一種APT攻擊檢測方法與流程
本發明屬于網絡安全領域,尤其涉及一種APT攻擊檢測方法。
背景技術:
高級持續性威脅是一種有組織、有特定目標、持續時間極長的新型攻擊。隨著震網(Stuxnet)、Duqu、火焰(Flame)以及2015年針對烏克蘭電廠的Killdisk攻擊的曝光,可以看出,APT攻擊會對各類工控網絡和關鍵信息基礎設施的安全造成巨大的威脅。APT攻擊的主要目標是竊取軍事機構、政府機關、國家基礎設施以及高新技術企業等機密信息或造成指定的破壞。其特點主要有以下兩點:(1)攻擊手段高級。攻擊者多利用0day漏洞等未知攻擊進行入侵,如對伊朗核電站發起的攻擊,攻擊者在6年時間里分別利用了Flame病毒、Stuxnet病毒以及Duqu病毒等多種未知漏洞進行攻擊。然而,當前對未知網絡攻擊的檢測具有很大的挑戰性。(2)攻擊持續時間長。攻擊者為了完成攻擊目標可能潛伏數月甚至數年,如從2006年開始的“暗鼠行動”滲透并攻擊了全球多達72家公司和組織的網絡,直到2011年才被McAfee和Symantec公司發現并報告。再如從2007年開始針對5家西方跨國能源公司的油田操作機密信息竊取的“夜龍攻擊”,4年后才由McAfee報告并發現。正是由于該特性,使得本發明需要從大量的網絡流量/主機行為數據中對APT攻擊進行檢測。APT攻擊雖然采取的手段不同方式各異,但最終均會在網絡底層原始數據流上反應。由于機器學習(Machine Learning,ML)在處理大數據及攻擊檢測方面具有明顯的優勢,共同使得它在APT攻擊檢測領域極具研究前景。當前基于機器學習的APT攻擊檢測方案均采用監督學習的方法,其基本思想是通過提取當前網絡流量數據或主機行為數據的特征,將已知正常或異常的歷史流量數據作為訓練數據集,在此基礎上利用分類算法對網絡流量數據或主機行為進行標記分類,以區分正常和異常行為。然而,這些方法存在以下問題:(1)針對特定網絡的訓練數據集有限。在實際APT攻擊場景下,訓練數據往往需要通過專家知識進行人工標記而產生,因此準確的已標記數據集一般規模非常有限,大部分是未標記歷史網絡流量數據,不知道其為正常或異常。而監督學習本身需要大量的已標記數據作為訓練數據集,訓練數據集的規模及準確程度直接影響到模型的檢測性能。因此,如何利用少量已標記數據生成準確的訓練數據集以保證模型的檢測精度是當前APT攻擊檢測面臨的一大挑戰。(2)網絡流量特征難以選取。當前基于監督學習的APT攻擊檢測更多是基于傳統入侵檢測開展研究,對于已知攻擊的檢測具有一定的優勢。然而APT攻擊多利用0day漏洞等未知攻擊,針對不同目標網絡所采取的攻擊可能各不相同,即使對于相同的目標網絡攻擊者利用的0day漏洞也可能是動態變化的,而不同的未知攻擊所表現出來的底層網絡流量特征也不盡相同。因此,如何針對特定目標網絡動態選取合適的網絡流量特征以檢測所遭受的未知攻擊是面臨的另一挑戰。網絡級持續性威脅是一種新型的智能網絡攻擊,其主要特點為0day漏洞等未知攻擊的利用以及持續時間長。
綜上所述,當前基于機器學習的APT攻擊檢測中訓練檢測模型的人工標記數據過少、未知攻擊的流量特征難以選取的問題。
技術實現要素:
本發明的目的在于提供一種APT攻擊檢測方法,旨在解決當前基于機器學習的APT攻擊檢測中訓練檢測模型的人工標記數據過少、未知攻擊的流量特征難以選取的問題。
