,將蛋白質轉移到PVDF膜上,加以阻斷并且使用抗NS1抗體針對病毒NS1蛋白的存在進行免疫印跡(西方免疫測定法)。通過西方印跡檢測到的病毒蛋白水平在表2中表示。當感染了病毒的MVMp病毒株時,該親本細胞系CHOK1(GS-/-)(即,具有野生型聚糖結構)表現出了正如所預期的經典感染性和病毒DNA產量和蛋白質合成。當細胞在任一MOI下被感染時,感染后24小時病毒DNA和病毒蛋白產物顯而易見。在稍后的時間點還見到了病毒產物的強產生。正如所預期,不管時間點如何,未受感染的野生型細胞都沒有表現出感染的證據。當用酶神經氨酸酶(NA)處理野生型細胞以去除細胞表面唾液酸且隨后用MVMp感染細胞時,還觀察到病毒產量減少(表明感染減輕)(介于從MOI=10時的5.32倍至MOI=1時的7.34倍的范圍內)。盡管經NA處理的細胞仍表現出對感染輕微敏感性,但已知CHO細胞在這種處理后快速再生出唾液酸(SA)結構。因此,所見到的低感染水平可能來自已再生出末端SA聚糖且因此為病毒提供入口的細胞。CHOMgat1基因失活且不產生Mgat1酶的Mgat1KO細胞的病毒感染只引起輕微抗性(例如,降低2.1至2.7倍,如通過對印跡進行磷成像所測量)。因為該細胞系具有截短型N-聚糖,所以這些結果表明,具有2-3連接型唾液酸的高階N-聚糖受體可能在最初病毒衣殼結合和病毒進入細胞中只能發揮次要作用。當COSMCKO細胞感染有MVMp病毒時,該細胞系對病毒感染表現出顯著抗性。抗性倍數(當與野生型細胞系相比時)在5.5倍(MOI=10)至190倍(MOI=1)的范圍內。靶向Mgat3基因(假定是CHO細胞中的假基因)和Mgat5基因(負責高階N連接型分支)的額外基因敲除得到了類似的結果。西方印跡分析得到了類似的結果,表明當O-聚糖結構被截短時發生病毒抗性。這些研究揭示了破壞唾液酸受體可大幅減少MVM結合和/或進入細胞。實施例3:其他COSMCKO和Slc35A1KO細胞系的產生如以上實施例1中所描述,使用CHOK1(GS-/-)細胞和經設計以靶向CHOCOSMC基因的外顯子2中的序列5′-GCCTTCTCAGTGTTCCGGAaaagtgTCCTGAACAAGGTGGGAT-3′(SEQIDNO:10)的一對ZFN來產生新的COSMCKO細胞系克隆。Cel-1核酸酶測定證實經ZFN轉染的細胞中存在三個裂解片段(即,318bp、184bp、134bp)。分離五個單細胞克隆,且測序顯示1至12bp的缺失,如以下所示。克隆基因型COSMCF072bp缺失COSMCG031bp插入COSMCH041bp插入COSMCA099bp缺失COSMCH0512bp缺失使用標準程序對克隆F07進行進一步修飾以表達人IgG。在所鑒定的許多克隆中,分離了兩個產生IgG的克隆(鑒定為71H1、71C3)以便進一步測試(見下文)。使用經設計以靶向5′-AGCTTATACCGTAGCTTTaagataCACAAGGACAACAGCTAAA-3′(SEQIDNO:13)的ZFN或經設計以靶向CHOSlc35A1基因的外顯子1中的5′-TTCAAGCTATACTGCTTGGCAGTGATGACTCTGGTGGCT-3′(SEQIDNO:17)的ZFN將編碼核苷酸糖轉運子(CMP-唾液酸轉運子)的Slc35A1基因從CHOK1(GS-/-)細胞中敲除。Cel-1核酸酶測定證實經ZFN轉染的細胞中存在兩個裂解片段。分離出一個單細胞克隆(B12),且測序顯示了在ZFN結合位點周圍的1bp缺失。