語句分類方法、系統、電子設備、冰箱及存儲介質與流程
本發明實施例涉及智能家居
技術領域:
,具體涉及一種語句分類方法、系統、電子設備、冰箱及存儲介質。
背景技術:
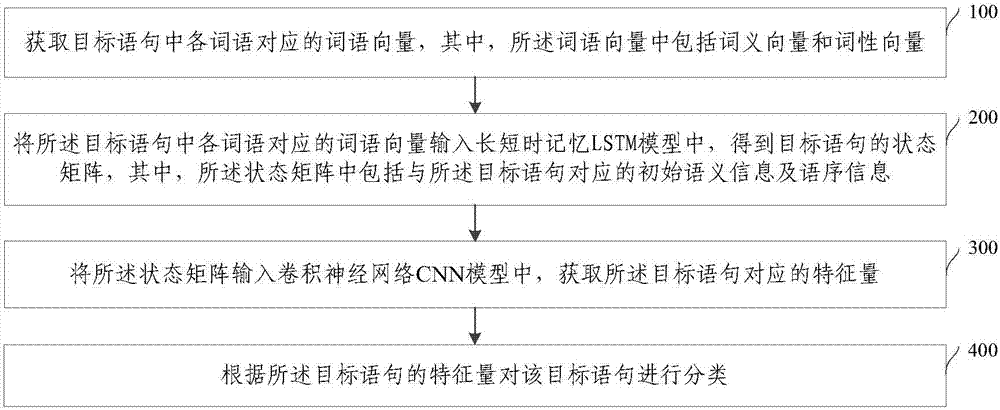
:隨著智能家電和智能手機的推廣使用,人們越來越習慣利用智能家電和智能手機上的語音識別系統或搜索引擎發出問題詢問或對智能家電進行控制。以語音識別系統為例,在將語音識別為語句文本后,需要對語句文本進行類型劃分,在根據語句文本的類型確認獲取對應的答案或操作指令,因此,語句分類的過程是實現智能問答、搜索引擎等語言處理任務的重要步驟。目前的語句文本分類方法為基于深度學習方法對語句進行分類,其中利用卷積神經網絡cnn(convolutionalneuralnetwork)模型,或者,循環神經網絡rnn(recurrentneuralnetwork)模型是較為常見的語句分類方法。但在利用卷積神經網絡cnn模型進行語句分類時,由于只能獲取語句中各詞語的抽象特征,缺少語句中各詞語的語序特征進而造成的語句分類不準確的問題;而在利用循環神經網絡rnn模型進行語句分類時,由于其抽象各詞語特征的能力不如cnn,因也會造成的后續語句分類準確性低的問題。技術實現要素:針對現有技術中的問題,本發明提供一種語句分類方法、系統、電子設備、冰箱及存儲介質,本發明能夠提高對語句分類及語句類型識別的準確性,提升用戶體驗。為解決上述技術問題,本發明提供以下技術方案:第一方面,本發明提供了一種語句分類方法,所述方法包括:獲取目標語句中各詞語對應的詞語向量,其中,所述詞語向量中包括詞義向量和詞性向量;將所述目標語句中各詞語對應的詞語向量輸入lstm模型中,得到目標語句的狀態矩陣,其中,所述狀態矩陣中包括與所述目標語句對應的初始語義信息及語序信息;將所述狀態矩陣輸入卷積神經網絡cnn模型中,獲取所述目標語句對應的特征量;以及,根據所述目標語句的特征量對該目標語句進行分類。進一步地,在所述獲取目標語句中各詞語對應的詞語向量之前,所述方法還包括:對獲取的語句文本進行預處理,并獲取預處理后的各語句中的各詞語對應的詞義向量;通過一定方法生成預處理后的各語句中的各詞語對應的詞性向量;以及,組合各詞語對應的所述詞義向量和詞性向量,得到各詞語對應的詞語向量。進一步地,在所述組合各詞語對應的所述詞義向量和詞性向量,得到各詞語對應的詞語向量之后,所述方法還包括:根據各詞語對應的所述詞語向量,生成關鍵詞向量庫,其中,所述關鍵詞向量庫中存儲有各詞語與其對應的詞語向量間的一一映射關系;相應的,所述獲取目標語句中各詞語對應的詞語向量,包括:根據所述目標語句在所述關鍵詞向量庫中查找得到該目標語句的全部詞語對應的詞語向量。進一步地,所述將所述目標語句中各詞語對應的詞語向量輸入lstm模型中,得到目標語句的狀態矩陣,包括:將與目標語句中各詞語對應的各所述詞語向量依次按序輸入lstm中,獲取所述目標語句對應的初始語義信息及語序信息的隱含狀態;以及,根據所述lstm層提取的隱含狀態,生成所述目標語句的狀態矩陣。進一步地,所述將所述狀態矩陣輸入卷積神經網絡cnn模型中,獲取所述目標語句對應的特征量,包括:將所述狀態矩陣輸入所述卷積神經網絡cnn模型中的卷積層中,獲取目標語句對應的抽象語義信息,且各所述抽象語義信息構成各卷積層的卷積結果;以及,將所述卷積結果輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。進一步地,將所述卷積結果輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量,包括:分別將各卷積層的卷積結果進行合并,得到合并后的卷積結果組;以及,將所述同類型卷積結果組輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。