本發明是這樣實現的,提出一種APT攻擊檢測方法,所述APT環境下基于信息增益率的半監督學習攻擊檢測方法利用半監督學習算法來標記特征相似的數據,以少量已標記數據生成大規模的訓練數據集,實現對歷史數據的自動標記并獲得更大規模且準確標記的訓練數據集;并引入信息增益率來確定不同特征對檢測的影響程度,采用信息增益率對檢測模型中劃分的每個子數據集進行特征提取,針對不同目標網絡選取最有助于劃分數據樣本的特征,以實現對未知攻擊的準確識別;最后采用基于信息增益的加權多數算法優化模型APT攻擊檢測性能。
進一步,所述半監督學習算法具體步驟如下:
(1)在已標記的正常和異常數據中分別隨機選取一條數據作為簇的中心,選取N1,N5作為已標記數據簇和已標記數據簇的簇心c1,c2;
(2)利用公式計算每條數據Ni分別與簇心c1,c2的距離d(Ni,ck),并將d(Ni,ck)值小的數據劃分到一個簇內;
(3)利用公式分別計算兩個簇中所有點的質心并將其作為新的簇心c1′,c′2;
(4)重復步驟(2)、(3)直至總的簇內離散度總和J達到最小時停止,其中離散度總和為每條數據Ni到其對應簇心ck的距離d(Ni,ck)的總和;
(5)計算每類已標記數據在每個簇中出現的概率Pl,k,并以Pl,k最大時的l標記簇k的類別,最終得到訓練數據集D;
其中,Ni,m表示第i條數據的第m個特征值,ck,m表示第k個簇心的第m個特征值,m為網絡流量特征的個數;I為數據集中樣本總個數,I′為簇k中數據樣本總個數。
進一步,所述基于信息增益率的隨機森林檢測方法,利用Bootstrap重采樣算法,每次有放回地從集合D中抽取一個數據樣本,一共抽取I次,除去重復的數據,得到一個子訓練集S1,重復此步驟q次,得到q個子訓練數據集{S1,S2,...,Sq}用于生成q個不同的決策樹以構建隨機森林。
進一步,生成每棵決策樹Tq的具體步驟如下:
步驟一,選取信息增益率最大的流量特征作為決策樹的根節點;
步驟二,找到選取的特征所對應數據集Sq中使該特征最快分裂到葉子節點的閾值,對該節點進行分裂;
步驟三,在每個非葉子節點選擇特征前,以剩余特征作為當前節點的分裂特征集,選取信息增益率最大的流量特征作為根節點分裂的非葉子節點;
步驟四,重復步驟二和步驟三直至每個特征都對應有葉子節點為止,構建出Sq對應的決策樹Tq。
進一步,具體計算公式如下:
其中,Sq為通過Bootstrap重采樣隨機選取的訓練數據集D的子集;GainRatio(Sq,m)、Gain(Sq,m)、Split(Sq,m)分別表示子數據集Sq的信息增益率、信息增益和分裂信息,V(m)是特征m的值域;Sv是集合Sq中在特征m上值等于v的子集;A表示特征m的屬性總數,特征Protocol_type,其屬性有TCP、UDP、ICMP,所以其A=3;H(x)為數據集x的熵;pl為第l類樣本數占總數據集的比例。
本發明提供的一種APT攻擊檢測方法,利用半監督學習算法來標記特征相似的數據,并引入信息增益率來確定不同特征對檢測的影響程度。實驗結果表明,提出的模型對未知攻擊檢測的準確率、檢測率較傳統隨機森林模型相比分別提高了3.18%、4.5%,誤報率和漏報率分別降低了53.54%和40.76%。本發明利用改進的k-means算法來標記特征相似的數據,在少量人工標記數據的基礎上實現了大量訓練數據集的準確標記,保證了模型的檢測精度;通過在模型中引入信息增益率來確定不同特征對檢測的影響程度,減少數據中冗余及噪聲特征的影響,從而選取重要的流量特征,提高檢測模型的泛化能力,以應對未知攻擊的檢測。
附圖說明