Slc35A1KO細胞系形成了不具有末端唾液酸的N連接型和O連接型聚糖結構。利用生物素標記的山槐凝集素II(MALII;20μg/mL)和AlexaFluor647標記的鏈霉親和素(5μg/mL)的染色顯示了COSMCKO克隆F07、COSMCKO克隆G03和Slc35A1KO細胞系中的染色與親本細胞系相比顯著減少(表明KO細胞系中不存在末端唾液酸殘基)。實施例4:COSMCKO和Slc35A1KO細胞系對MMV病毒的抗性基本上如以上實施例2中所述,用MVMp病毒以MOI0.3感染野生型(即,CHOZNGS-/-)、COSMCKO(以上實施例1和實施例3中所產生的)和Slc35A1KO(以上實施例3中所產生的)細胞。通過南方分析(基本上如以上所描述)和標準噬菌斑測定法來測定感染。如圖1中所示,野生型細胞表現出高水平的病毒DNA,而Slc35A1KO和COSMCKO細胞系具有非常低水平的病毒DNA;COSMCF07KO和COSMCG03KO克隆具有低水平的病毒DNA;且具有12bp缺失的COSMCH05FO克隆具有與親本細胞系類似的水平的病毒DNA。由于H05中的缺失是同框的,所以該細胞表現出接近野生型水平的病毒敏感性并不奇怪。噬菌斑測定結果示于圖2中。Slc35A1KO、COSMCKO、COSMCF07KO和COSMCG03KO細胞具有極低的病毒水平。使用野生型(即,CHOZNGS-/-,也稱為2E3)、COSMCKO克隆F07和G03以及Slc35A1KO克隆B12進行了額外的病毒抗性測試。使細胞在補充有6mML-谷氨酰胺的培養基中生長且用MMVp以MOI1或8進行感染,并且在合適的條件下孵育。在0、24、48、72、96和120小時取出細胞樣品;用錐蟲藍染色來測定細胞活力,并且通過qPCR來確定MMV定量。細胞活力呈現于圖3中。在感染后120小時,野生型細胞(即,2E3)中細胞活力降至約50%(參見圖A),而在COSMC克隆F07中,至少93%的細胞在感染后120小時是活的(參見圖B)。圖4示出了在野生型(2E3)和COSMC克隆F07中以MOI1(參見圖A)或MOI8(參見圖B)進行MMV感染之后細胞相關病毒(每個細胞的病毒基因組拷貝(vgc))的時間過程(計算是基于各感染細胞可以產生2×104vgc的假設)。以下呈現已感染的細胞在各條件下的級分。在時間-3小時用MMVp以MOI0.3或0.03感染野生型(即,2E3)、COSMCKO克隆F07、G03和H04以及Slc35A1KO克隆B12細胞。在時間0小時,用生長培養基將細胞洗滌三次,然后孵育21小時(即,單個復制周期)。通過在0和21小時確定細胞相關病毒來測定病毒復制。如圖5中所示,病毒復制在COSMCKO細胞系中有所減少且在Slc35A1KO細胞系中被消除。實施例5:COSMCKO和Slc35A1KO細胞系對呼腸孤病毒3的抗性在時間-3小時用呼腸孤病毒3以兩個稀釋度感染野生型(即,2E3)、COSMCKO克隆F07和Slc35A1KO克隆B12細胞(TCID50=5.6E+07和5.6E+06)。在時間0小時,將細胞洗滌三次,然后孵育24小時(即,單個復制周期)。通過在0和24小時確定細胞相關病毒來測定病毒復制。在24小時,細胞相關病毒的水平在COSMCKO克隆中大幅降低,且在Slc35A1KO克隆中幾乎被消除(參見圖6)。實施例6:COSMCKO和Slc35A1KO細胞系的生長測定在不存在或存在MVMp病毒(MOI0.1)的情況下使野生型(即,CHOZNGS-/-)、COSMCKO克隆F07和G03以及Slc35A1KO克隆B12細胞生長8至10天。