第二方面,本發明提供了一種語句分類系統,所述系統包括:詞語向量獲取模塊,用于獲取目標語句中各詞語對應的詞語向量,其中,所述詞語向量中包括詞義向量和詞性向量;lstm模型處理模塊,用于將所述目標語句中各詞語對應的詞語向量輸入lstm模型中,得到目標語句的狀態矩陣,其中,所述狀態矩陣中包括與所述目標語句對應的初始語義信息及語序信息;cnn模型處理模塊,用于將所述狀態矩陣輸入卷積神經網絡cnn模型中,獲取所述目標語句對應的特征量;語句分類模塊,用于根據所述目標語句的特征量對該目標語句進行分類。進一步地,所述系統還包括:詞義向量獲取單元,用于對獲取的語句文本進行預處理,并獲取預處理后的各語句中的各詞語對應的詞義向量;詞性向量生成單元,用于生成預處理后的各語句中的各詞語對應的詞性向量;詞語向量獲取單元,用于組合各詞語對應的所述詞義向量和詞性向量,得到各詞語對應的詞語向量。進一步地,所述系統還包括:關鍵詞向量庫生成單元,用于根據各詞語對應的所述詞語向量,生成關鍵詞向量庫,其中,所述關鍵詞向量庫中存儲有各詞語與其對應的詞語向量間的一一映射關系;相應的,所述詞語向量獲取模塊用于根據所述目標語句在所述關鍵詞向量庫中查找得到該目標語句的全部詞語對應的詞語向量。進一步地,所述lstm模型處理模塊包括:lstm層處理單元,用于將與目標語句中各詞語對應的各所述詞語向量依次按序輸入長短時記憶lstm中,獲取所述目標語句對應的初始語義信息及語序信息的隱含狀態;狀態矩陣生成單元,用于根據所述lstm層的隱含狀態,生成所述目標語句的狀態矩陣。進一步地,所述cnn模型處理模塊包括:卷積層處理單元,用于將所述狀態矩陣輸入所述卷積神經網絡cnn模型中的卷積層中,獲取目標語句對應的抽象語義信息,且各所述抽象語義信息構成各卷積層的卷積結果;池化層處理單元,用于將所述卷積結果輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。進一步地,所述池化層處理單元包括:合并子單元,用于分別將各卷積層的卷積結果進行合并,得到合并后的卷積結果組;特征量獲取子單元,用于將所述同類型卷積結果組輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。第三方面,本發明提供了一種電子設備,包括:處理器、存儲器和總線;其中,處理器和存儲器通過總線完成相互間的通信;處理器用于調用存儲器中的程序指令,以執行所述的語句分類方法。第四方面,本發明提供了一種冰箱,所述冰箱上設有語音識別系統,且所述語音識別系統中包括一種電子設備;所述電子設備包括:處理器、存儲器和總線;其中,處理器和存儲器通過總線完成相互間的通信;處理器用于調用存儲器中的程序指令,以執行所述的語句分類方法。第五方面,本發明提供了一種非暫態計算機可讀存儲介質,所述非暫態計算機可讀存儲介質存儲計算機指令,所述計算機指令使所述計算機執行所述的語句分類方法。由上述技術方案可知,本發明提供的語句分類方法,首先獲取目標語句中各詞語對應的詞語向量,然后將所述目標語句中各詞語對應的詞語向量輸入lstm模型中,使得lstm模型輸出目標語句的狀態矩陣,再將所述狀態矩陣輸入卷積神經網絡cnn模型中,使得卷積神經網絡cnn模型輸出所述目標語句對應的特征量;相應的,根據所述目標語句的特征量對該目標語句進行分類。可見,本發明實施例提供的語句分類方法,首先通過lstm模型初步獲取目標語句中的各詞語對應的語義和語序信息,在通過卷積神經網絡cnn模型獲取目標語句中的各詞語的更為抽象且準確的語義信息,因而根據本發明實施例提供的方法,在提高了目標語句對應的語義信息的準確性的同時,也通過增加語序信息,提高了對目標語句分類及類型識別的準確性和可靠性,故使得用戶體驗提高。附圖說明為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。