圖1是本發明實施例提供的一種APT攻擊檢測方法流程圖。
圖2是本發明實施例提供的網絡流量特征示意圖。
圖3是本發明實施例提供的基于半監督學習的歷史網絡流量數據標記過程示意圖。
圖4是本發明實施例提供的基于信息增益率的流量特征提取示意圖。
圖5是本發明實施例提供的基于特征提取的決策樹生成過程示意圖。
圖6是本發明實施例提供的基于信息增益的加權多數算法(WMA)攻擊檢測示意圖。
圖7是本發明實施例提供的本發明與傳統隨機森林(Random Forest,RF)、K-近鄰(K-Nearest Neighbor,KNN)、支持向量機(Support Vector Machine,SVM)算法的檢測性能對比示意圖。
圖8是本發明實施例提供的不同d值下的模型檢測率與訓練數據集D準確率示意圖。
圖9是本發明實施例提供的決策樹個數q對檢測準確率和模型檢測時間的影響示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
下面結合附圖對本發明的應用原理作詳細的描述。
如圖1所示,本發明實施例提供的一種APT攻擊檢測方法包括以下步驟:
S101:基于半監督學習的方法利用少量已標記數據生成大規模的訓練數據集;
S102:采用信息增益率對檢測模型中劃分的每個子數據集進行特征提取,以實現對未知攻擊的準確識別。
下面結合具體附圖對本發明的應用原理作進一步的描述。
為了應對APT攻擊檢測中訓練數據集有限和網絡流量特征難以選取兩個挑戰,首先基于半監督學習的方法利用少量已標記數據生成大規模的訓練數據集,之后采用信息增益率對檢測模型中劃分的每個子數據集進行特征提取,以實現對未知攻擊的準確識別。
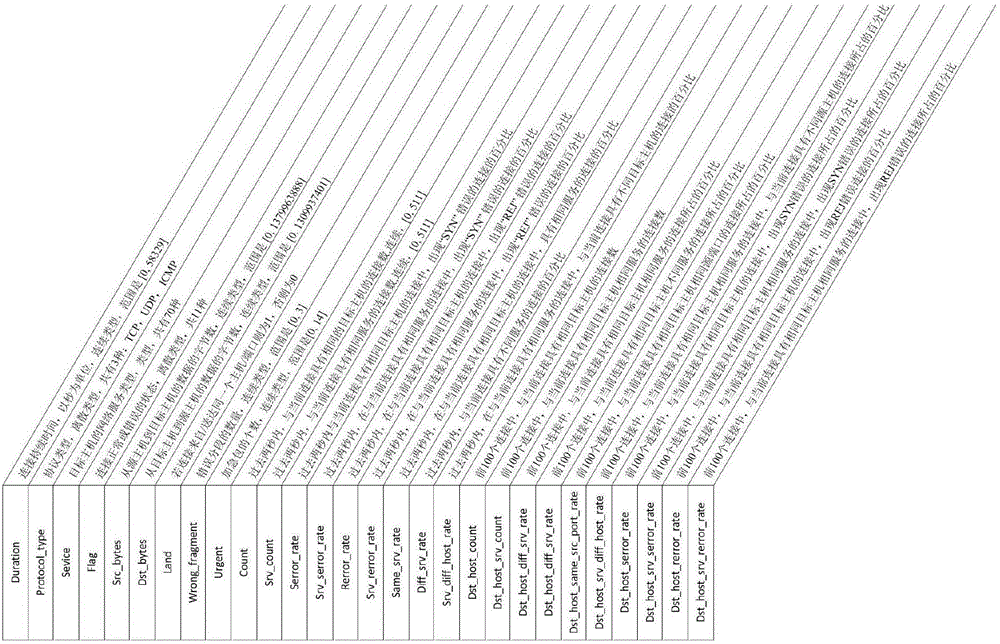
APT攻擊方式雖然各異,但其最終均可反應到底層網絡流量數據中,因此本發明采用目前最常用的網絡流量特征,其中包括Duration、Protocol、Count、Srv_count等,具體特征如表1所示。本發明將數據集中字符型特征轉化成數值型以便測試。這里本發明以數據集中一條數據N1=(2,tcp,smtp,SF,1684,363,0,0,0,1,1,0.00,0.00,0.00,0.00,1.00,0.00,0.00,104,66,0.63,0.03,0.01,0.00,0.00,0.00,0.00,0.00)為例進行說明。對于字符型的Protocol_type特征,它包括TCP、UDP、ICMP三個屬性值,本發明以0表示屬性TCP,1表示屬性UDP,2表示屬性ICMP。同時,對數據集進行歸一化處理,以減小特征之間量綱的影響,即保證每個特征的重要程度不受數值的影響。本發明利用min-max標準化法,將數據的大小范圍縮小到[0,1]之間,具體計算公式如式(1):
其中,xNormalized是某一特征歸一化后的值,xIntial為特征初始的屬性值,xmin是該特征的最小值,xmax是該特征的最大值。則N1經過以上處理轉化為(3.429×10-5,0,0.59,0,1.286×10-4,2.77×10-6,0,0,0,1,1,0.00,0.00,0.00,0.00,1.00,0.00,0.00,0.21,0.132,0.63,0.03,0.01,0.00,0.00,0.00,0.00,0.00)。
1.1基于半監督學習的訓練集生成