通過在第0天、第1天、第2天、第3天、第6天、第7天、第8天和第10天測量活細胞密度(通過錐蟲藍染色)來監測細胞生長。如圖7的圖A中所示,各種KO細胞在存在或不存在病毒的情況下具有類似的生長概況,表明了對病毒注入的抗性。與此相反,當與未感染的培養物相比時,野生型細胞表現出經典感染性、受損的生長和低細胞活力。基本上如以上所詳述在不存在或存在病毒的情況下監測COSMCKO克隆F07的野生型和IgG產生克隆(即,71H1和71C3)的細胞生長。如圖7的圖B所示,產生IgG的KO細胞系也對病毒感染表現出顯著抗性。已感染的培養物以與未感染的培養物類似的速率生長且達到峰值細胞密度。這些數據表明,分泌細胞表面IgG對COSMCKO親本所表現出的病毒抗性程度沒有明顯影響。雖然產生IgG的細胞系與野生型細胞相比以較慢速率增長,但兩種IgG生產者都對病毒感染表現出了抗性(即,當與未感染的培養物相比時,沒有差別)。實施例7:St3Gal4KO細胞系的產生和細胞生長測定基本上如實施例1中所描述,使用經設計以靶向CHOSt3Gal4基因中的5′-GGCAGCCTCCAGTGTCGTCgttgtgTTGTGGTGGGGAATGGGC(SEQIDNO:14)的ZFN來產生St3Gal4KO細胞。Cel-1核酸酶測定證實經ZFN轉染的細胞中存在三個裂解片段(即,344bp、210bp和135bp)。分離出四個單細胞克隆,且測序顯示了以下突變。St3Gal4KO細胞具有較低水平的2-3連接型唾液酸結構。克隆等位基因1基因型等位基因2基因型St3Gal41B084bp插入5bp缺失St3Gal47D102bp缺失8bp缺失St3Gal41B105bp缺失11bp缺失St3Gal41H113bp插入11bp缺失在不存在或存在MVMp病毒(MOI0.1)的情況下使St3Gal4KO(即,克隆7D10、1B8和1B10)和野生型細胞生長,并且監測細胞生長,持續9天。St3Gal4KO細胞也對病毒感染表現出顯著抗性,如圖8中所示。已感染的KO培養物以與未感染的KO培養物類似的速率生長且達到峰值細胞密度。這些研究顯示了破壞細胞表面上的特定2-3連接型唾液酸結構似乎也能大幅減少MVM進入這種細胞。實施例8:St3Gal4和St3Gal6雙KO細胞系的產生使用St3Gal4KO(即,克隆7D10、1B8和1B10)細胞系作為起始細胞,以產生也含有敲除的St3Gal6基因的細胞系。ZFN被設計為靶向5′-CGGTACCTCTGATTTTGCTttgccCTATGGGACAAGGCC-3′(SEQIDNO:15),且基本上如實施例1中所描述來進行基因編輯。Cel-1核酸酶測定證實經ZFN轉染的細胞中存在三個裂解片段(即,308bp、171bp和137bp)。分離出六個單細胞克隆,且測序顯示了以下突變。實施例9:C1GalT1KO細胞系的產生基本上如實施例1中所描述,使用經設計以靶向5′-ACCCTCATGCTAGACatttaGATGATAACGAACCCAGTC-3′(SEQIDNO:16)的ZFN來敲除CHOK1(GS-/-)細胞中的C1GalT1基因。Cel-1核酸酶測定證實經ZFN轉染的細胞中存在兩個裂解片段(即,223bp和148bp)。分離出七個單細胞克隆,且測序顯示了以下突變。