圖1是本發明的一個實施例提供的語句分類方法的一種流程圖;圖2是本發明的一個實施例提供的語句分類方法的另一種流程圖;圖3是本發明的一個實施例提供的語句分類方法的再一種流程圖;圖4是本發明的一個實施例提供的語句分類方法中步驟200的一種流程圖;圖5是lstm層提取目標語句的狀態矩陣的示意圖;圖6是本發明的一個實施例提供的語句分類方法中步驟300的一種流程圖;圖7是現有的池化過程示意圖;圖8是本發明的一個實施例提供的語句分類方法中步驟302的一種流程圖;圖9是針對現有的池化過程進行改進的池化過程示意圖;圖10是本發明的另一個實施例提供的語句分類系統的一種結構示意圖;圖11是本發明的另一個實施例提供的語句分類系統的另一種結構示意圖;圖12是本發明的另一個實施例提供的語句分類系統的再一種結構示意圖;圖13是本發明的另一個實施例提供的語句分類系統中rnn模型處理模塊20的一種結構示意圖;圖14是本發明的另一個實施例提供的語句分類系統中cnn模型處理模塊30的一種結構示意圖;圖15是本發明的另一個實施例提供的語句分類系統中池化層處理單元32的一種結構示意圖。具體實施方式為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整的描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。針對現有技術中的問題,本發明提供一種語句分類方法、系統、電子設備、冰箱及存儲介質。可以理解的是,本發明實施例所述的電子設備可以裝設在冰箱等家用電器上。本發明提供的語句分類方法,在提高了目標語句對應的語義信息的準確性的同時,也提供了其語序信息,提高對語句分類及語句類型識別的準確性,故使得用戶體驗提高。下面將通過第一至第五實施例對本發明進行詳細解釋說明。圖1示出了本發明第一個實施例提供的語句分類方法的流程圖,參見圖1,本發明第一個實施例提供的語句分類方法包括如下步驟:步驟100:獲取目標語句中各詞語對應的詞語向量,其中,所述詞語向量中包括詞義向量。在本步驟中,用于對語句進行分類的電子設備接收目標語句,并查找得到將該目標語句中各詞語對應的詞語向量,可以理解的是,用于對語句進行分類的電子設備接收外部處理模塊發送的目標語句的文本,或者,用于對語句進行分類的電子設備直接接收目標語句的語音,并將該目標語句的語音轉換為對應的目標語句的文本。可以理解的是,這里所述的用于對語句進行分類的電子設備可以為一臺硬件設備,也可以為安裝在智能終端上的app,或者為嵌入在某一硬件設備中的一個處理模塊。在本步驟中,所述詞語向量中包括詞義向量,且該詞義向量記載了對應的詞語本身以及該詞語在其應用語句中相鄰詞語的信息,可以理解的是,各詞語對應的詞語向量是在獲取目標語句前存儲在用于對語句進行分類的電子設備能夠調用的數據庫中的。可以理解的是,當一個語句中包括不止一個詞語時,表示該語句中各詞語的不止一個的詞義向量按照在語句中出現的順序依次排列,進而構成一個矩陣,這個矩陣與該語句是一一對應的關系。在本步驟中,裝設有用于對語句進行分類的電子設備的電器可以為一種冰箱,通過冰箱上的語音識別系統或操作面板,目標語句的文本可以為通過錄入用戶的問題或指定的語音轉化而成的文本,也可以為用戶直接輸入的文本,無論是哪一種,均需要對其進行分類確認,這樣才能夠根據其所述類型迅速調取該類型對應的文字答案或操作指令等,但由于用戶并不會按照統一標準進行目標語句的錄入,因此會出現對目標語句的分類錯誤,這顯然會造成答案或操作指令輸出錯誤的情形,也必然會降低用戶體驗。因此需要提供一種語句分類方法以對目標語句進行快速且準確的分類,保證根據目標語句的類型能夠準確且快速地輸出其對應的答案或操作指令等,以便用戶及時且準確的獲取其想要了解問題答案或執行相應操作,進而實現裝設有用于對語句進行分類的電子設備的電器的有效利用和正確操作,以提升用戶體驗。在本步驟中,用于對語句進行分類的電子設備接收目標語句,并在預存的各詞語對應的關鍵詞向量庫中查找得到將該目標語句中各詞語對應的詞語向量。可見,本發明實施例提供的基于深度學習的語句分類方法,由于在接收到目標語句后即獲取了其對應的詞語向量,從而減少了用戶等待時間,故使得用戶體驗提高。步驟200:將所述目標語句中各詞語對應的詞語向量輸入lstm模型中,得到目標語句的狀態矩陣,其中,所述狀態矩陣中包括與所述目標語句對應的初始語義信息及語序信息。在本步驟中,用于對語句進行分類的電子設備將所述目標語句中各詞語對應的詞語向量輸入長短時記憶lstm(longshorttermmemory)模型中,使得lstm模型通過其隱藏層的輸入不僅包括輸入層的輸出還包括上一時刻隱藏層的輸出的設定,得到所述目標語句對應的初始語義信息及語序信息。