由于在APT攻擊檢測中目標網絡數據量巨大,依賴專家知識進行人工標記只能得到少量準確標記的數據作為訓練樣本,這使得訓練出的模型無法準確檢測異常[19]。半監督學習則是針對這類問題提出的,即利用少量具有先驗知識的數據來輔助無監督學習。為了實現對歷史數據的自動標記并獲得更大規模且準確標記的訓練數據集,本文提出改進的k-means半監督學習算法,本發明以圖2為例進行說明。
(1)在已標記的正常和異常數據中分別隨機選取一條數據作為簇的中心,圖2中本發明選取N1,N5作為已標記數據(正常)簇和已標記數據(異常)簇的簇心c1,c2;
(2)利用公式(2)計算每條數據Ni分別與簇心c1,c2的距離(相似度)d(Ni,ck),并將d(Ni,ck)值小的數據劃分到一個簇內;
(3)利用公式(3)分別計算兩個簇中所有點的質心并將其作為新的簇心c1′,c′2;
(4)重復步驟2、3直至總的簇內離散度總和J達到最小時停止,其中離散度總和為每條數據Ni到其對應簇心ck的距離d(Ni,ck)的總和;
(5)計算每類已標記數據在每個簇中出現的概率Pl,k,并以Pl,k最大時的l標記簇k的類別,最終得到訓練數據集D。
具體公式如下:
l=argmaxPl,k (6)
其中,Ni,m表示第i條數據的第m個特征值,如N1,1=3.429×10-5,ck,m表示第k個簇心的第m個特征值,m為網絡流量特征的個數,本發明中m=28。I為數據集中樣本總個數,I′為簇k中數據樣本總個數,例如圖2中I=20,訓練數據集D的簇1中I′=15。d(Ni,ck)表示數據Ni到簇中心的歐式距離,用來描述其相似度的大小。由于本發明將數據集劃分成兩個簇,因此k=1或2。Pl,k表示第l類已標記類在第k個簇中出現的概率(l=0或1,0代表正常類,1代表異常類),nl,k表示第l類已標記樣本在第k個簇中的數量,nl表示第l類已標記樣本的總數量,因此當Pl,k最大時用l標記簇k的類別,arg max f(x)表示取滿足函數f(x)最大時自變量x的值。例如在圖2中,正常已標記類在簇1中出現的概率P0,1=1,異常已標記類在簇1中出現的概率P1,1=0.33,P0,1>P1,1,因此將簇1標記為0,即簇1為正常類。同理,在簇2中P1,2=0.67,P0,2=0,因此簇2標記為1,即簇2為異常類。
1.2基于信息增益率的流量特征提取
在基于機器學習的入侵檢測系統(IDS)中,隨機森林算法由于具有優良的泛化性能,相對于其他分類算法對攻擊的檢測更有優勢,使得其成為當前攻擊檢測普遍選取的基準算法。然而,對于APT攻擊,不同的目標網絡所遭受的攻擊可能不同,而不同的攻擊所體現的特征也是不同的。因此本發明需要針對不同目標網絡選取最有助于劃分數據樣本的特征。
一個特征能夠為分類模型帶來的信息越多,該特征越重要,模型中它的有無將導致信息量發生較大的變化,而前后信息量的差值就是這個特征給模型帶來的信息增益。為了在構造決策樹的過程中選取更具有代表的特征,本發明在本發明中引入信息增益的概念并用信息增益率(Gain Ratio)來衡量給定的特征區分訓練樣例的能力,具體過程如圖4所示。
本發明設上節中生成的訓練數據集D中含有I個不同的數據樣本{N1,N2,...,NI}。首先利用Bootstrap重采樣算法,每次有放回地從集合D中抽取一個數據樣本,一共抽取I次,除去重復的數據,得到一個子訓練集S1,重復此步驟q次,得到q個子訓練數據集{S1,S2,...,Sq}用于生成q個不同的決策樹以構建隨機森林。其中,生成每棵決策樹Tq的具體步驟如下:
1.選取信息增益率最大的流量特征作為決策樹的根節點;