C1GalT1克隆等位基因1基因型等位基因2基因型2A88bp缺失8bp缺失2A115bp缺失90bp插入2C128bp缺失未檢測到2G125bp缺失未檢測到3D128bp缺失未檢測到3E61bp缺失2bp缺失和97bp插入3F25bp缺失5bp缺失和31bp插入利用生物素標記的MALII和AlexaFluor647標記的鏈霉親和素的染色顯示了C1GalT1KO克隆2C12中的染色與親本細胞系相比顯著減少。實施例10:過度表達St6Gal1的細胞系的產生因為假設MVM病毒不結合α-2,6連接型唾液酸,所以產生了過度表達St6Gal1的CHO細胞系。中國倉鼠St6Gal1的編碼序列是獲自GenBank(AB492855)和chogenome.orgAQ2(AFTD01061789和AFTD01061790)。批量合成Kozak序列(5′-GCCGCCACCAatg-3′;SEQIDNO:18)被添加至5′-未翻譯區(UTR)的開放閱讀框。將所合成的片段克隆到表達載體pJ602(DNA2.0;MenloPark,CA)中。用該構建體轉染(通過電穿孔)CHO(GS-/-)宿主細胞系和表達IgG的CHO細胞系。使用FACSAriaTMIII細胞分選儀分離出單細胞克隆。為此,用可結合α-2,6連接型唾液酸的FITC綴合型黑接骨木凝集素(FITC-SNA)將細胞染色,并且將具有前5%熒光的細胞以1個細胞/孔鋪板并培養。在用可結合α-2,3連接型唾液酸的經生物素標記的MALII和AlexaFluor647標記的鏈酶親和素染色之后,在MACSQuantVR分析儀(MiltenyiBiotec,SanDiego,CA)上對單細胞克隆進行雙色FACS分析。過度表達St6Gal1的單細胞克隆與未經轉染的親本細胞系相比具有增高的FITC與AlexaFluor之比。從兩個過度表達St6Gal1的克隆(即,克隆31和克隆32)和親本細胞克隆中分離出IgG。根據標準程序對IgG或總細胞蛋白提取物進行還原和羧酰胺基甲基化,隨后在37℃下進行胰蛋白酶處理過夜(12-16h)。通過在100℃下加熱5分鐘將胰蛋白酶滅活。利用C18SPE濾筒(Waters,300mg填料)進行片段的純化。在用5%乙酸(AcOH)洗滌之后,依次在20%異丙醇/5%AcOH、40%異丙醇/5%AcOH和100%異丙醇中洗脫肽/糖肽。干燥洗脫液以減少體積,在含有PNG酶F的磷酸鹽緩沖液中重構,并且在37℃下孵育過夜。使用C18濾筒來純化所釋放的聚糖,進行全甲基化且稀釋至1mM碳酸鋰/50%MeOH中,并且以0.5mL/min的流速直接輸注到LTQOrbitrapDiscovery質譜儀(ThermoScientific)中以便進行納米噴霧電離。在30,000分辨率下獲得了各樣品的完整傅立葉變換質譜儀(FTMS)譜圖以確定哪些聚糖含有唾液酸。通過MSn分析來確定唾液酸化聚糖的唾液酸鍵聯。在離子阱內對各樣品進行多個離子選擇和碎裂步驟,以使復合型聚糖分解成單個半乳糖,然后觀察碎裂模式。GS(-/-)宿主細胞系與兩個過度表達St6Gall的細胞系(即,克隆31和32)的N-聚糖分布之間存在驚人的差異。具體來說,在宿主細胞系中沒有鑒定出唾液酸化的聚糖,這是由于其豐度較低。相比之下,在兩個過度表達St6Gal1的細胞系中都鑒定出了單唾液酸化、二唾液酸化、三唾液酸化和四唾液酸化N-聚糖。具體來說,克隆32中除了一個唾液酸化群體以外的所有唾液酸化群體都表現出含有α-2,3鍵聯和α-2,6鍵聯。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1