可以理解的是,lstm模型以包含有對應程序的處理單元的形式,設置在用于對語句進行分類的電子設備中的處理單元中。在本步驟中,所述狀態矩陣中包括與所述目標語句對應的初始語義信息及語序信息。可以理解的是,每個輸入的詞語對應的詞語向量的輸出形態均包含該詞語對應的初始語義信息及語序信息,因此,目標語句對應的各個詞語按其在目標語句的先后順序,其對應的初始語義信息及語序信息即組成了目標語句的狀態矩陣。在本步驟中,假設一個目標語句中包括依次出現的四個詞語,且該四個詞語對應的詞語向量分別為:詞語向量1、詞語向量2、詞語向量3個詞語向量4;則該目標語句對應的所述狀態矩陣中詞語與該詞語對應的初始語義信息及語序信息有如下的映射關系表1:表1目標語句中的詞語適配數據向量1語義信息1向量1和2語義信息和詞序信息2向量1、2和3語義信息和詞序信息3……步驟300:將所述狀態矩陣輸入卷積神經網絡cnn模型中,獲取所述目標語句對應的特征量。在本步驟中,用于對語句進行分類的電子設備將所述狀態矩陣輸入卷積神經網絡cnn(convolutionalneuralnetwork)模型中,使得卷積神經網絡cnn模型通過其每個神經元的輸入與前一層的局部接受域相連而提取該局部的特征的設定,得到所述目標語句對應的特征量。可以理解的是,lstm模型先輸出抽象詞義信息,在根據該抽象詞義信息及次序信息得到所述目標語句對應的特征量,以及,卷積神經網絡cnn模型以包含有對應程序的處理單元的形式,設置在用于對語句進行分類的電子設備中的處理單元中。在步驟200和步驟300中,lstm模型能夠即獲取目標語句中的詞語對應的初始語義信息,又獲取目標語句中的詞語對應的語序信息,但經其獲取的初始語義信息存在抽象程度差的缺陷,可能會導致后續的所述目標語句對應的特征量的獲取的準確性降低;以及,卷積神經網絡cnn模型能夠準確獲取目標語句中的輸出詞語對應的抽象語義信息,但卻會丟失相應的語序信息,而在語句中,詞序往往包含了用于理解語句的重要信息,這是因為相同詞語的不同組合可能會得到完全不同意思的句子,會造成獲取的所述目標語句對應的特征量的不夠準確的問題。因此,需要提供一種語句分類方法來準確地結合lstm模型和卷積神經網絡cnn模型的優勢,既能夠獲取目標語句中的各詞語對應的語序信息,又能夠獲取目標語句中的各詞語的更為抽象且準確的語義信息,以提高目標語句對應的特征量的準確性,進而保證對語句分類的準確性,使得用戶能夠獲取與其輸入問題或操作指令相匹配的答案或操作,進而實現裝設有用于對語句進行分類的電子設備的電器的有效利用和正確操作,以提升用戶體驗。在步驟200和步驟300中,首先通過lstm模型獲取目標語句中的各詞語對應的初步語義信息和語序信息,在通過卷積神經網絡cnn模型獲取目標語句中的各詞語的更為抽象且準確的語義信息。可見,本發明實施例提供的基于深度學習的語句分類方法,在提高了目標語句對應的語義信息的準確性的同時,也提供了其語序信息,提高了對目標語句識別的準確性,故使得用戶體驗提高。步驟400:根據所述目標語句的特征量對該目標語句進行分類。在本步驟中,用于對語句進行分類的電子設備根據所述目標語句的特征量對該目標語句進行分類。可以理解的是,在用于對語句進行分類的電子設備根據所述目標語句的特征量對該目標語句進行分類之后,用于對語句進行分類的電子設備可以將所述目標語句存儲在特征量相同的數據庫內,也可以通過對該目標語句的特征量的分類確認,到存儲有該類型的數據庫中遍歷得到該目標語句對應的答案或操作等。可以理解的是,用于對語句進行分類的電子設備根據設置在卷積神經網絡cnn模型內的能夠實現隱層和softmax層功能的程序單元對該目標語句進行分類。由上述描述可知,本發明實施例提供的基于深度學習的語句分類方法,首先獲取目標語句中各詞語對應的詞語向量,然后將所述目標語句中各詞語對應的詞語向量輸入lstm中,使得lstm模型輸出目標語句的狀態矩陣,再將所述狀態矩陣輸入卷積神經網絡cnn模型中,使得卷積神經網絡cnn模型輸出所述目標語句對應的特征量;相應的,根據所述目標語句的特征量對該目標語句進行分類。