2.找到選取的特征所對應數據集Sq中使該特征最快分裂到葉子節點的閾值,對該節點進行分裂;
3.在每個非葉子節點(包括根節點)選擇特征前,以剩余特征作為當前節點的分裂特征集,選取信息增益率最大的流量特征作為根節點分裂的非葉子節點;
4.重復步驟2、3直至每個特征都對應有葉子節點為止,構建出Sq對應的決策樹Tq。
具體計算公式如下:
其中,Sq為通過Bootstrap重采樣隨機選取的訓練數據集D的子集;GainRatio(Sq,m)、Gain(Sq,m)、Split(Sq,m)分別表示子數據集Sq的信息增益率、信息增益和分裂信息,V(m)是特征m的值域;Sv是集合Sq中在特征m上值等于v的子集;A表示特征m的屬性總數,例如特征Protocol_type,其屬性有TCP、UDP、ICMP,所以其A=3;H(x)為數據集x的熵;pl為第l類樣本數占總數據集的比例。
下面本發明以圖5為例來說明上述過程,本發明首先利用Bootstrap重采樣算法從訓練數據集中隨機抽取了一個數據集Sq,計算數據集Sq中28個特征的信息增益率,假定得到特征count的信息增益率最大,將特征count作為根節點開始構建決策樹Tq;根據數據集Sq中特征count的屬性值分布進行分裂,即找出合適的閾值劃分數據集Sq。這里假定在數據集Sq中特征count的分裂閾值為64,即在數據集Sq中的數據若其特征count≤64,即劃分為異常,若當count>64,則進一步提取特征;當count>64,選取剩余特征中信息增益率最大的特征Dst_bytes第二個特征,同理找出分裂閾值;重復上述步驟,直到將數據集完全劃分為止,圖4中,當特征選取到Protocol_type時,數據集完全劃分,此時決策樹Tq構建完成。
在上述方法中,采用信息增益率而不是信息增益來進行特征選取,是由于以信息增益度量存在一個內在偏置,它偏袒具有較多屬性的特征,即當某一特征具有大量的屬性值時(如特征Duration,根據表1本發明知道其取值范圍為[0,58329],因此本發明認為其有58329個屬性值),由公式(8)可以計算得知趨近于0,由于數據集Sq的熵H(Sq)是固定的,從而信息增益Gain(Sq,m)變大,并趨近于H(Sq),因此決策樹在特征選取的過程中,偏向于選擇該特征。但這又會導致過擬合,即選取的特征僅能反應已知訓練數據集中的數據分布,使得模型僅具有對已知流量數據的分類能力,而對于未知流量數據的分類效果(未知攻擊的檢測能力)卻非常差。而特征的分裂信息(Split Information)指其對應的數據集關于該特征的各個屬性值的熵,當信息增益確定時,特征的重要性將隨著分裂信息的增大而減小。
例如,當一個含有I個流量數據的集合被特征A徹底分割(即分成I組,I>2),此時分裂信息為log2I;同時,存在一個布爾特征B分割同樣的集合,如果恰好平分(I=2),則其分裂信息為1。此時,若僅采用信息增益而不是信息增益率來選取特征,則本發明可以利用公式(8)知道Gain(Sq,A)>Gain(Sq,B),從而選取特征A作為構建決策樹的非葉子節點(根節點)。然而,在實際中由于特征A具有較多屬性值,將數據集劃分為多個小空間,即每片葉子節點有可能僅包含單純的正常和異常,此時決策樹可以完美的擬合訓練數據,然而,當測試數據集中出現有不屬于特征A的屬性值的數據時,所構建的決策樹仍然僅通過特征A對測試數據進行分類,而不考慮其他特征,這必然導致模型的檢測性能將大幅度下降。因此,本發明引入了信息增益率來解決上述問題。根據公式(6),顯然特征B信息增益率更高,即優先選取特征B作為非葉子節點(根節點)構建決策樹,從而避免了選取屬性值多的特征A而導致模型對未知攻擊檢測能力的降低。因此,本發明利用則特征Protocol_type的信息增益率計算如下:
則信息增益率作為一種補償措施來解決信息增益存在的問題,引入分裂信息來懲罰上述屬性值多的特征,以提高模型對未知流量檢測的精度。
下面本發明以圖3為例,說明特征提取和決策樹生成的過程。設Sq為通過Bootstrap算法從訓練數據集D={N1,N2,...,N20}抽取的子數據集,Sq={N1,N2,N3,N4,N5,N6,N7,N8,N9,N10},為了方便計算本發明選Protocol_type、Service 2個特征進行對比,其特征的屬性值如表1所示,其中數據類別正常/異常用數字0/1表示,則sq中正常和異常數據的個數分別為7和3。
表1 N1到N10特征Protocol_type、Service屬性值及類別
同理計算GainRatio(Sq,Service)=18.4%,可知特征Service比Protocol_type有更大的信息增益率,因此,本發明優先選取特征Service作為構建決策樹模型T1的非葉子節點。
1.3基于加權多數算法(Weighted Majority Algorithm,WMA)的攻擊檢測
由于每棵決策樹都是利用Bootstrap算法去重后隨機生成的子數據集構建,子數據集規模以及正常/異常數據分布較訓練數據集D相比均發生變化,子數據集Sq的信息熵H(Sq)也隨之改變,從而導致每個子數據集Sq所對應構建的決策樹Tq對最終分類結果的影響程度也各不相同,傳統RF中簡單的將最多數決策樹的分類結果確定為最終分類結果顯然是不合適的。同時,在檢測過程中測試數據是逐條通過模型進行檢測的,若采用基于半監督學習的方法對數據進行檢測標記會由于每次檢測都需要通過多次迭代對全部數據進行聚類而導致模型檢測效率極低,無法滿足實際環境中實時檢測的需求,并且僅采用基于半監督學習的方法進行檢測會由于其自身劃分精度與分類算法相比較低而導致模型整體檢測精度下降。
因此,如圖6所示,本發明引入加權多數算法給每棵決策樹分配權值wq對網絡流量數據進行檢測,并分析子數據集Sq較訓練數據集D在通過Bootstrap重采樣算法去重后的集合規模以及數據分布的變化程度,以子數據集Sq較訓練數據集D的信息增益Gain(Sq,l)衡量其對應生成的每棵決策樹Tq對最終檢測結果的影響程度。由于l只有0、1兩類,根據上節中對信息增益的定義,不存在由于特征屬性值過多引起的過擬合問題,因此本發明采用信息增益Gain(Sq,l)而不是信息增
益率來衡量每棵決策樹對最終檢測結果的影響程度,具體公式如下:
為了方便計算,將每個決策樹的結果分為正常和異常,并用1和-1表示,得到q個分類結果(y1,y2,...,yq),即yq={1,-1},其中,-1代表決策樹輸出結果為異常,1代表決策樹輸出結果為正常。Sq,l表示在子數據集Sq中類別為l的數據集合,Q為決策樹的總個數,sgn為符號函數,即當時,y=1,即被檢測流量數據為正常流量;當時,y=-1,即被檢測流量數據為異常流量。
例如當隨機森林中有T1、T2兩棵決策樹,其權值通過公式(11)計算分別為w1=41%、w2=33%,對測試數據集E中一條數據E1檢測時得到的分類結果分別為1、-1,則利用公式(12)可以得到y=1,即流量數據E1的檢測結果為正常流量。