可見,本發明實施例提供的語句分類方法,首先通過lstm模型獲取目標語句中的各詞語對應的初步語義信息和語序信息,在通過卷積神經網絡cnn模型獲取目標語句中的各詞語的更為抽象且準確的語義信息,因而根據本發明實施例提供的方法,在提高了目標語句對應的語義信息的準確性的同時,也通過增加語序信息,提高了對目標語句分類及類型識別的準確性和可靠性,故使得用戶體驗提高。在一種可選實施方式中,參見圖2,在步驟100之前,所述方法還包括:步驟001:對獲取的語句文本進行預處理,并獲取預處理后的各語句中的各詞語對應的詞義向量。在本步驟中,用于對語句進行分類的電子設備對語句文本進行預處理。可以理解的是,語句文本為預先獲取的常見語句組成的文本,該語句文本相當于一個詞語的數據庫;以及,對語句文本進行預處理可以為對語句中的詞語進行分詞、刪除及忽略等處理。可以理解的是,該語句文本可以根據用戶錄入的歷史語句生成,也可以用于對語句進行分類的電子設備通過外部網絡直接獲取。在本步驟中,用于對語句進行分類的電子設備獲取預處理后的各語句中的各詞語對應的詞義向量。可以理解的是,詞語對應的詞義向量的獲取是將詞語表示成計算機可識別的對應的數字信息。可以理解的是,用于對語句進行分類的電子設備中可以包含一個能夠實現文本深度表示模型word2vec技術的程序單元,預處理后的各語句中的各詞語輸入該程序單元后,該程序單元輸出對應的詞義向量。步驟002:生成預處理后的各語句中的各詞語對應的詞性向量。在本步驟中,由于步驟001獲取的詞語對應的詞義向量記載了對應的詞語本身以及該詞語在其應用語句中的相鄰詞語,但并未記載該詞語的詞性信息,例如,經文本深度表示模型word2vec訓練出的詞義向量雖然能較好的表達詞義,但并沒有表達詞語的詞性等信息,也就是說文本深度表示模型word2vec并沒有將語句中隱藏的信息表達完全,其顯然會造成后續的語句分類的結果不盡準確的問題。因此,本實施例中的基于深度學習的語句分類方法通過生成預處理后的各語句中的各詞語對應的詞性向量,解決了獲取的詞義向量中缺少詞語的詞性信息的問題。步驟003:組合各詞語對應的所述詞義向量和詞性向量,得到各詞語對應的詞語向量。在本步驟中,用于對語句進行分類的電子設備將各詞語對應的所述詞義向量和詞性向量組合成各詞語對應的詞語向量。可以理解的是,各詞語對應的詞語向量既包括了詞語對應的所述詞義向量,又包括了詞語對應的詞性向量。可見,本實施方式提供的基于深度學習的語句分類方法,通過在已獲取詞語所對應的詞義信息的基礎上,又通過隨機方式獲取詞語的詞性信息,以及通過將其二者結合為詞語信息為后續的分類處理提供數據基礎,從而提高了語句的隱藏的信息表達的完整性,進而提高了后續的語句分類結果的準確性,故使得用戶體驗提高。針對現有的目標語句對應的詞語向量的獲取效率低的問題,為提高獲取的目標語句對應的詞語向量的效率,在一種可選實施方式中,參見圖3,在步驟003之后,所述方法還包括:步驟004:根據各詞語對應的所述詞語向量,生成關鍵詞向量庫,其中,所述關鍵詞向量庫中存儲有各詞語與其對應的詞語向量間的一一映射關系。在本步驟中,用于對語句進行分類的電子設備根據各詞語對應的所述詞語向量,生成關鍵詞向量庫,以供用于對語句進行分類的電子設在獲取到目標語句時,直接在關鍵詞向量庫中查到其對應的詞語向量。可以理解的是,關鍵詞向量庫存儲的各詞語與其對應的詞語向量間的一一映射關系可以表現為下映射關系表2:表2詞語詞語向量詞語1詞義向量b1、詞性向量b1詞語2詞義向量b2、詞性向量b2詞語3詞義向量b3、詞性向量b3詞語4詞義向量b4、詞性向量b4...…例如,假設向量w=[w0w1…wn]表示一系列的詞語;矩陣v=[v0v1…vn]表示向量w中每個詞語對應的詞義向量,這些詞義向量均由word2vec訓練生成,這里詞義向量的維度一般為128,具體根據實際需要選取;矩陣p=[p0p1…pn]表示向量w中每個詞語對應的詞性向量,這些詞性向量是隨機生成的,可以理解的是,不同詞語之間可能具有相同的詞性,那么這兩個詞語的詞性向量一致。關鍵詞向量庫具體如下表3所示:表3其中,以表3中的第一組數據為例進行說明,[v0p0]表示將兩個向量拼接起來對應詞語w0組成的一個詞語向量的數字表示,進而擴充了詞語w0所對應的信息。相對于步驟004的設置,步驟100具體包括:步驟101:根據所述目標語句在所述關鍵詞向量庫中查找得到該目標語句的全部詞語對應的詞語向量。在本步驟中,用于對語句進行分類的電子設備接收目標語句,并根據獲取的目標語句在所述關鍵詞向量庫中查找得到該目標語句的全部詞語對應詞語向量。例如,用于對語句進行分類的電子設備獲取的一個問題語句q后,在關鍵詞向量庫中經過索引得到該問題語句q中出現的n個詞語<q0、q1、…qn>的對應的n個詞語向量[x0x1…xn],以及該n個詞語向量[x0x1…xn]組成的詞語矩陣[x0x1…xn]t。可見,本實施方式提供的基于深度學習的語句分類方法,通過根據詞語向量生成關鍵詞向量庫,為后續目標語句對應詞語向量的獲取提供了一種快速且可靠的方式,從而減少了用戶等待時間,故使得用戶體驗提高。在一種可選實施方式中,參見圖4,所述步驟200具體包括:步驟201:將與目標語句中各詞語對應的各所述詞語向量依次按序輸入長短時記憶lstm中,獲取所述lstm層中包含所述目標語句對應的初始語義信息及語序信息的的隱含狀態。在本步驟中,用于對語句進行分類的電子設備將與目標語句對應的各所述詞語向量依次按序輸入長短時記憶lstm(longshorttermmemory)中,使得所述lstm層提取得到所述目標語句對應的初始語義信息及語序信息,并保存所述lstm層提取過程中的各單元的包含所述初始語義信息及語序信息的隱含狀態。可以理解的是,除了lstm層,門控制循環gru(gatedrecurrentunit)層也可以實現該功能。步驟202:根據所述lstm層的隱含狀態,生成所述目標語句的狀態矩陣。在本步驟中,用于對語句進行分類的電子設備根據所述lstm層提取過程中的各單元的隱含狀態,生成所述目標語句的狀態矩陣。可以理解的是,用于對語句進行分類的電子設備每個時刻向lstm細胞單元輸入一個詞向量以及上一時刻的隱含狀態,由此計算出當前時刻的隱含狀態,將每一個時刻的隱含狀態保存。例如,如圖5所示,用于對語句進行分類的電子設備將與目標語句對應的各所述詞語矩陣中的每一個詞語向量按順序輸入lstm層中,可以理解的是,此處的詞語向量是分時依次輸入的,即每一個時刻輸入一個詞向量,即t0時刻輸入x0,t1時刻輸入x1等。lstm層抽將初步提取出目標語句的語義信息和語序信息,并保存lstm每個單元的隱含狀態向量,目標語句的語義信息和語序信息也包含在隱含狀態向量中,再將lstm層輸出的隱含狀態向量拼接成狀態矩陣[h0h1…hn]t。可見,本實施方式提供的基于深度學習的語句分類方法,通過根據詞語向量生成關鍵詞向量庫,提高了lstm模型獲取初始語義信息及語序信息的效率,并解決了應用cnn模型無法提取詞語的詞序信息的缺陷,提高了對語句進行分類的準確性,故使得用戶體驗提高。為提高卷積神經網絡cnn模型獲取抽象語義信息及特征量的效率,在一種可選實施方式中,參見圖6,所述步驟300具體包括:步驟301:將所述狀態矩陣輸入所述卷積神經網絡cnn模型中的卷積層中,獲取目標語句對應的抽象語義信息,且各所述抽象語義信息構成各卷積層的卷積結果。在本步驟中,用于對語句進行分類的電子設備將所述狀態矩陣輸入所述卷積神經網絡cnn模型中的卷積層中,使得卷積層對輸入的句子矩陣進行抽象化特征提取處理,獲取目標語句對應的抽象語義信息,步驟302:將所述卷積結果輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。在本步驟中,用于對語句進行分類的電子設備將所述卷積結果輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。可以理解的是,用于對語句進行分類的電子設備將所述卷積結果通過池化層以選擇出最具有代表性的特征作為所述目標語句的特征量。