由于APT攻擊隨時間的推移,攻擊方式可能動態變化,使得反映在底層的網絡流量數據以及體現攻擊的特征也隨之改變。為了應對動態變化的攻擊方式,本發明將檢測完成的數據加入訓練數據集中,并去除較早的數據,動態更新訓練數據集以應對動態變化的攻擊方式。
如圖7所示,本發明的準確率(Accuracy)、檢測率(Detection Rate)、誤報率(False Alarm)和漏報率(False negative rate)分別達到了80.77%、77.51%、0.92%和2.79%,較傳統RF相比,漏報率、誤報率分別降低了53.54%和40.76%,這主要是由于與傳統RF算法不同,本發明利用半監督學習算法使得模型具有足夠的標記樣本進行訓練,保證了訓練出的模型的有效性,使其具有較高的檢測精度。另一方面,結合圖7,本發明通過計算可以知道,本發明較KNN算法和SVM算法相比,準確率和檢測率分別提高了14.86%、14.20%和7.58%和7.07%,這是由于本發明通過引入信息增益率選取了最能體現當前目標網絡的流量特征,使得檢測模型能夠針對不同目標網絡中存在的不同異常行為進行檢測,適用于不同APT攻擊場景。同時,本發明利用信息增益對不同決策樹賦予權重并基于WMA得到最終檢測結果,保證了不同決策樹對模型檢測性能的影響程度不同,使得模型不再單單依賴于標準隨機森林算法中樹的棵數的選取,大大提高了模型的檢測精度。
不同規模訓練數據集對檢測性能的影響
圖8為訓練數據集D的準確率和模型的檢測率隨未標記歷史數據規模變化的曲線,這里本發明設已標記準確數據與未標記歷史數據的比例為1:d,其中d表示未標記歷史數據的規模。從圖中本發明可以看出,訓練數據集D的準確率隨d值的增大逐漸下降,而模型檢測的準確率隨d值的增大呈先增大后下降的趨勢,在d=9時達到最大值80.77%。這是由于當d值過小時,用于訓練模型的數據不足而導致模型檢測精度不高,而當d值過大時,由于生成的訓練數據集D已經不夠準確,而導致訓練出的模型自身準確率過低。因此實驗選取d=9構建訓練數據集D。
決策樹個數對檢測性能的影響
從圖9中本發明可以知道,當決策樹個數q=300時,檢測的準確率達到最高80.77%,此時模型檢測花費的時間為112s,當q值大于300時,檢測精度趨于穩定,而檢測花費時間大幅度上升,使得模型無法保證APT攻擊檢測的實時性。其中,決策樹個數q是影響模型性能和效率的一大主要因素,當決策樹個數q較小時,模型的檢測精度較差。另一方面,由于隨機森林具有不過擬合性質,因此可以使q盡量大,以保證模型的檢測精度。但是模型的復雜度與q成正比,即q過大,模型檢測時間花費過大。因此實驗選取q=300。
綜上所述,本發明在利用少量已標記準確數據集生成大規模準確標記訓練數據集的同時,提取了最能體現目標網絡流量的特征,保證了模型對未知攻擊的檢測精度。本發明針對APT環境下訓練數據集少和網絡流量特征難以選取的問題,基于半監督學習算法,利用少量已標記數據,生成大規模訓練數據集,以此對檢測模型進行訓練,并通過信息增益率的引入實現對APT目標網絡流量數據的特征提取以檢測目標網絡中的未知攻擊。通過實驗與RF、KNN和SVM算法的檢測結果對比驗證了本發明的有效性,并分別分析了不同規模訓練數據集和決策樹個數的選取對檢測性能的影響。
以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!