可以理解的是,卷積神經網絡cnn模型的卷積層雖然具有較好的語義特征提取能力,但是丟失了問題的詞序信息,而在語句中詞序包含了重要信息,這是因為相同詞語的不同組合可能會得到完全不同意思的語句。lstm層的反饋機制能夠很好利用問題的詞序信息,但lstm層的細胞單元對語句的語義信息提取能力不如卷積神經網絡cnn模型的卷積層。因此,本實施方式中所述的基于深度學習的語句分類方法,在獲取lstm層的包含所述初始語義信息及語序信息的隱含狀態后,根據隱含狀態獲取準確的抽象語義信息,既發揮lstm層善于獲取語序信息的優點,又充分利卷積神經網絡cnn模型的卷積層在特征提取和抽象過程中的能力,二者進行了優勢互補,提高了語句分類的準確性,并提高卷積神經網絡cnn模型獲取抽象語義信息及特征量的效率,故使得用戶體驗提高。針對現有的如圖7所示的池化方法可能會丟失句子信息的情況,為提高卷積神經網絡cnn模型中的池化層進行目標語句的特征量的準確性,在一種可選實施方式中,參見圖8,所述步驟302具體包括:步驟302a:分別將各卷積層的卷積結果進行合并,得到合并后的同類型卷積結果組。在本步驟中,參見圖9,用于對語句進行分類的電子設備分別將各卷積層的卷積結果進行同類合并,對合并后的同類型卷積結果組進行池化操作,而且池化的對象是相同特征的不同卷積結果。此種池化操作的優勢在于在相同特征的多種卷積結果中,選擇出最佳的、最合適的結果表示該特征,經過這一層的池化操作后,就能得到所有輸入特征的最佳表示。可以理解的是,合并是將相同的特征向量的不同卷積結果合成一個矩陣,例如有一個特征向量v在經過第一個卷積核后得到一個featuremapf1,經過第二個卷積核后得到一個featuremapf2,將這兩個featuremap合并得到一個矩陣f=[f1f2]。。步驟302b:將所述同類型卷積結果組輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。在本步驟中,用于對語句進行分類的電子設備分將所述同類型卷積結果組輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。可以理解的是,池化操作的方式不唯一,第一種是mean-pooling,即對池化窗中的值求平均,以均值來代表被池化區域的信息。第二種是max-pooling,即求解池化窗中的最大值,該種方法則是取池化窗中最大的值來代表被池化區域的信息,此種做法的出發點是取該區域中最優的值表示整個區域。可見,本實施方式提供的基于深度學習的語句分類方法,通過將各卷積層的卷積結果進行同類合并,在相同特征的多種卷積結果中,選擇出最佳的、最合適的結果表示該特征,經過這一層的池化操作后,就能得到所有輸入特征的最佳表示,提高了語句分類的準確性,故使得用戶體驗提高。可以理解的是,本實施例上述多個可選實施方式記載的方案可以自由組合,本發明對此不作限定。基于同樣的發明構思,本發明第二個實施例提供了一種語句分類系統,參見圖10,該系統包括:詞語向量獲取模塊10、lstm模型處理模塊20、cnn模型處理模塊30和語句分類模塊40;其中:詞語向量獲取模塊10,用于獲取目標語句中各詞語對應的詞語向量,其中,所述詞語向量中包括詞義向量。lstm模型處理模塊20,用于將所述目標語句中各詞語對應的詞語向量輸入循環神經網絡lstm模型中,得到目標語句的狀態矩陣,其中,所述狀態矩陣中包括與所述目標語句對應的初始語義信息及語序信息。cnn模型處理模塊30,用于將所述狀態矩陣輸入卷積神經網絡cnn模型中,獲取所述目標語句對應的特征量。語句分類模塊40,用于根據所述目標語句的特征量對該目標語句進行分類。在一種可選實施方式中,參見圖11,所述系統還包括:詞義向量獲取單元01,用于對獲取的語句文本進行預處理,并獲取預處理后的各語句中的各詞語對應的詞義向量。詞性向量生成單元02,用于生成預處理后的各語句中的各詞語對應的詞性向量。詞語向量獲取單元03,用于組合各詞語對應的所述詞義向量和詞性向量,得到各詞語對應的詞語向量。在一種可選實施方式中,參見圖12,所述系統還包括:關鍵詞向量庫生成單元04,用于根據各詞語對應的所述詞語向量,生成關鍵詞向量庫,其中,所述關鍵詞向量庫中存儲有各詞語與其對應的詞語向量間的一一映射關系。相應的,所述詞語向量獲取模塊10用于根據所述目標語句在所述關鍵詞向量庫中查找得到該目標語句的全部詞語對應的詞語向量。在一種可選實施方式中,參見圖13,所述lstm模型處理模塊20包括:lstm細胞記憶單元21,用于將與目標語句中各詞語對應的各所述詞語向量依次按序輸入lstm的記憶細胞中,獲取所述lstm層中包含所述目標語句對應的初始語義信息及語序信息的隱含狀態。狀態矩陣生成單元22,用于根據所述lstm層的隱含狀態,生成所述目標語句的狀態矩陣。在一種可選實施方式中,參見圖14,所述cnn模型處理模塊30包括:卷積層處理單元31,用于將所述狀態矩陣輸入所述卷積神經網絡cnn模型中的卷積層中,獲取目標語句對應的抽象語義信息,且各所述抽象語義信息與對應的所述語序信息構成各卷積層的卷積結果。池化層處理單元32,用于將所述卷積結果輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。在一種可選實施方式中,參見圖15,所述池化層處理單元32包括:同類合并子單元32a,用于分別將各卷積層的卷積結果進行同類合并,得到合并后的同類型卷積結果組。特征量獲取子單元32b,用于將所述同類型卷積結果組輸入所述卷積神經網絡cnn模型中的池化層中,得到所述目標語句的特征量。本實施例提供的語句分類系統,可以用于執行上述實施例所述的語句分類方法,其實現原理和技術效果類似,此處不再詳述。本實施例提供的語句分類系統,既可以是安裝在家電設備上的應用程序app,也可以是獨立于家電設備而單獨形成的專門用于對家電設備進行控制的終端產品,如手持移動產品。本實施例提供的語句分類系統,在提高了目標語句對應的語義信息的準確性的同時,也提供了其語序信息,提高了對目標語句識別的準確性,故使得用戶體驗提高。下面將通過第一至第五實施例對本發明進行詳細解釋說明。基于同樣的發明構思,本發明第三個實施例提供了一種電子設備,包括:處理器、存儲器和總線;其中,處理器和存儲器通過總線完成相互間的通信;處理器用于調用存儲器中的程序指令,以執行上述實施例所述的語句分類方法,其實現原理和技術效果類似,此處不再詳述。基于同樣的發明構思,本發明第四個實施例提供了一種冰箱,該冰箱上設有語音識別系統,且所述語音識別系統中包括一種電子設備;所述電子設備包括:處理器、存儲器和總線;其中,處理器和存儲器通過總線完成相互間的通信;處理器用于調用存儲器中的程序指令,以執行上述實施例所述的語句分類方法,其實現原理和技術效果類似,此處不再詳述。基于同樣的發明構思,本發明第五個實施例提供了一種非暫態計算機可讀存儲介質,該非暫態計算機可讀存儲介質存儲計算機指令,所述計算機指令使所述計算機執行上述實施例所述的語句分類方法,其實現原理和技術效果類似,此處不再詳述。在本發明的描述中,需要說明的是,術語“上”、“下”等指示的方位或位置關系為基于附圖所示的方位或位置關系,僅是為了便于描述本發明和簡化描述,而不是指示或暗示所指的裝置或元件必須具有特定的方位、以特定的方位構造和操作,因此不能理解為對本發明的限制。除非另有明確的規定和限定,術語“安裝”、“相連”、“連接”應做廣義理解,例如,可以是固定連接,也可以是可拆卸連接,或一體地連接;可以是機械連接,也可以是電連接;可以是直接相連,也可以通過中間媒介間接相連,可以是兩個元件內部的連通。對于本領域的普通技術人員而言,可以根據具體情況理解上述術語在本發明中的具體含義。還需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。以上實施例僅用于說明本發明的技術方案,而非對其限制;盡管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特征進行等同替換;而這些修改或替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的精神和范圍。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1